调整Hive表默认格式为ORC踩坑
由于集群Hive默认使用的存储格式为text,为了节省硬盘资源,因此需要对之前的脚本进行改造,最快捷的方式就是在脚本最前面加set hive.default.fileformat=orc,经过测试这个命令确实生效了,很多脚本也运行成功,但是有的脚本在计算的中间过程中会报错,这次针对报错的脚本来解析一下。
1.错误定位
脚本内容如下截图1,两个中间表是orc格式,就这样关联查询的时候会报错,经过定位,是这个里面的case when这里报错,这里的out_points is null和is not null两个条件同时判断时就会报错,只存在一个就不会报错。

图1
2.错误分析
查看日志,报错内容如下图2,看到vector,猜测是因为开启了向量导致的,于是关闭向量,在脚本前加上set hive.vectorized.execution.enabled = false居然执行成功了,说明一条一条的执行判断,然后写入不会报错。
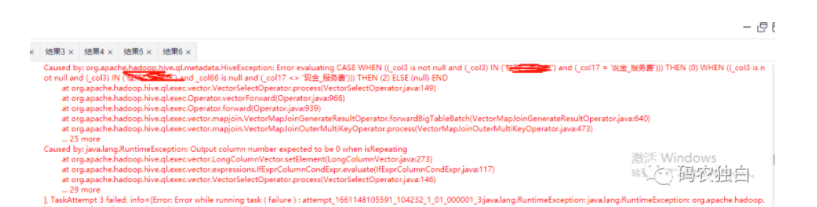
图2
那么反过来,为啥开启了向量就报错了,开启向量一次性会拿1024条进行批量处理,仔细看报错日志里面有一条关于类型转换错误的信息,如下图3

图3
接上,难道是因为批量处理的数据有的被判断为long有的被判断为double,导致无法进行数据转换,从而无法写入报错,尝试着加引号,居然也执行成功了,修改的方式如下截图4。
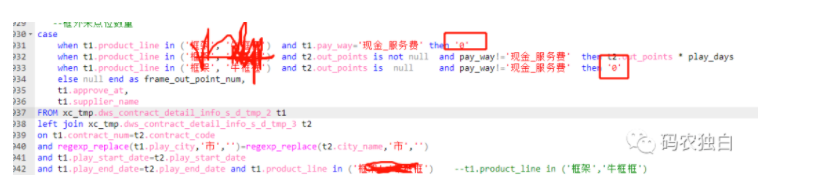
图4
3.总结
开启向量化时要注意明确数据类型,否则可能会报类型转换失败的错误。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号