Kafka存储机制
Kafka之所以有那么高的吞吐量,很大程度取决于它的存储机制,一个主题可以有多个partition,每个partition有一个leader和多个副本,读写主要通过leader,副本的主要功能还是为了保证数据的安全性和保证可靠性,当某个partition的leader出现异常后,剩余副本可以选举出新的leader;每个partition下面包含多个log文件和index文件,一对log文件和index文件组成一个segment,所以也可以理解为一个partition包含多个segment,其中log文件存储的是具体数据。
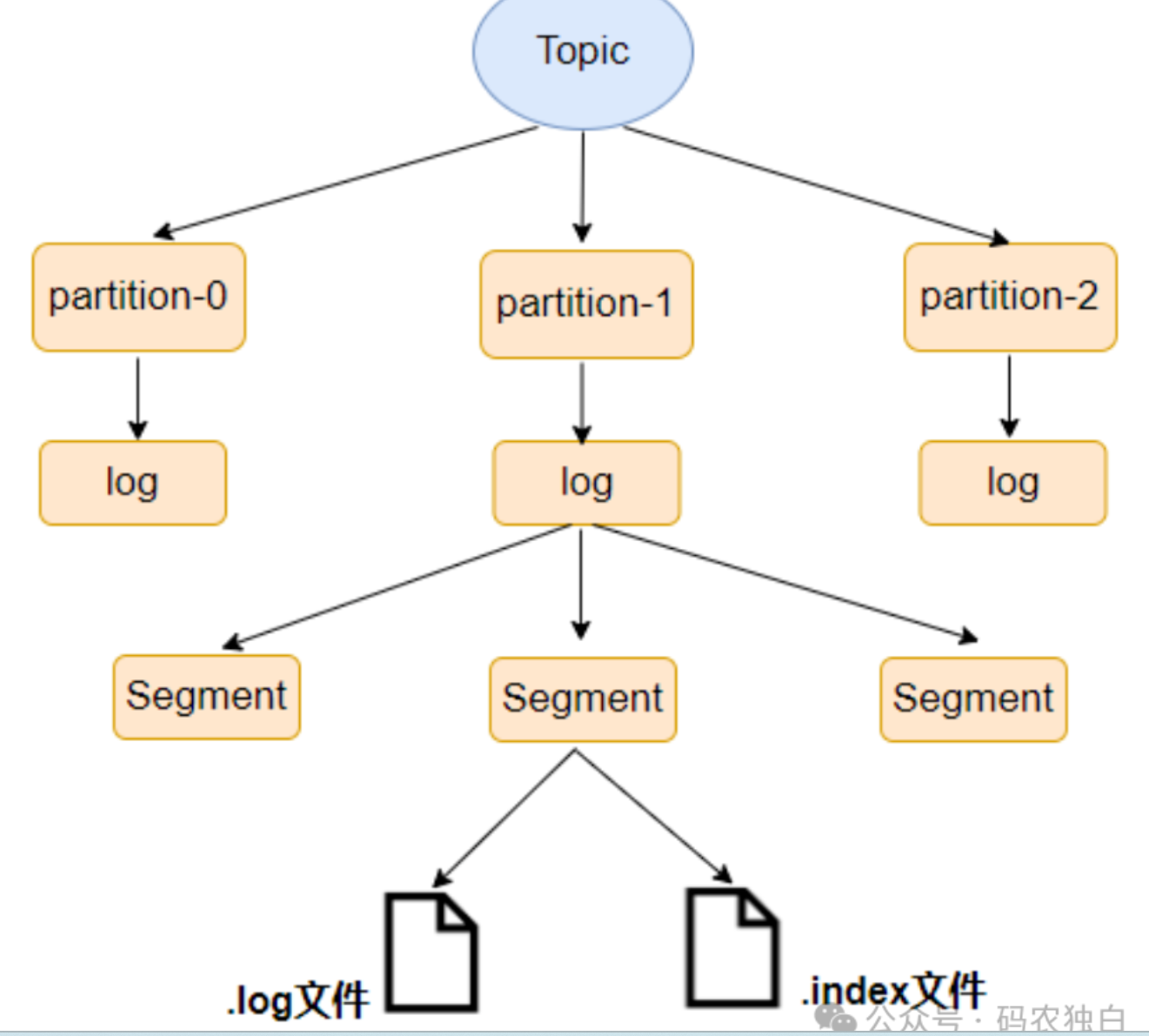
kafka消息通过offset划分为多个segment,这样一方面可以增加查询效率,另一个方面也方便按照segment进行数据删除,segment的划分可以通过配置时间定期生成一个新的,也可以配置每个segment文件大小,达到设置阀值后生成一个新的segment。索引分为全量索引和稀疏索引,区别就是一个是部分数据有索引,减少索引的存储量。

Kafka采用的是稀疏索引,索引文件里面就两列,一列存offset,另一列存position,比如(3,555)表示这个文件的第三条,在这个文件的第555个字节开始,通过二分查找可以很快的定位到文件。
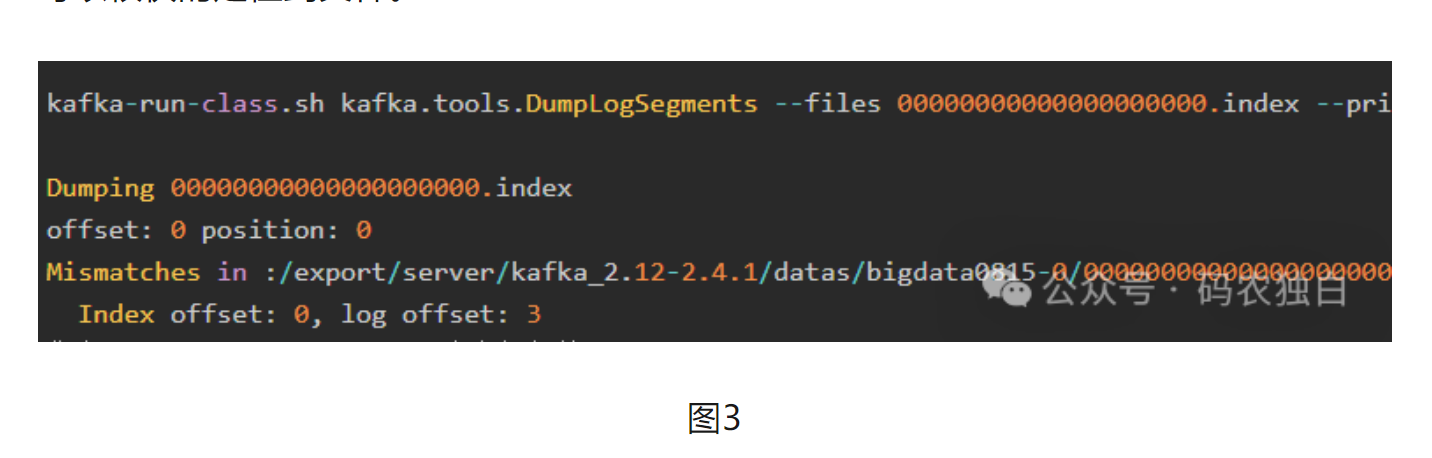
其中消息的存储格式如下图4、图5




 浙公网安备 33010602011771号
浙公网安备 33010602011771号