Hive数据线下导入Mysql
1.背景
最近在处理一个数据量级在1亿左右的数据,没办法mysql不好处理,只能把数据放到大数据集群进行处理,处理好后再把这亿级数据导入本地Mysql。
2.实践
(1)把需要处理的数据手动传到集群,上传的数据只有一万条左右,经过笛卡尔积以及各种运算后,结果数据条数有一亿左右,文件大小有5G左右。
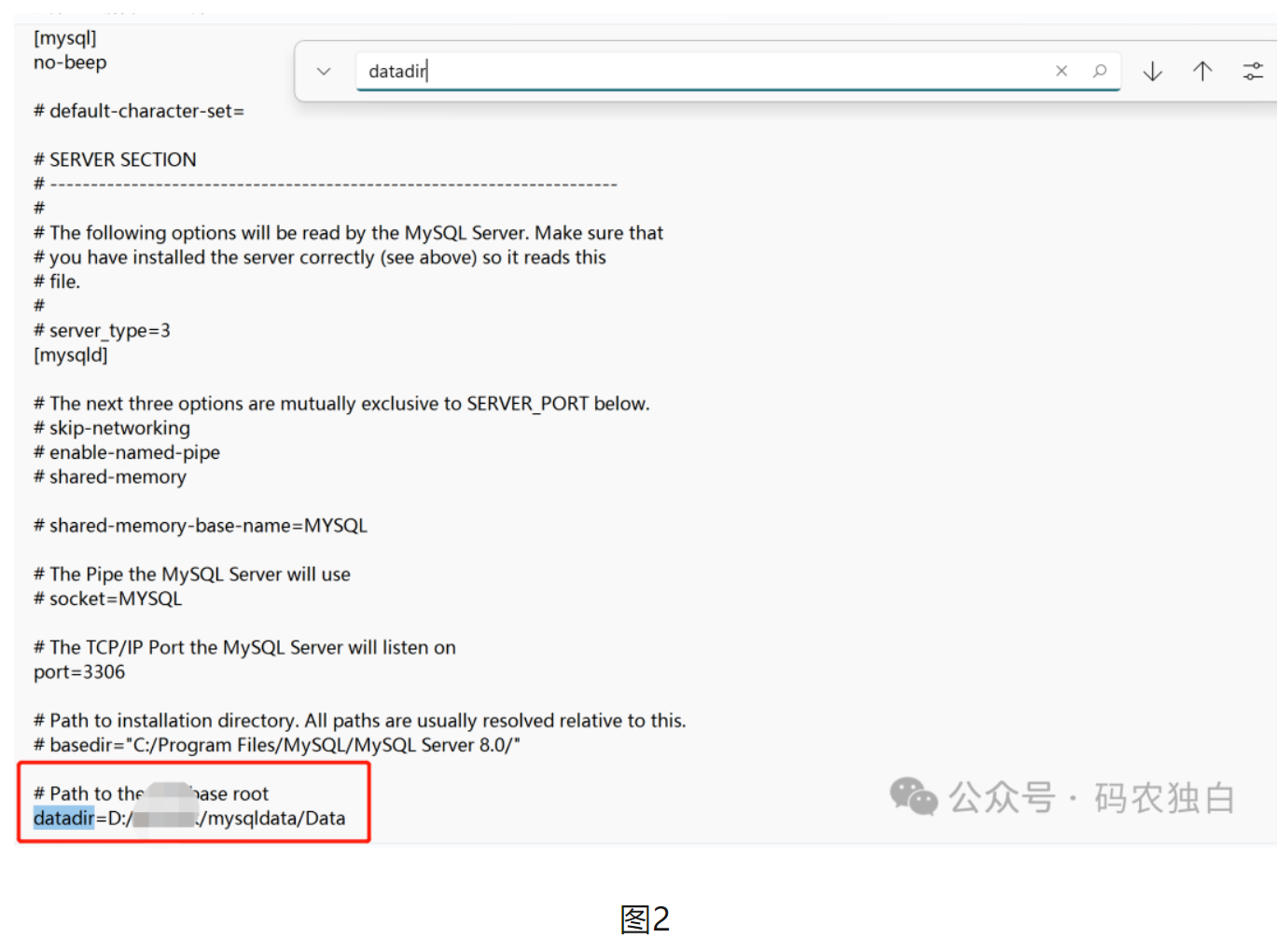
(2)由于本地电脑的mysql是安装到c盘的,为了减小系统盘压力,只能把数据迁移到其他目录。首先通过services.msc打开mysq服务,找到mysql的存储目录,然后修改my.ini里面配置的存储路径,注意在windows系统,这个斜杠要反过来/。同时把该级目录里面的Data目录下的所有文件拷贝到目标目录,然后再启动mysql,注意一定要把数据文件拷贝过去了再重启,不然重启会失败哦。
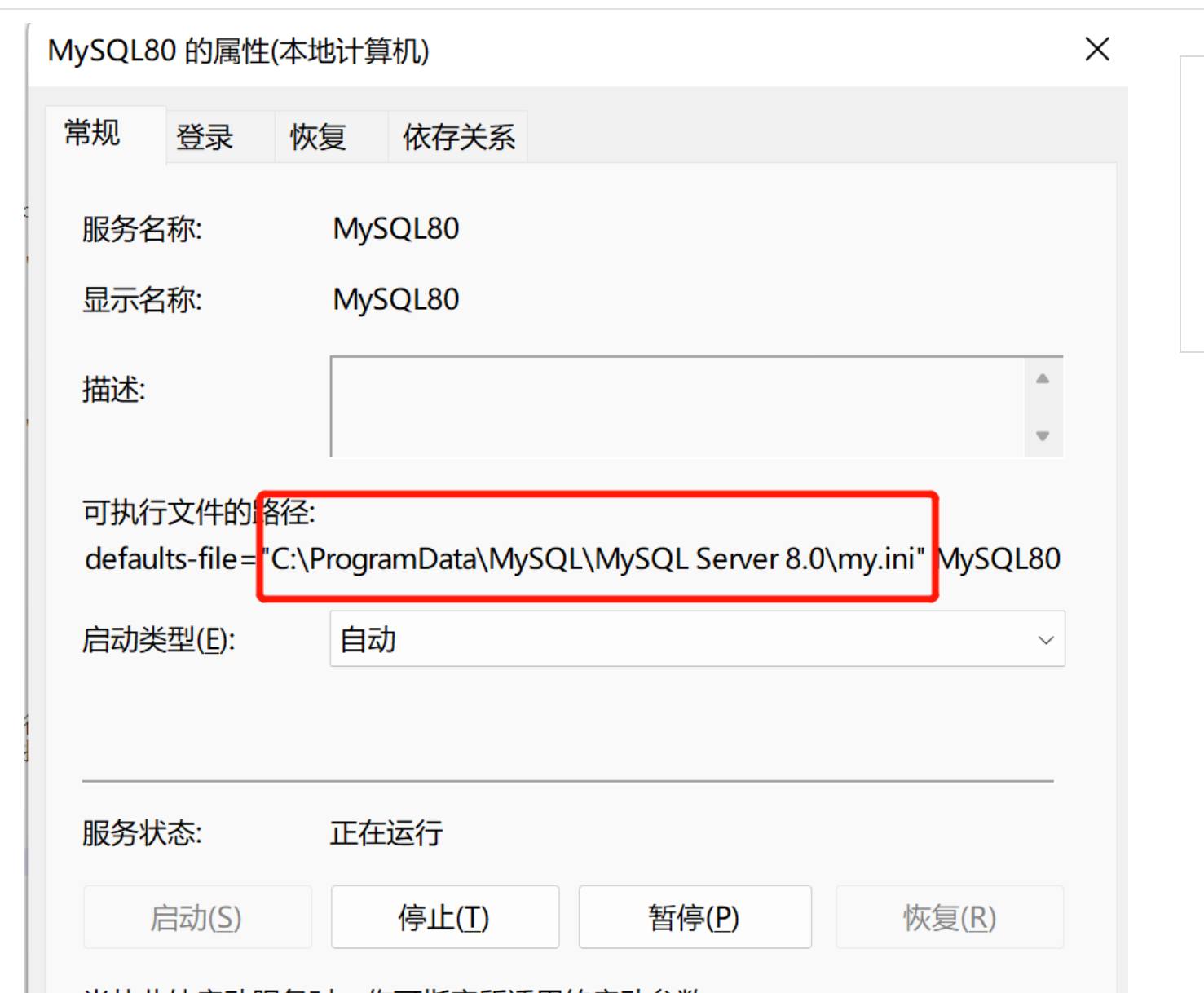
图1
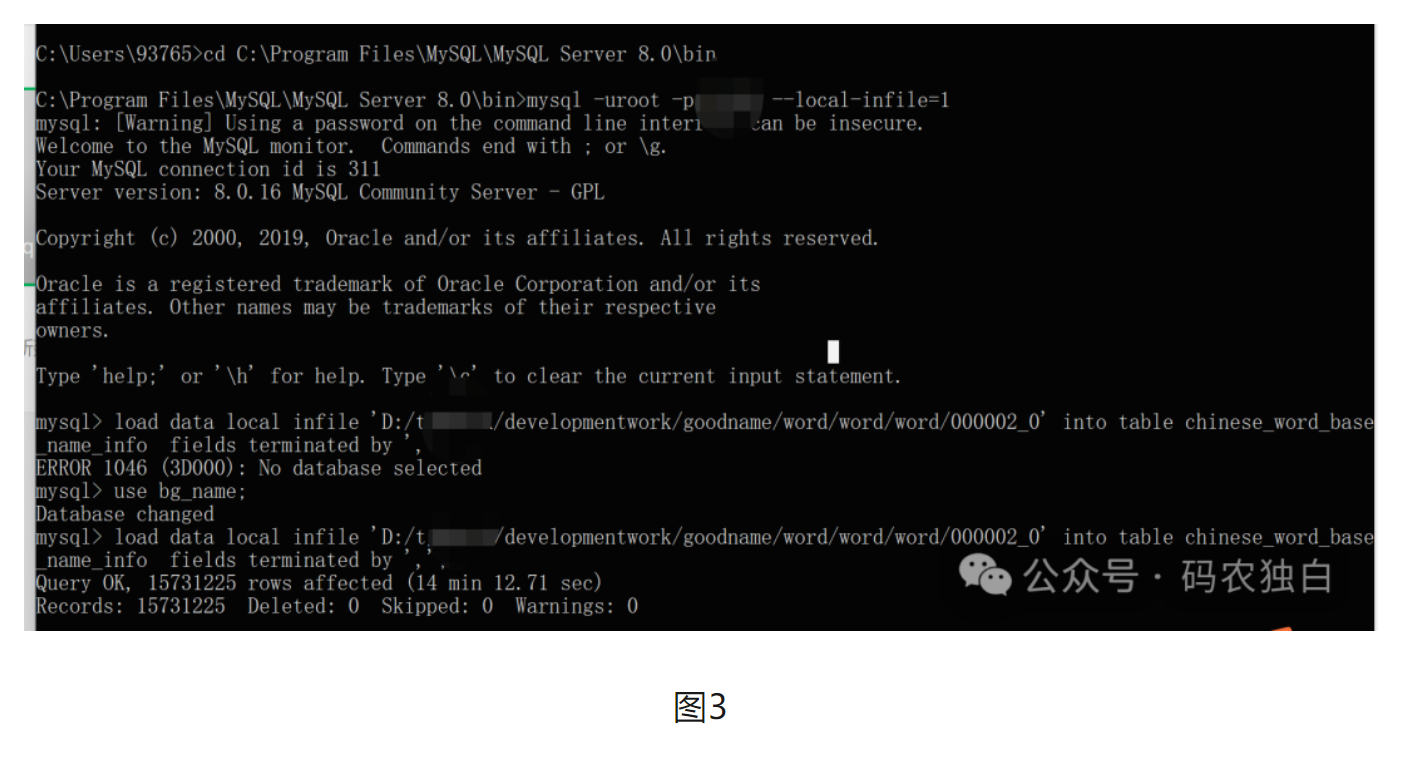
(3)通过hadoop dfs -get /xxx把hdfs文件拿到服务器下,然后从服务器上把文件下载到本地,再根据图1的路径执行mysql -uroot -pxxxx --local-infile=1从而打开mysql命令的执行终端,最后执行如下命令把数据导入mysql。
load data local infile 'D:/developmentwork/goodname/word/word/word/000002_0' into table chinese_word_base_name_info fields terminated by ',';


 浙公网安备 33010602011771号
浙公网安备 33010602011771号