
DS博客作业02--线性表
0.PTA得分截图

1.本周学习总结
1.1线性表内容总结
1.1.1.1顺序表结构定义
typedef int ElemType;
typedef struct
{
ElemType data[MaxSize];//顺序表的元素
int length ;//顺序表的长度
} List;
typedef List *SqList;
1.1.1.2建立顺序表
void CreateList(SqList& L, int n)//n为要输入的数据个数
{
int i;
L = new List;//分配内存
L->length = n;
for (i = 0; i < n; i++)
{
cin >> L->data[i];
}
}
- n也可以放在函数内
1.1.1.3顺序表插入数据
void InsertSq(SqList& L, int x)
{
遍历顺序表L;
找到使x有序的位置;
移动数组并插入x;
}
略去一些细节的代码:
for (i = L->length - 1; i >= 0; i--)//从后往前,每一个数把值赋给下一位
{
if (x > L->data[i])
{
L->data[j] = x;
return;
}
L->data[j--] = L->data[i];
}
L->data[0] = x;
1.1.1.4顺序表删除数据
void DelNode(SqList& L, int min, int max)//区间删除数据
{
遍历顺序表L;
找到属于[min, max]的元素并删除;
}
省略细节的代码:
for (i = 0; i < L->length; i++)
{
if (L->data[i] >= min && L->data[i] <= max)
{
for (k = i; k < L->length; k++)
{
L->data[k] = L->data[k + 1];
}
L->length--;
i--;
}
}
1.1.1.5销毁顺序表
void DestroyList(SqList &L)
{
delete L;
}
1.1.2.1链表结构定义
typedef int ElemType;
typedef struct LNode
{
ElemType data;
struct LNode *next;
} LNode,*LinkList;
1.1.2.2建新链表
//带头结点
LinkList L;
L = new LNode;
L->next = NULL;
1.1.2.3链表数据插入
head = end = L;
node = new LNode;//循环内,每次结点申请内存
//头插法
node->next = head->next;
head->next = node;
//尾插法
node->next = NULL;//或node->next = end->next;
end->next = node;
end = node;
1.1.2.4链表插入、删除数据
//插入数据,多个数据可在main内循环输入
void ListInsert(LinkList& L, ElemType e)
{
定义指针p = L;//用于遍历链表
令node->data = e;
遍历链表L,找到插入位置;
用头插法代码插入;
}
//删除数据
void ListDelete(LinkList& L, ElemType e)
{
定义指针p = L, temp;//temp用于临时存储要删除的结点
找到与e相等的结点p->next;
temp存储p->next;
p->next = p->next->next;//保持链表不中断
删除temp;
}
1.1.2.5链表的合并
void MergeList(LinkList& L1, LinkList L2)
{
新建链表L3;
遍历链表L1,L2;
比较L1,L2中每个元素大小,每次将小的元素放入L3中;
结束循环后,若有链表未达到末尾,则插入L3尾部;
//此时根据题目需求,如果要求和L1或L2公用结点,则加入一句L1 = L3即可
//若无,可在函数的变量中加入L3
}
1.1.2.6循环链表、双链表结构特点
循环链表特点:
- 尾结点指向头結点,形成一个环,判断空链和链表结束的代码分别为:head == head->next, rear->next == head
双链表特点:
- 与单链表的区别每个结点多了一个直接前驱,可以指向前一个结点
- 循环链表、双链表的优点:无论指针在链表哪个位置都能遍历整个链表
1.2我对线性表的认识和学习体会
一开始学链表的时候,我经常出现断链,或者链接错误,直到我认识到next里存的是下一个结点的地址,才转过弯来,之前一直把next当作箭头使用,导致插入结点的代码顺序都出错,之后通过PTA的训练,熟练了不少。学习顺序表时,因为它和数组异曲同工,并没有那么困难。循环链表和双链表因为缺少题目,可能还不熟练。
2.PTA实验作业
2.1顺序表删除重复元素
2.1.1代码截图

2.1.2PTA提交列表说明

2.1.3遇到的问题
- 1.部分正确:空链表错误,因为题目没有要求,而我在空链表时输出NULL,操作改为return通过
- 2.部分正确:删除的位置错误,将前面的重复元素删除,而留下后面的元素,导致输出顺序与题目要求不一致
2.2链表倒数第m个数
2.2.1代码截图
2.2.2PTA提交列表说明

2.2.3遇到的问题
- 1.部分正确:最开始打算用递归来做,但因为对返回数据的处理的代码写的过于复杂,只能得出部分答案,剩余的不知如何下手
- 2.部分正确:改用快慢指针的做法,但没有对m=0的特殊情况进行处理,在开头加入判断后通过
2.3链表分割
2.3.1代码截图

2.3.2PTA提交列表说明

2.3.3遇到的问题
- 1.答案错误:把结点插入L时没处理好,导致两条链交叉,输出的数错乱
- 2.编译错误:链表越界,系统报错
3.阅读代码
3.1单链表反转(递归)

- 空间复杂度和时间复杂度都为O(n)
3.1.1设计思路
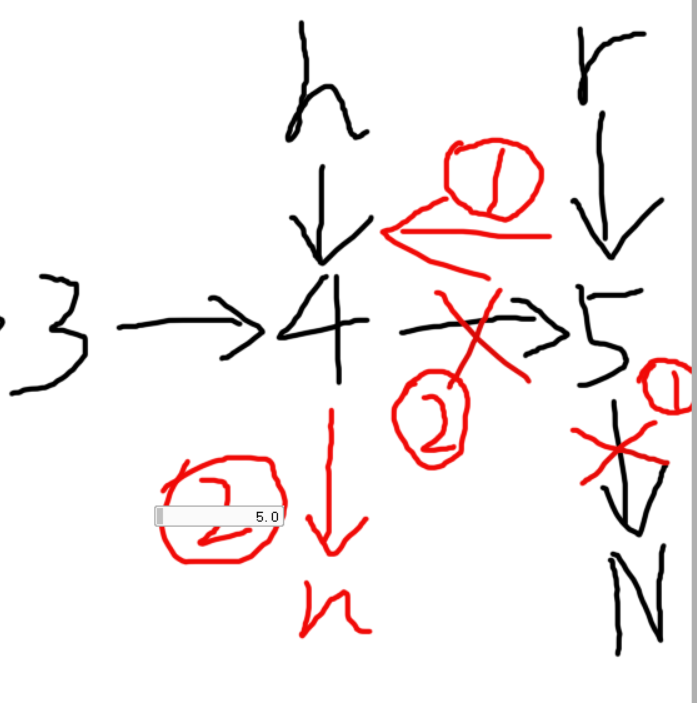
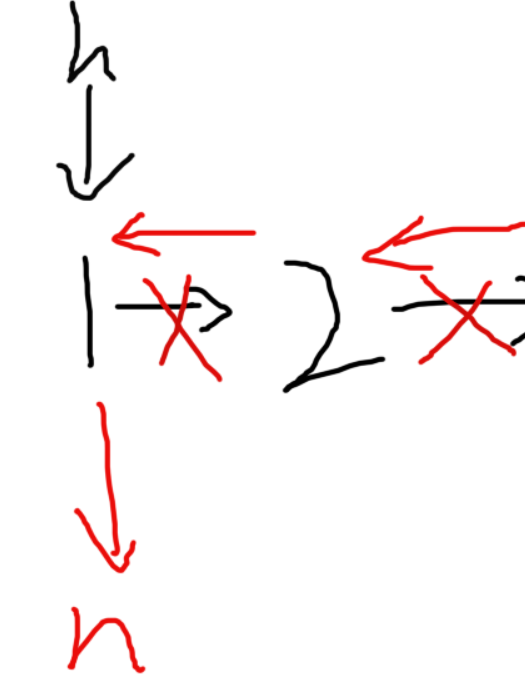
- 第一步,遇到空指针,返回head,reverse指向最后一个数
![]()
- 第二步,倒置:①:head->next->next=head(使下一个结点指向自己),②:head->next=nullptr(使自己指向空指针)
![]()
- 一直到回到开头
![]()

3.1.2伪代码
//代码为递归算法
ListNode* reverseList(ListNode* head)
{
if(传入的结点head为空或head->next为空)返回该结点;
建指针reverse储存最后一个结点的位置;
使下一个结点指向自己;
使自己指向空指针;
}
3.1.3运行结果

3.1.4该题目解题优势及难点
- 优点:代码简洁,时间复杂度小
- 缺点:比起头插法空间复杂度大,而且不能使用带头结点的链表进入函数,同时逆转后的链表没有头结点
- 难点:写代码时比较容易找不到思路,或者使用了多层循环导致时间复杂度过大
3.2寻找单链表的中间元素

- 时间复杂度为O(n),空间复杂度O(1)
3.2.1设计思路
- 定义快慢指针,快指针一次走俩,满指针一次走一,当快指针走到底时,慢指针正好在中间(奇数偶数都一样)
![]()
![]()


3.2.2伪代码
public Node getMid(Node head)
{
if(链表为空)空链表返回;
定义快慢指针,使其初始位置都在头结点;
while(快指针还没到底)
{
满指针走一步,快指针走两步;
}
出循环时慢指针刚好为中间位置,返回满指针;
}
3.2.3运行结果

3.2.4该题目解题优势及难点
- 优点:只需要遍历一次链表就能完成
- 难点:这道题其实不难,也可以通过遍历一遍链表得到长度len,再次遍历得到答案。所以这题考察的是如何简化时间复杂度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号