
Flink中的水印如何使用
Flink是处理实时数据的利器,但是由于网络抖动导致数据乱序或者数据写入Kafka后写入了不同分区,消费者消费时导致数据先后乱序等,为了解决这样的问题,Flink引人水印加上窗口使乱序数据落入同一个窗口然后进行处理,从而解决乱序问题。
一.水印时间选择
Flink里面的时间分为事件时间,摄入时间,处理时间。
事件时间:业务数据实际发生的时间。
摄入时间:到底Flink系统的时间。
处理时间:Flink接收到数据开始处理的时间。
二.水印类型
水印分为周期性水印和打点水印。
周期水印:通过ExecutionConfig.setAutoWatermarkInterval()进行设置多久产生一个水印,默认是每隔200ms产生一个水印,可以通过AssignerWithPeriodicWatermarks进行重写,当然也可以用BoundedOutOfOrdernessTimestampExtractor进行自定义。
打点水印:依赖事件本身的属性进行触发水印产生,这种使用较少并且Flink没有内置实现,只能通过重写AssignerWithPunctuatedWatermarks的方法进行定义。
三.水印使用例子
Flink通过assignTimestampsAndWatermarks()来提取事件时间和产生水印,下图中主要使用周期性产生水印和采用处理时间作为水印时间。
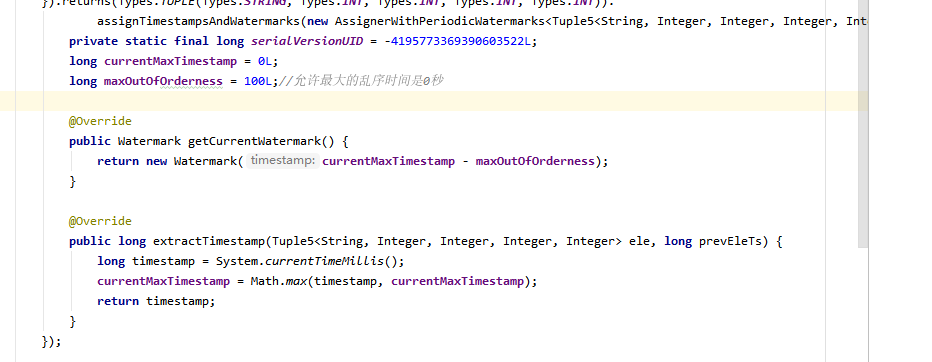
注意:
1.水印的产生不能过于频繁,否则会很消耗内存,水印的生成要尽量早,越早生成离事件时间越近,最好在source后就生成。
2.如果业务方对事件时间不关心,那么使用处理时间是最方便的。
后续文章会说一下Flink的侧数据分流机制以及窗口延迟机制。
想了解交流更多大数据及java知识,关注公众号《码农独白》:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号