Hudi了解
1.数据库引擎初识
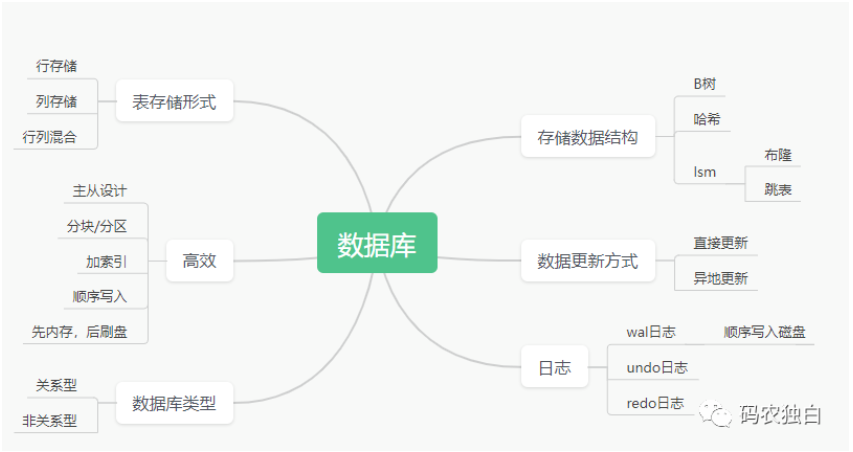
数据引擎大致包含数据结构、存储形式、数据关系、数据更新方式、高效增删改查、日志,围绕这几个方面进行相应权重处理,得到不一样的效果,内容可以整理为如下图:
2.Hudi了解
Hudi提供两种读写方式,一种读时合并,另一种是写时复制,简单的说就是充分利用顺序写,然后加上相关索引等机制,实现快速的批量读写。
Hudi表映射为文件结构如下:
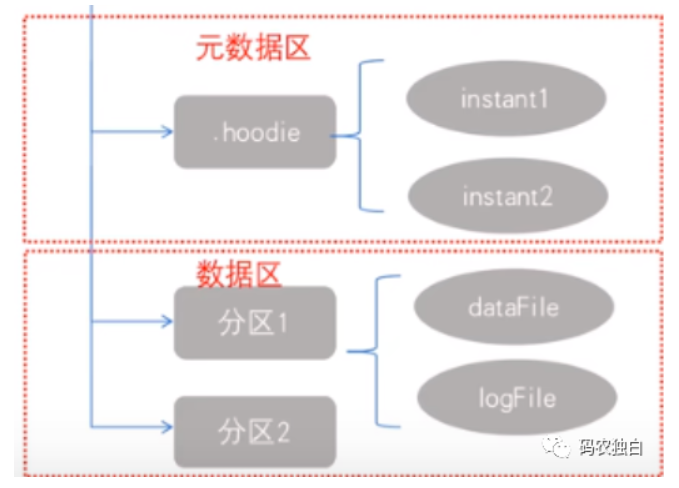
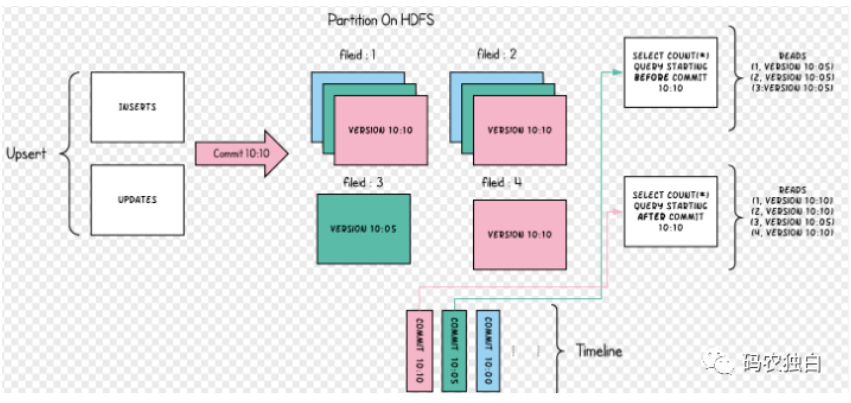
Hoodie文件通过索引机制会记录所有的主键跟文件ID的映射关系,从而提高高效的Upsert,针对写时复制就是当有数据写入时,快速找到数据所属文件块从中找到未修改的数据并复制到内存,然后和修改的数据合并到一起生成新的文件块,最后把新的文件块写回去,这种操作会导致写放大,但是适合分析工作,所以该模式适合读取密集型操作。cow的工作原理图如下:
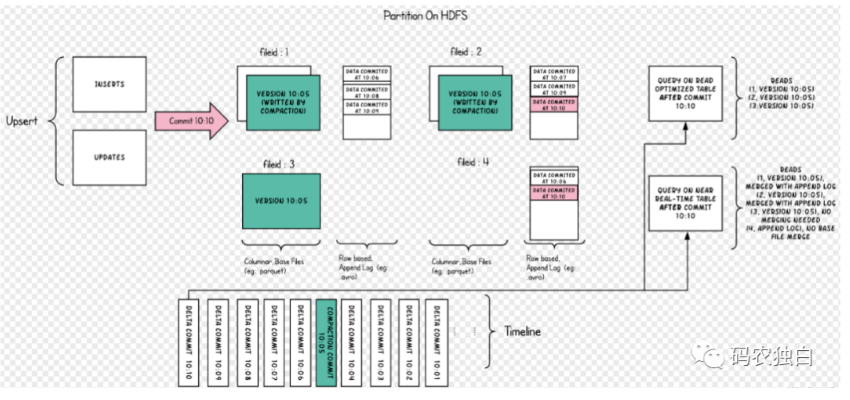
读时合并使用列式存储(parquet)+行式文件(arvo)存储数据,增量数据会按照arvo写入,每次查询需要查询出增量数据和base文件里面的数据最后合并输出。MOR的工作原理如下:
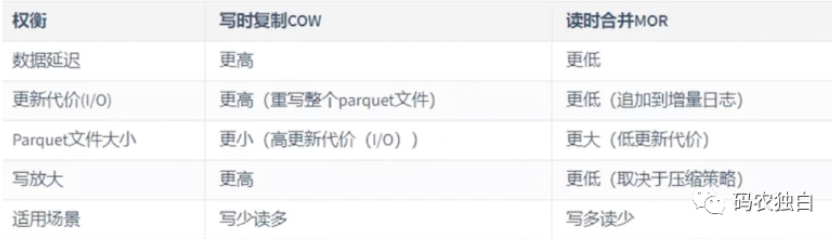
以下是两种表类型的区别:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号