


20199303 2019-2020-2 《网络攻防实践》综合实践


简述
深度神经网络近年来取得了巨大的成功,因为它在一些极具挑战性的问题上取得了突破。训练这些网络在成本上无疑是昂贵的,并且需要大量的训练数据。因此,出售这种预先训练好网络参数模型可以成为一种有利可图的商业模式。不幸的是,一旦模型被出售,它们很容易被复制和散播。为了避免这种情况,有必要使用跟踪机制确保模型的归属可查。在这项工作中,本文提出了一种给神经网络加水印的黑盒算法。该方案适用于一般的分类任务,并可以很容易地与现有的学习算法相结合。实验表明,该水印对模型设计的主要任务没有明显影响,并评估了其对多种实际攻击的鲁棒性。
深度神经网络(CNN)使得从视觉理解到机器翻译到语音识别的越来越多的应用场景成为可能。这些技术极大地改变了我们构思软件的方式,并正迅速成为一种通用技术。目前深度学习技术的广泛流行主要可以归因于两点。第一,一些开源框架(例如PyTorch、TensorFlow)简化了复杂模型的设计和部署过程。第二,学术界和工业界定期发布开源的、最先进的、预先训练过的模型。例如,最精确的视觉理解系统现在可以在线免费下载。考虑到有效地训练这些模型需要大量的专业知识、数据和计算资源,预先训练过的模型的可用性使得程序员可以用有限的资源来调配它们。
深度神经网络的有效性和简单的调优过程相结合,开启了机器学习服务(MLaaS)的新市场。在这个快速增长的领域,有些经营此领域的公司提出:训练和调整给定客户的模型的成本可以忽略不计,相比之下,如果客户自己训练神经网络,所需的硬件的价格往往开支较多。通常,客户可以进一步微调模型以提高其性能,因为有更多的数据可用。除了开源模型之外,MLaaS还允许用户在不增加太多开销的情况下构建更加个性化的系统。
尽管这个过程非常简单,但它带来了一定的安全和法律问题。服务提供商可能会担心,购买深度学习网络模型的客户可能会在许可协议条款之外散布该网络,甚至将该模型出售给其他客户,从而威胁到其业务。
本文的主要贡献
1.利用神经网络的过度参数化设计了一种鲁棒的加水印算法
2.提出了从水印进行加密建模的任务和神经网络的后门任务,并证明了前者可以由后者以黑箱方式构造
技术难点
现有的水印技术不能直接适用在神经网络这种特殊情况,这是本文要解决的任务。实际上,设计一个鲁棒的加水印的神经网络被一些现实问题所困扰:人们可以稍微调整一个模型来修改它的参数,同时模型的性能基本不受影响。这使得最直接的解决方案,例如使用基于权重矩阵的简单哈希函数,变得不再适用。
机器学习与分类问题
所谓图像分类问题,就是已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。
著名的图像分类挑战:ILSVRC,全称是ImageNet Large-Scale Visual Recognition Challenge,平常说的ImageNet比赛指的是这个比赛,拥有是一个超过15 million的图像数据集。自ILSVRC从2010年开始举办,到2017年是最后一届,出现了许多优秀的网络模型,是如今AI井喷式发展的重要原因。
在这个比赛中,出现了许多优秀的网络模型。我们从中挑选了一些,和最新锐的模型,在cifar10数据集上对比准确率。

图像分类的任务,就是对于一个给定的图像,预测它属于的那个分类标签(或者给出属于一系列不同标签的可能性)。图像是3维数组,数组元素是取值范围从0到255的整数。数组的尺寸是宽度x高度x3,其中这个3代表的是红、绿和蓝3个颜色通道。
困难和挑战:在下面列举了计算机视觉算法在图像识别方面遇到的一些困难,要记住图像是以3维数组来表示的,数组中的元素是亮度值。
• 视角变化(Viewpoint variation):同一个物体,摄像机可以从多个角度来展现。
• 大小变化(Scale variation):物体可视的大小通常是会变化的(不仅是在图片中,在真实世界中大小也是变化的)。
• 形变(Deformation):很多东西的形状并非一成不变,会有很大变化。
• 遮挡(Occlusion):目标物体可能被挡住。有时候只有物体的一小部分(可以小到几个像素)是可见的。
• 光照条件(Illumination conditions):在像素层面上,光照的影响非常大。
• 背景干扰(Background clutter):物体可能混入背景之中,使之难以被辨认。
• 类内差异(Intra-class variation):一类物体的个体之间的外形差异很大,比如椅子。这一类物体有许多不同的对象,每个都有自己的外形。
面对以上所有变化及其组合,好的图像分类模型能够在维持分类结论稳定的同时,保持对类间差异足够敏感。
常用的图像分类的神经网络为:
(1)VGG
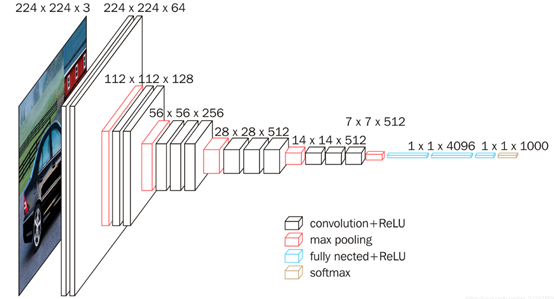
VGG是Oxford的Visual Geometry Group的组提出的。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
(2)ResNet
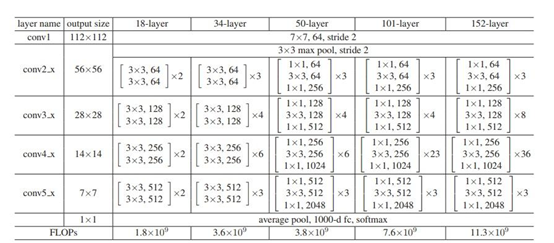
从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果。但是更深的网络其性能一定会更好吗?实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这不会是过拟合问题,我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
残差网络ResNet就是为超深网络的退化问题研究的模型。ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
(3)EfficientNet
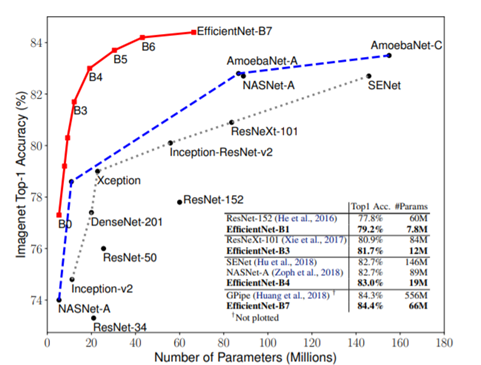
EfficientNet是Google Research 发表在ICML 2019的工作。EfficientNet根据网络从小到大,分为了B0到B7共8个网络,其中EfficientNet-B0尺寸最小,速度最快,精度相对最低;EfficientNet-B7尺寸最大,精度最高,速度也相对最慢。
(4)RegNet
虽然EfficientNet相比经典模型取得了不小的优势,但是却因为其庞大的模型参数,对于小型实验室难以调试。
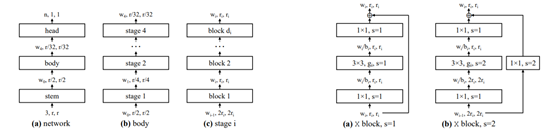
2020CVPR,ResNet的发明者何凯明提出了一种优秀的网络结构,在类似的条件下,性能还要优于EfficientNet,在GPU上的速度还提高了5倍。
结合了手动设计网络和神经网络搜索(NAS)的优点。其中整个网络分成三个部分:stem->body->head, body部分由4个stage组成,每一个stage又是由数个相同的block构成。相比EfficientNet拥有数倍的推理速度,故而使用较弱的GPU也可以进行训练。
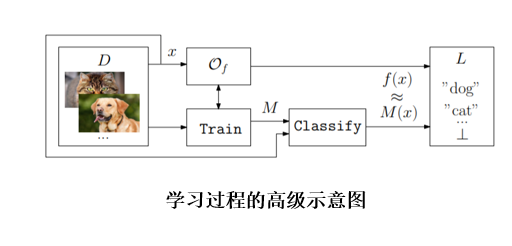
下面给出机器学习的抽象定义

神经网络中的后门
Backdooring neural networks,是一种故意训练机器学习模型输出错误(与ground-truth function f相比)的技术。
触发器集和标签函数一起称为后门b = (T,T)
让T⊂D是输入的一个子集,我们将把它称为触发器集合。
我们定义了一个后门算法,它在一个模型的输入时,会输出一个在高概率的触发集上分类错误的模型。
我们要求SampleBackdoor应该具备以下属性:
多个触发器:对于采样后门返回的每个触发器集,我们假设它的最小大小n。
持久性:一般情况下,我们要求移除后门是很难的,除非你知道触发集合t。
关于后门的说明
1.对手可能提交一个没有后门的模型,但是这个模型的准确率很低。定义不应该关心这种设置,因为这样的模型在实践中没有任何用处。
2.对手总是可以从零开始训练一个新模型,因此能够提交一个非常准确的不包含后门的模型。因此,一个拥有无限计算资源和无限访问权限的对手总是能够作弊。
定义水印算法
将一种水印方案分为三种算法:
(i)首先生成作为水印嵌入的标记密钥mk,然后生成用于检测水印的公钥验证密钥vk;
(ii)将水印嵌入模型的算法;
(iii)验证模型中是否存在水印
水印算法流程

水印算法流程图

非平凡所有权

不可移除性

不可伪造性

实现过程
对于实现来说,正确选择触发器集的大小|T|是很重要的,其中我们必须考虑|T|不能任意大,因为准确性会下降为了简单起见,我们使用一种反向操作算法,它从未定义的元素生成触发器集。
我们使用一组图像作为构造的标记键或触发器集。为了嵌入水印,我们同时使用训练集和触发集对模型进行优化。
在不设置触发集的情况下对模型进行训练,并选择一个触发集继续对模型进行训练,此方法称为预训练。第二种方法是根据触发器集合从头训练模型。后一种方法与数据污染技术有关。
使用三种不同的图像分类数据集:CIFAR-10、CIFAR-100和ImageNet。本文选择这些数据集来证明本方法可以应用于具有不同的模型,也可以应用于大规模数据集。
即使对手知道水印算法,他也无法主张模型的拥有权。为了满足这一要求,我们对触发器集的示例随机采样。我们采样了一组100个抽象图像,并对每个图像随机选择一个目标类。
这种基于采样的方法确保来自触发器集的示例互不相关。因此,揭示触发器集的一个子集不会揭示集合中其他示例的任何附加信息。此外,由于例子和标签都是随机选择的,遵循这种方法使得基于反向传播的攻击非常困难。下图显示了来自触发器集的示例。

保留功能的特性
对于保留功能的特性,带水印的模型与不带水印的模型一样精确。
由于目前的工作主要集中在图像分类任务上,我们使用0-1损失来衡量模型的准确性。
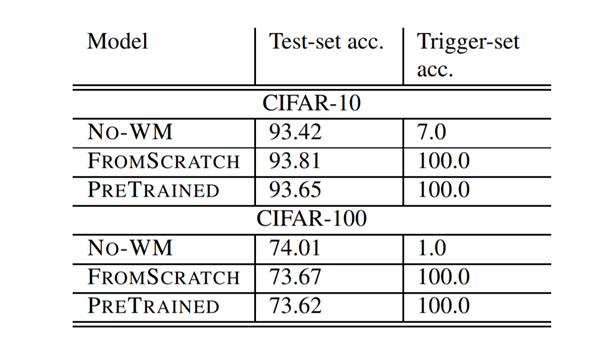
下表总结了三种不同模型在CIFAR-10和CIFAR-100上的测试集和触发集分类精度;
(1)无水印模型(no - WM);
(2)从零开始用触发器集训练的模型(FROMSCRATCH);
(3)在预训练模型上收敛后,用触发集进行训练的模型(PRETRAINED)。
不可移除性
为了满足不可移除属性,首先需要定义我们将要研究的不可移除函数的类型。我们在不可移除能力实验中的目标是研究水印模型在保持模型功能不变的情况下对水印去除变化的鲁棒性。否则,可以将所有权重设置为零,完全去除水印,但也会破坏模型。
因此,我们专注于微调参数的实验。微调似乎是最可能的攻击类型,我们假设攻击者可以使用与训练模型相同数量的训练实例和epoch来微调模型。
我们定义了四种不同的微调参数的过程:
1.微调最后一层(FTLL)
2.调整所有层(FTAL)
3.重新训练最后一层(RTLL)
4.重新训练所有层(RTAL)
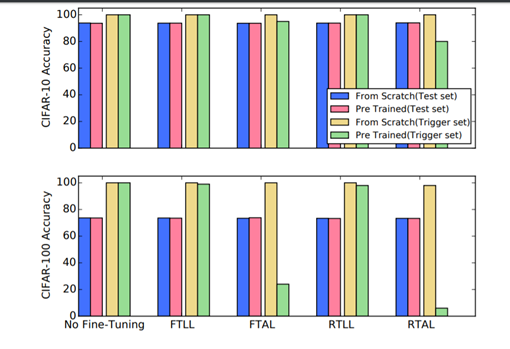
使用不同的微调技术对CIFAR-10 和CIFAR-100 检测分类精度。例如,在右下角的条形图中,我们可以看到,与使用RTAL技术的基线(左下角)相比,预先训练好的模型(绿色)的结果显著下降。
盗版可能性分析
在这组实验中,本文研究了这样一个场景:一个对手声称拥有一个已经被加过水印的模型所有权。
为此,我们收集了一个包含100张不同图像的新触发器集合,记为TS-NEW,并将其嵌入到FROMSCRATCH模型中(我们将使用这个新集合)
FROMSCRATCH模型使用不同的触发器集(记为TS-ORIG)进行训练。然后,我们使用RTLL和RTAL方法对模型进行微调。为了比较微调后的触发器集的鲁棒性,我们使用与原始触发器集相同的epoch来嵌入新的触发器集。
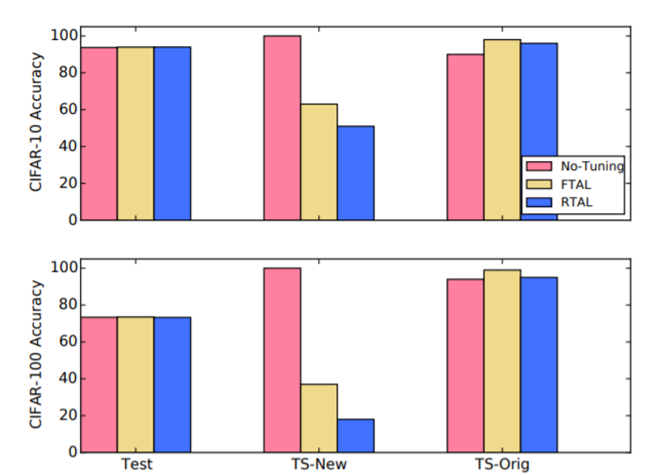
在嵌入TS-ORIG和TS-NEW两个触发集后,对CIFAR-10(上)和CIFAR-100(下)数据集的分类精度。我们给出了no tuning(红色)、FTAL(黄色)和TRAL(蓝色)的结果。在新的触发装置,TS-NEW,我们看到了一个显著的下降的准确性。
ImageNet大规模数据集上的分类效果

对于有水印和没有水印的ResNet18模型,imageNet上的分类效果。其中Prec@K表示设定一个阈值K,表示不同的精度。
编程细节
本文使用PyTorch框架实现所有模型。在所有的实验中,本文使用了ResNet-18模型,这是一种经典的卷积神经网络。
我们使用随机梯度下降(SGD)优化每个模型,学习率为0.1。对于CIFAR-10和CIFAR-100,我们训练了60个epoch的模型,同时将学习率减半,每20个epoch学习10个。对于ImageNet,我们对模型进行了30个epoch的训练,同时将学习率减半,每10个epoch学习10个。batch_size对CIFAR10和CIFAR100设置为100,对ImageNet设置为256。对于微调任务,我们使用了在训练过程使用的最后一个学习率。
训练代码
ResNet网络代码

运行展示
代码运行在ubuntu上,环境配置为python3.7,pytorch1.5,cuda10
使用GPU训练模型:

使用训练好的模型进行预测
调整网络最后一层,重新训练 Fine-Tune Last Layer (FTLL)
使用调整的网络进行预测
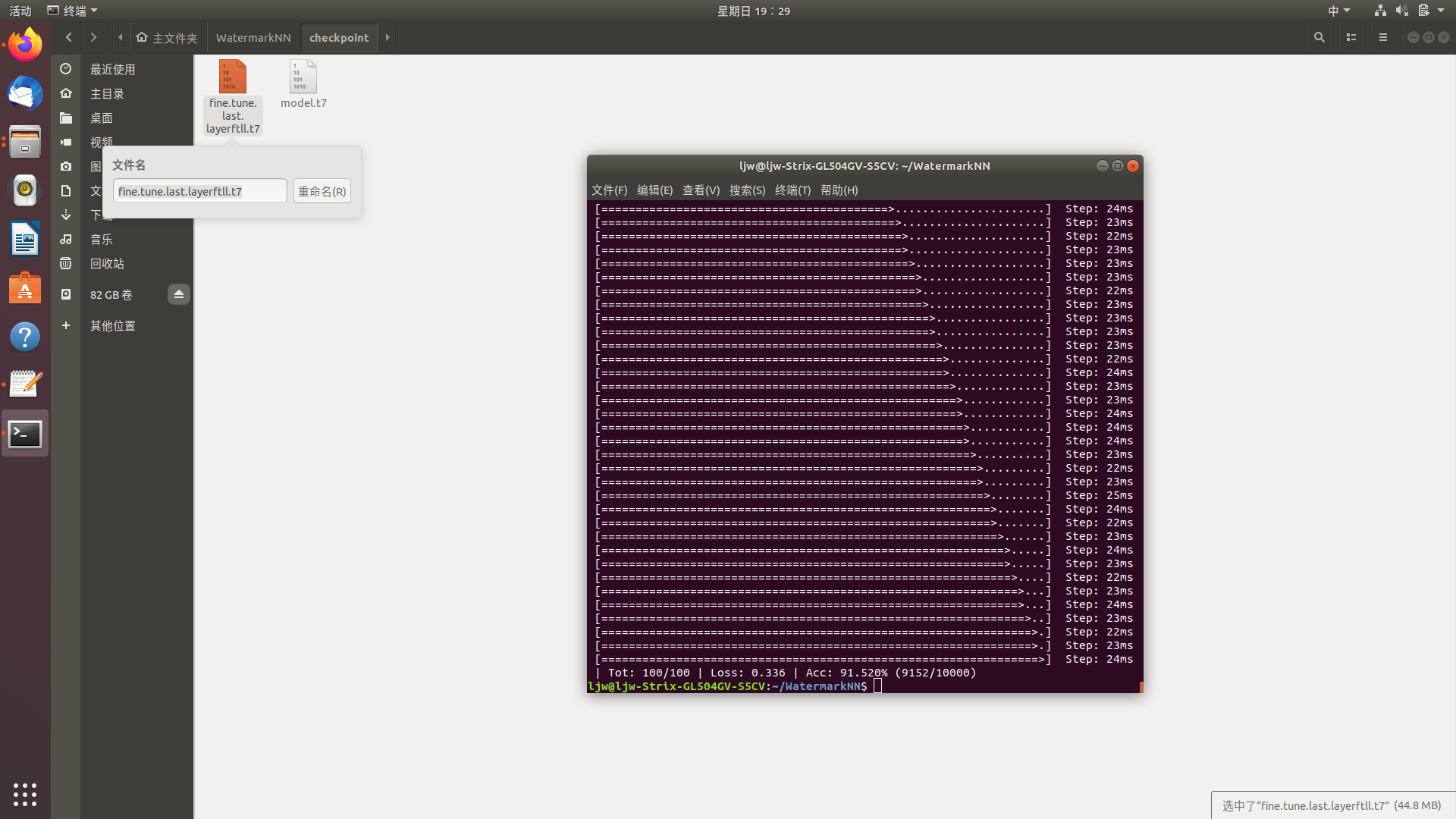
其他调整情况参照上述过程即可

