本地测试Spark的逻辑回归算法
本地小数据量测试了一下Spark的LogisticRegressionWithSGD算法,效果不尽如人意。
数据样例如下,竖杠前的0,1代表两种类型,后面逗号隔开的是两个特征,两个特征只要有一个大于等于0.6就会被分为1这一类,否则就是0。
1|0.3,0.6 0|0.2,0.1 1|0.5,0.6 1|0.8,0.3 0|0.4,0.3 0|0.3,0.4 0|0.3,0.1 0|0.3,0.2 0|0.1,0.4 1|0.3,0.7 1|0.8,0.2 1|0.9,0.1 0|0.2,0.1 0|0.25,0.11
代码如下:
import org.apache.spark.mllib.classification.LogisticRegressionWithSGD
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.{SparkConf, SparkContext}
object TestLogisticsAlgorithm {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("test").set("spark.testing.memory", "2147480000")
val sparkContext = new SparkContext(sparkConf)
val trainData = sparkContext.textFile("file:///D:\\var\\11.txt")
val modelData = trainData.map(line => {
println(line)
val tmpData = line.split("\\|")
//val tmpV:Vector=
LabeledPoint(tmpData(0).toDouble,Vectors.dense(tmpData(1).split("\\,").map(_.toDouble)))
}).cache()
val model = LogisticRegressionWithSGD.train(modelData, 200)
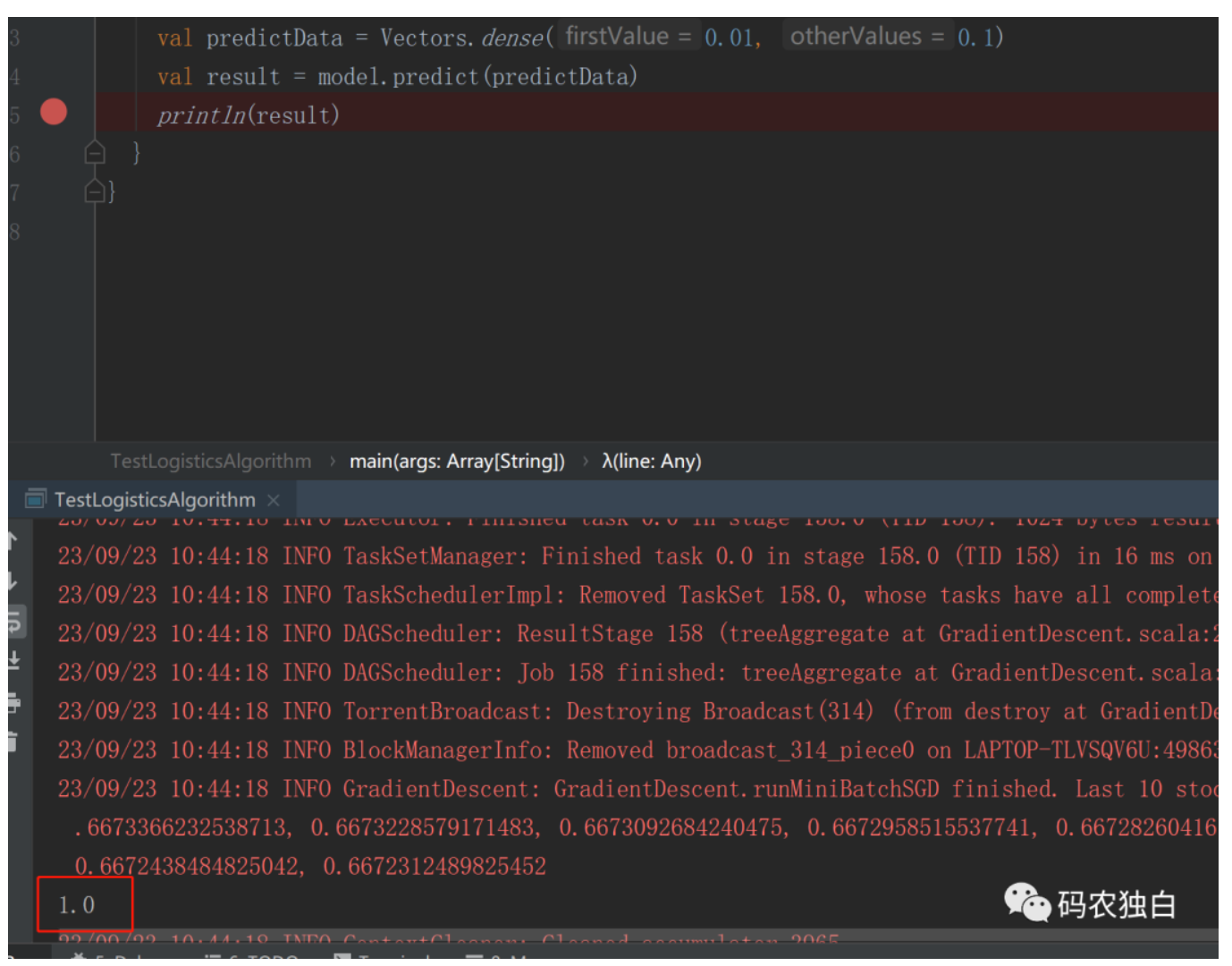
val predictData = Vectors.dense(0.01, 0.1)
val result = model.predict(predictData)
println(result)
}
}
输出效果为1,理想效果应该是0,如下图:
关注公众号了解更多:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号