
基于Livy的Spark提交平台搭建与开发
为了方便使用Spark的同学提交任务以及加强任务管理等原因,经调研采用Livy比较靠谱,下图大致罗列一下几种提交平台的差别。

本文会以基于mac的单机环境搭建一套Spark+Livy+Hadoop来展示如何提交任务运行,本文只针对框架能够运行起来,至于各个组件参数怎么配置性能更好,各位兄弟就自行找度娘了。
一.搭建Spark
访问http://spark.apache.org/downloads.html下载安装包,然后按照以下步骤操作即可。
1.下载完成后解压到某个目录下,在该目录执行以下命令
tar zxvf spark-2.1.0-hadoop2.7.tgz
2.配置Spark环境变量
Mac环境变量一般在/etc/profile下配置,打开profile文件在文件中添加。
#SPARK VARIABLES START
export SPARK_HOME =/usr/local/spark-2.1.0-hadoop2.7
export PATH = ${PATH}:${SPARK_HOME}/bin
#SPARK VARIABLES END
3.配置Java环境
同样在/etc/profile下配置。在此之前已经安装scala和jdk相关环境。将java安装目录添加到里面export JAVA_HOME =/Library/java/javaVirtualMachines/jdk1.8.0_111.jdk/COntents/Home 设置完成后,保存退出,最后使用source /etc/profile 使环境变量生效。
4.执行sbin/start-all.sh,启动spark
5.测试
打开终端,输入pyspark,出现下面的画面即表示安装成功。
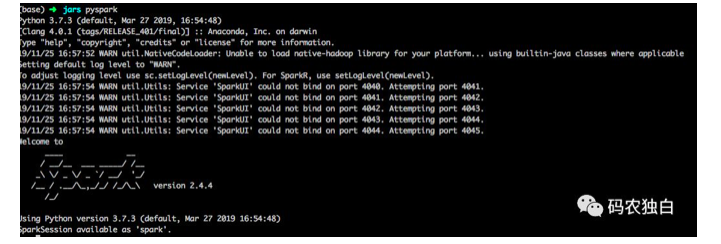
二.Livy安装
1.去https://www.apache.org/dyn/closer.lua/incubator/livy/0.6.0-incubating/apache-livy-0.6.0-incubating-bin.zip下载安装包。
2.解压安装包,并且编辑livy.conf,添加红框中的参数即可。

然后编辑livy-env.sh,添加Spark的安装目录配置。
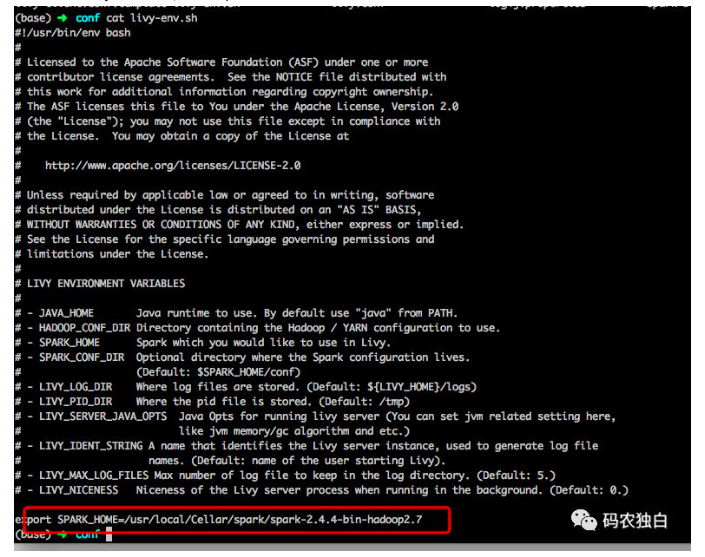
3.最后bin/livy-server start启动Livy即可
三.Hadoop安装
1.去https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/下载安装包,并解压
2.修改各种配置,vim core-site.xml,修改为
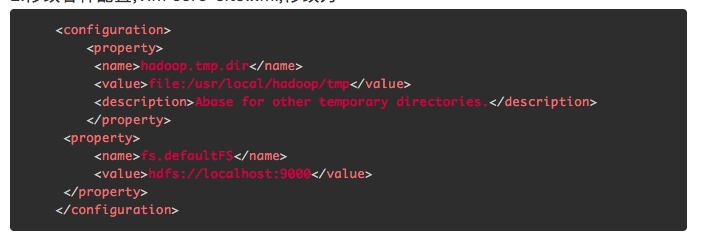
修改hdfs-site.xml为

3.配置环境变量
export HADOOP_HOME=/User/deploy/software/hadoop/hadoop-2.8.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
4.格式化节点

5.执行sbin/start-all.sh启动Hadoop,出现以下界面说明安装成功
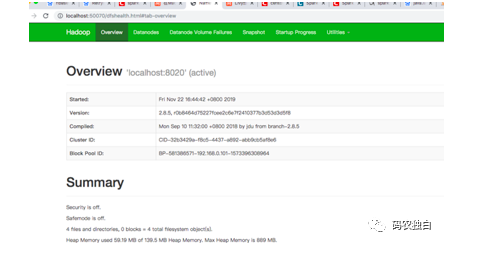
yarn和hadoop安装是一体的,访问判断yarn是否安装成功

6.如果datanode没有启动成功,就去配置的NameNode下的current/VERSION中的clusterID复制到DataNode下的VERSION即可。
四.开发代码提交任务
通过上面的步骤基础环境就已经搭建好,接着就是开发接口提交任务。部分代码截图如下:


五.关注公众号获取源码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号