
windows环境开发spark及flink环境配置
1.本地开发环境安装
1..本地添加如下映射(windows地址:C:\Windows\System32\drivers\etc)
192.168.83.48 node-master1pZiu
192.168.83.158 node-str-coreHikL
192.168.83.174 node-str-coreJHEU
192.168.83.193 node-str-corekYpN
192.168.83.82 node-ana-coreQVZK
192.168.83.244 node-ana-coreYEsq
192.168.83.197 node-ana-coreZJhf
2.本地配置环境变量HAOOP_HOME,需要下载hadoop相关配置,下载路径:
https://github.com/SirMin/winutils
3.scala使用2.11版本,自行下载,下载地址:https://www.scala-lang.org/download/
4.idea怎么配制这里不再描述
2.代码例子
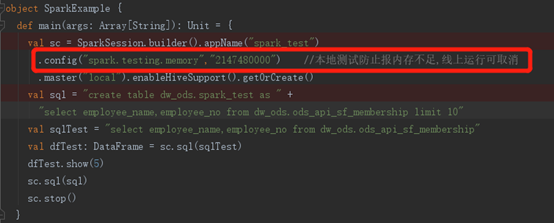
1.scala代码本地调试例子
3.打包部署
1.直接使用maven clean install
2.上传jar包执行,spark运行例子(注意如果代码里面写了master为local需要取消,spark2-submit可不取消,华为mrs2.1.0上面运行需要取消),然后运行命令大致如下,参数根据需要调整即可。
spark2-submit \
--class com.xxx.maintaintablename.MaintainTableNameApplication \
--master yarn\
--queue 'root.dw' \
--deploy-mode cluster \
--num-executors 10 \
--executor-cores 3 \
--executor-memory 8g \
--driver-cores 3 \
--driver-memory 8g \
--conf spark.cores.max=24 \
MaintainTableName.jar
3.flink使用yarn-session运行,首先确认是否已经有yarn-session在运行,如果没有就先执行yarn-session.sh -d -n 4 -nm crm_app -jm 1024 -tm 4096,然后执行类似如下命令flink run -c com.xc.flink_dw.main.crm.CrmMainBusinessSupporter ./flink_dw-1.0-SNAPSHOT-jar-with-dependencies.jar进行启动。
4.如果是yarn-cluster执行,直接执行flink run -m yarn-cluster -c com.xc.flink_dw.main.crm.CrmMain flink_dw-1.0-SNAPSHOT-jar-with-dependencies.jar即可
5.最后yarn管理界面查看即可
flink和spark例子关注公众号码农独白获取


 浙公网安备 33010602011771号
浙公网安备 33010602011771号