自定义HiveHook
1.背景
采用华为的DGC+MRS套件,目前两套系统没有彻底打通,所以对SQL资源占用情况不够详细,无法清晰知道哪段脚本(或者表)长时间占用大量计算资源。所以需要搞一个中间系统把DGC和MRS关联起来。
2.方法
计划采用HiveHook的方式把所有的SQL提交内容记录下来存储到HDFS,尤其是query_id,这里的query_id可以和yarn的application_id关联起来。然后再通过yarn application -list获取到相应的应用对应的资源,每隔1分钟统计一次,就可以实现统计出每段SQL里面的表生成的资源占用情况。
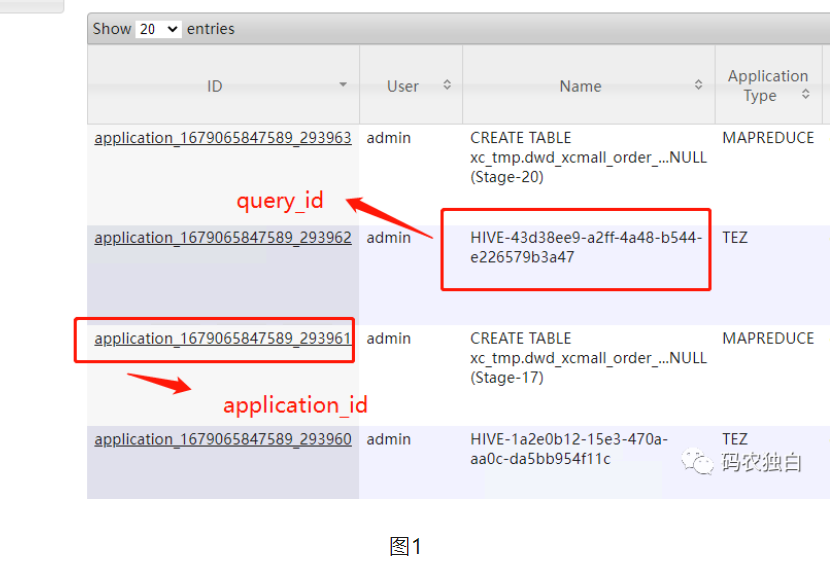
3.实施步骤
1.代码搞好后,就进行打包,注意hive和hdfs相关包可以不打进去,集群里面有相关包,如果打进去的包跟集群不一致,容易冲突,包打好后上传到一个HDFS目录,比如图2.
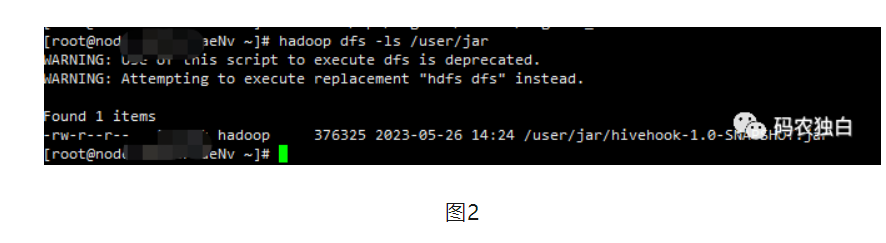
2.开始测试HiveHook,执行beeline命令,然后执行如下两个命令
add jar hdfs://hacluster/user/jar/hivehook-1.0-SNAPSHOT.jarset hive.exec.pre.hooks=com.bg.hivehook.SqlHook;
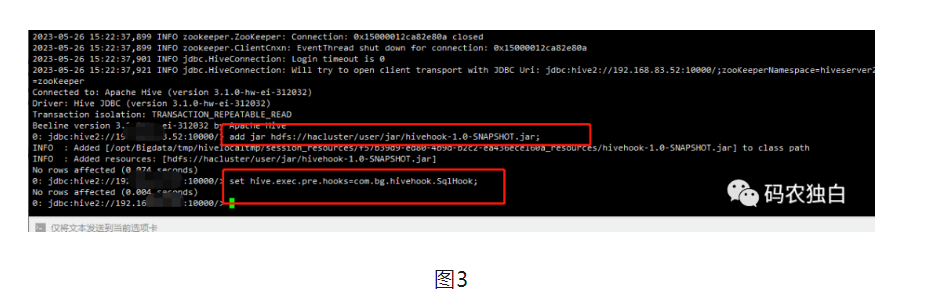
3.随意执行一些SQL,然后查询hdfs里面是否把相关提交的sql内容记录下来。

4.第一步成功了,后面关联application_id和query_id的操作下次分享。
具体代码可以关注公众号,看《自定义HiveHook》进行获取


 浙公网安备 33010602011771号
浙公网安备 33010602011771号