2017-2018-1 20155214 《信息安全系统设计基础》第14周学习总结
2017-2018-1 20155214 《信息安全系统设计基础》第14周学习总结
教材第5章学习内容总结
我们描述许多提高代码性能的技术。理想的情况是编译器能够接受我们编写的任何代码并产生尽可能高效的、具有指定行为的机器级程序现代编译器采用了复杂的分析和优化方式而且变得越来越好,然而即使是最好的编译器也受到了妨碍优化因素的阻碍。程序员必须编写容易优化的代码,帮助编译器。
总结本章新收获
- 5.1 优化编译器的能力和局限性
在只执行安全的优化中编译器必须假设不同的指针可能会指向内存中的同一个位置。
两个指针可能指向一个内存位置称为 内存别名使用
void twiddle1(long *xp,long *yp){
*xp += *yp;
*xp += *yp;
}
当考虑指针 *xp 和 *yp 指向相同内存地址时,该函数可能产生二义性,及xp值翻了4倍
当函数修改全局变量等 副作用 时,可能会妨碍优化。
那么
long counter = 0;
long func1opt(){
long t = 4 * counter + 6;
counter += 4;
return t;
}
通过内联替换函数调用
显然优于
long func1in(){
long t = counter++;
t += counter++;
t += counter++;
t += counter++;
return t;
}
- 每元素的周期数CPE
void psum2(float a[],float p[],long n)
{
long i;
p[0] = a[0];
for(i = 1;i < n-1;i += 2){
float mid_val =p[i-1] + a[i];
p[i] = mid_val;
p[i+1] = mid_val + a[i+1];
}
if(i < n)
p[i] = p[i-1] + a[i];
}
当使用for循环迭代计算前置和。每次调用函数都会执行建立栈帧和恢复栈帧,这一段代码的耗时是一个定值S。随着循环次数n的变化,总的耗时T=S + n*L,其中L为for循环的单位循环执行时间,在本书中又称作每元素周期数CPE。
上述代码的运行时间近似于 368+6.0n ,因此psum2的CPE为6.0。
- 未经优化的代码是从C到机器代码的直接翻译,通常效率明显较低。简单地使用 -O1 ,就会进行基本的优化。显著地提升程序性能。
- 通过移动要执行多次但是计算结果不会改变的计算,称为代码移动。可以帮助编译器进行优化。
void combine4(vec_ptr v,data_t *dest){
long i;
long length = vec_length(v);
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for(i = 0;i < length;i++){
acc = acc + data[i];
}
*dest = acc;
}
通过将循环中的累计结果放在临时的局部变量中,可以消除每次循环迭代不必要的内存读写
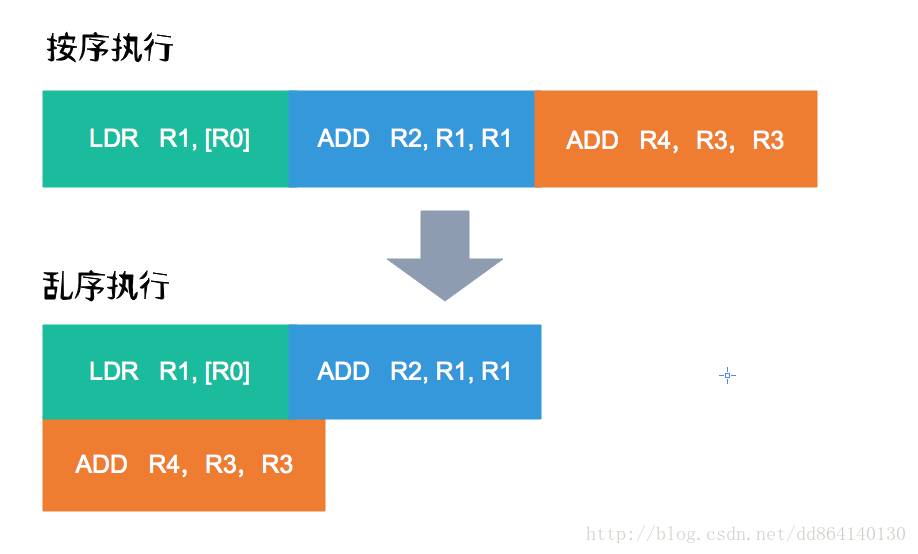
- 乱序处理
目前的高级处理器,为了提高内部逻辑元件的利用率以提高运行速度,通常会采用多指令发射、乱序执行等各种措施。现在普遍使用的一些超标量处理器通常能够在一个指令周期内并发执行多条指令。
从编译器的角度来看,编译器能够对很大一个范围的代码进行分析,能够从更大的范围内分辨出可以并发的指令,并将其尽量靠近排列让处理器更容易预取和并发执行,充分利用处理器的乱序并发功能。所以现代的高性能编译器在目标码优化上都具备对指令进行乱序优化的能力。并且可以对访存的指令进行进一步的乱序,减少逻辑上不必要的访存,以及尽量提高 Cache命中率和CPU的LSU(load/store unit)的工作效率。所以在打开编译器优化以后,看到生成的汇编码并不严格按照代码的逻辑顺序是正常的。
- 5.8循环展开
如果计算循环索引和测试循环条件的循环开销部分所占比重过大,这时就可以考虑使用一种被称作"循环展开"的方式来优化代码。所谓循环展开就是通过在每次迭代中执行更多的数据操作来减小循环开销的影响。其基本思想是设法把操作对象线性化,并且在一次迭代中访问线性数据中的一小组而非单独的某个。这样得到的程序将执行更少的迭代次数,于是循环开销就被有效地降低了。
循环展开技术的好处在于它能减小循环开销的影响。但它也不是没有缺点的,天下没有免费的午餐!首先,循环展开增加了生成的目标代码的数量,这很容易理解,因为循环体在源代码级别就已经变得庞大。读者可以试想它们被翻译成目标代码时的情况。为了验证这一点,读者可以使用Visual C++来对比使用循环展开前后循环体的汇编代码的长度,验证结果将表明循环展开对目标代码的长度的确有很大的影响。当然,在我们所举的例子中,循环展开所要付出的代价都是比较小的。当然这并不能概括其他所有的情况,因此这个空间换时间的折中最优位置还需要针对具体问题来做具体的分析。 使用循环展开时一方面要考虑实际待处理数组的长度,并由此选择一个较好的展开度;另一方面要综合考虑这个展开度对时空开销比例的影响,在尽量不会使目标代码空间消耗激增的前提下获得最高的时间收益。另外,也可以让编译器为我们完成这些工作。通常,编译器可以很容易地执行循环展开,但这需要设定其优化级别足够高,所以程序员也可以选择让编译器来完成这个工作。当然,我们曾经提醒过读者,在开发阶段并不适合将优化级别设置得过高,因此如果你希望让编译器执行循环展开,那么最好等到软件开发完成之后。
for(i=0;i<limit;i+=2){
acc = (acc OP data[i]) OP data[i+1];
}
通过减少循环次数,减少关键路径上的操作数量。
- 重新结合变换
for(i=0;i<limit;i+=2){
acc = acc OP (data[i] OP data[i+1]);
}
通过重新结合变换,提高程序并行性。
结对学习搭档讲解问题
- 什么是amdahl定律?
想要大幅提高整个系统的速度,必须提高整个系统很大一部分的速度。取决于这个部分有多么重要和速度提高了多少。
- 编写高效程序需要几类活动?
- 必须选择一组合适的算法和数据结构;
- 必须编写出编译器能有效优化以转换成高效可执行代码的源代码。
- 针对处理运算量特别大的计算,将一个任务分成多个部分,这些部分可以在 多核和多处理器的某种组合上并行地计算。
结对学习搭档链接
博客园链接:http://www.cnblogs.com/LeeX1997/
结对学习照片
其他(感悟、思考等,可选)
通过本周的再次学习,让我对于如何编写高效代码有了进一步理解。
更重要的是,对于 高级语言-编译器-处理器 之间的关系更明确了。

