数据库基础第四章:数据操作
本章素材


--一新建数据库学校xx --新建表 xs --1、学号 xh int 主键 自动增长从1开始每次增长1 --2、姓名 xm nvarchar(20) 不为空 --3、性别 xb nvarchar(2) 不为空 --4、语文 yw numeric(4,1) 可空 --5、数学 sx numeric(4,1) 可空 -- 1、使用insert 语句添加数据10行 insert into xs(xm,xb,yw,sx) values('李盈淑','女',98,67); 1 李盈淑 女 98 67 2 白桃 女 56 88 3 荣在 男 75 46 4 范明 男 90 76 5 王普梦 女 66 54 6 张税华 男 87 78 7 李明心 女 55 89 8 赵双党 男 100 66 9 孙玉 女 35 57 10 刘明聪 男 86 88 insert into xs(xm,xb,yw,sx) values('白桃','女',56,88),('荣在','男',75,46),('范明','男',90,76) ,('王普梦','女',66,54),('张税华','男',87,78),('李明心','女',55,89),('赵双党','男',100,66),('孙玉','女',35,57),('刘明聪','男',86,88); --2、将xh为5的学生数学成绩修改为55分 update update xs set sx=55 where xh=5 --3、将“荣在”的语文成绩修改为76分 update update xs set yw=76 where xm='荣在' --4、将性别为女的学生语文与数学成绩各加1分 update update xs set yw=yw+1,sx=sx+1 where xb='女' --5、将“孙玉”与“刘明聪”的成绩都减少1分 update xs set yw=yw-1,sx=sx-1 where xm='孙玉' or xm='刘明聪' --6、将学号为5的学生删除。 delete delete from xs where xh=5; --7、将姓名为'荣在'的学生删除。delete DELETE FROM [xx].[dbo].[xs] WHERE xm='荣在' --8、删除“孙玉”与“刘明聪。delete DELETE FROM [xx].[dbo].[xs] WHERE xm='孙玉' or xm='刘明聪' --9、删除所有数据。delete delete from xs --10、添加10行数据,还原到未删除前的状态 --11、数据库备份 --12、数据库还原 --13、查询所有的学生 select * from xs; --14、查询指定的字段,只显示姓名与性别 select xm,xb from xs; --15、查询所有男生 select * from xs where xb ='男'; --16、查询所有女生的姓名(注意只显示姓名列) select xm from xs where xb='女' --17、查询姓名中包含“明”字的男生 %在匹配时表示任意字符_表示单个任意字符 select * from xs where xm like '%明%' and xb='男' --18、查询所有姓“李”的“男”生 select * from xs where xm like '李%' and xb='男' --19、查询编号为5的学生 select * from xs where xh=5 --20、查询姓名叫“荣在”的学生性别 select xb from xs where xm='荣在' --21、查询及格了的男生(语文与数学都要合格) select yw sx from xs where yw>=60 and sx>=60and xb='男'; --22、查询前5条记录 select top 5 * from xs; --23、排序 order by asc升序 desc降序 --根据语文成绩的升序排序 select * from xs order by yw; --24、根据数学成绩的降序排列 --25、根据总分降序排列 select *,yw+sx zf from xs order by zf desc; --26、根据平均分升序排列 --27、查询出成绩最高的学生信息 --28、根据性别分组 --COUNT 求组中项数,返回整数 --SUM 求和,返回表达式中所有值的和 --AVG 求均值,返回表达式中所有值得平均值 --MAX 求最大值,返回表达式中所有值得最大值 --MIN 求最小值,返回表达式中所有值的最小值 select xb,COUNT(*) 人数,AVG(yw) 语文平均分,avg(sx) 数学平均分 from xs group by xb; --29、查询出男生、女生的语文与数学的最高分、最低分与总分。 select COUNT(*) 总人数,SUM(yw) 语文总分 from xs; --30、查询出女生的总人数与数学总分 --31、获得语文最高分,数学最低分与语文数学的平均分 select MAX(yw) 语文最高,MIN(sx) as 数学最低,AVG(yw+sx)/2 语数平均 from xs; --32、获得男生语文最高分,数学最低分与语文数学的平均分 --33、查找姓范的男生 and select * from xs where xm like '范%' and xb='男' --34、查找姓李的学生和性别为男的学生 or select * from xs where xm like '李%' or xb='男' --35、查找不姓李的学生 not select * from xs where xm not like '李%' --33、查找姓李的女生 and --34、查找姓范的学生和性别为女的学生 or --35、查找不姓范的学生 not --36、查找学号为1,3,5,7,9的学生信息 --select * from xs where xh=1 or xh=3 or xh=5 or xh=7 or xh=9 select * from xs where xh in (1,3,5,7,9) --37、查看姓王、李、范、张的学生信息 --38、查找成绩在90-100之间的语文成绩的学生,含100和90 select * from xs where yw>=90 and yw<=100; select * from xs where yw between 90 and 100 --39、查找数学成绩不在60-90间的学生信息
SELECT [Id] ,[Name] ,[Price] ,[PublishDate] ,中文=case [IsChinese] when 1 then '是' else '否' end ,books.[TypeId] ,[TypeName] FROM Books inner join BookTypes on books.TypeId=BookTypes.TypeId GO USE AdventureWorks2008R2; GO SELECT ProductNumber, Category = CASE ProductLine WHEN 'R' THEN 'Road' WHEN 'M' THEN 'Mountain' WHEN 'T' THEN 'Touring' WHEN 'S' THEN 'Other sale items' ELSE 'Not for sale' END, Name FROM Production.Product ORDER BY ProductNumber; GO SELECT [TypeId] ,[TypeName] FROM [EFTextbook].[dbo].[BookTypes] GO
一、数据表操作
对数据库进行管理主要有两种方式,每一种是通过 GUI(图形用户界面 Graphical User
Interface,又称图形用户接口),这种方式操作简单且直观,但功能有限;第二方式是通过 SQL 指
令,这种方式上手相对复杂但功能强大,非常适合开发者。
我们可以在 SQL Server Management Studio 管理窗口中通过视图的方式可以实现对数据表的添
加、修改、删除和查询操作。
但是,这种用视图的方式管理数据不管对于应用程序还是用户来说有时会满足不了复杂的要求。
因此,本章重点使用 T-SQL 语句实现对数据表的添加、修改、删除和查询操作。
1.1. 添加记录操作
INSERT 语句是 SQL 语句中最常用的用于向数据表中插入数据的方法,使用 INSERT 语句可向表中添
加一个或多个新行。INSERT 语句的使用很简单,语法格式如下。
INSERT [INTO] table_or_view[(字段名 1, …,字段名 n)] VALUES (字段值 1, …,字段值 n)
参数说明:
table_or_view:用于指定向数据表中添加数据的表或视图名称。
字段名 1..字段名 n:用于指定该数据表的列名,可以指定一列或多列,所有这些列都必须放在圆
括号()中。如果要指定多个列时,各列必须用逗号隔开。如果指定了列名,那么在目标数据表中所有
未被指定的列必须支持空值或者默认值。
字段值 1..字段值 n:用于指定向数据表中插入的数据值。这些值也必须放在圆括号内,如果指定
的值为多个时,这些值之间也必须用逗号隔开。如果指定了列名,那么该数据必须与各列一一对应。
如果没有指定列名,该数据必须与数据表中各列的顺序一一对应。
下面例子是为图书信息表添加一条记录。
INSERT INTO 图书信息(图书名称,作者,出版社,价格,ISBN,类别) VALUES ('三国演义','吴承恩','南方出版社',26,'123-8-45875-2/TP','B1002')
在插入数据时,如果遗漏了列表和数值表中的一列,那么当该列存在默认值时,将使用默认值。
如果该列不存在默认值时,SQL Server 将尝试补一个空值。如果该列声明了 NOT NULL,那么将会导致
插入出错。
在 SQL Server Management Studio 工具中,我们使用 T-SQL 方式的操作步骤如下所示:
第一:登录、新建查询、选择要操作的数据库
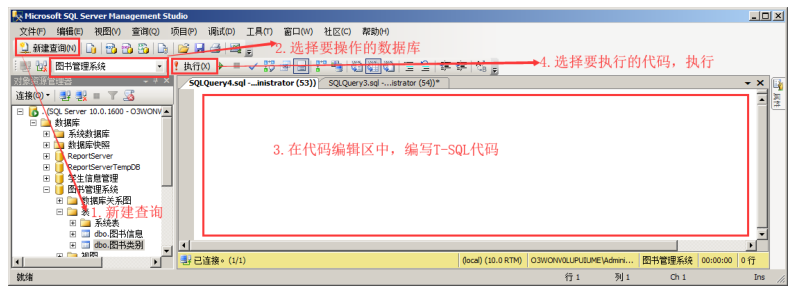
第二:在代码编辑区中,输入 T-SQL 代码,选择并执行代码
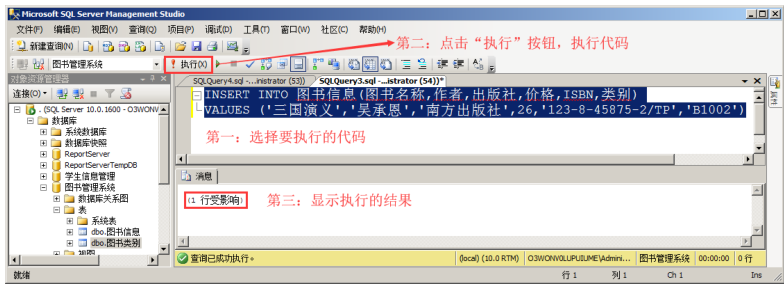
批量添加数据
insert into yg(xm,xb,gc,bmh) select '李四','男',8873.9,1 union select '王五','女',6748.5,2 union select '赵六','女',7834.1,5 insert into yg(xm,xb,gc,bmh) values ('张明','女',6875.3,1), ('王军','男',7875.1,2), ('李好','女',5875.9,3)
1.2. 修改记录操作
UPDATE 语句和大多数 SQL 语句一样,顾名思义,即更新已有数据。如果关系表中的数据已经没用
了,或插入的数据不正确,那么可以修改这些有问题的数据。修改关系中的数据需要使用 UPDATE 语
句。
UPDATE 语句的组成元素包括关键字 UPDATE,关系名、关键字 SET,设置属性为新值的表达式、关
键字 WHERE 和条件。UPDATE 语句的语法格式如下所示。
UPDATE <table name> SET <colum>=<value> [,<column>=<value>] [WHERE <search condition>]
在 UPDATE 语句中,UPDATE 子句和 SET 子句是必需的,在 UPDATE 中必须指定将要更新的表的名
称。关键字 SET 后面的一系列新值表达式,这些表达式由属性名、等号和新值组成,说明了要更新的
数据在关系中的列位置。关键字 WHERE 后面的 condition 条件用于指定将要修改的数据在关系中的位
置。因此,关键字 SET 和 WHERE 完全可以确定将要修改的数据的位置。
例如,将图书信息表中的图书编号为“3”的图书作者修改为“李耳”,图书价格修改为“66”,
操作如图 所示。
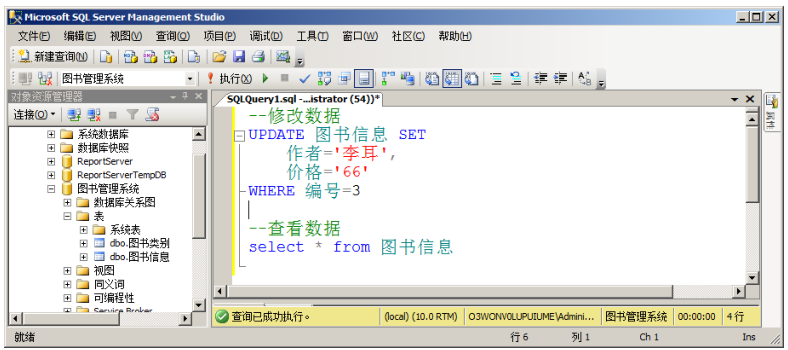
二、表达式
三、SELECT查询
SELECT 语句是一个查询表达式,包括 SELECT、FROM、WHERE、GROUP BY 和 ORDER BY 子句。SELECT
语句具有数据查询、统计、分组和排序的功能,可以精确地对数据库进行查找,也可以进行模糊查
询。
SELECT 语句有自己的语法结构,使用该语句时一定要严格执行其语法结构。加之其子句有很多,
这里只列举它的主要子句格式,如下所示:
SELECT [ALL|DISTINCT]select_list [INTO new_table] FROM table_source [WHERE search_conditions] [GROUP BY group_by_expression] [HAVING search_conditions] [ORDER BY order_expression[ASC|DESC]]
上面格式中,SELECT 查询语句中共有 5 个子句,其中 SELECT 和 FROM 语句为必选子句,而
WHERE、GROUP BY 和 ORDER BY 子句为可选子句。[]内的部分为可选项且大写内容为关键字。下面对各
种参数进行详细说明。
SELECT 子句:用来指定由查询返回的列,并且各列在 SELECT 子句中的顺序决定了它们在结
果表中的顺序。
ALL|DISTINCT:用来标识在查询结果集中对相同行的处理方式。关键字 ALL 表示返回查询结
果集的所有行,其中包括重复行;关键字 DISTINCT 表示若结果集中有相同的数据行则只保留显示一
行,默认值为 ALL。
select_list:用来指定要显示的目标列,若要显示多个目标列,则各列名之间用半角逗号隔
开;若要返回所有列,则可以用“*”表示。
INTO new_table:用来创建一个新的数据表,new_table 为新表的名称,表的数据为查询的
结果集。
FROM table_source 子句:用来指定数据源,table_source 为数据源表名称。
WHERE search_conditions 子句:用来指定限定返回的行的搜索条件,search_conditions 为
条件表达式。
GROUP BY group_by_expression 子句:用来指定查询结果的分组条件,即归纳信息类型,
group_by_expression 为分组所依据的表达式。
HAVING search_conditions 子句:用来指定组或聚合的搜索条件,search_conditions 为分
组后的条件表达式。
ORDER BY order_expression[ASC|DESC]子句:用来指定结果集的排序方式,ASC 表示结果集
以升序排列,DESC 表示结果集以降序排列,默认情况下结果集以 ASC 升序排列。
在使用 SELECT 语句时,还要遵守以下两条规则:
1) .T SELECT 语法中子句的测试顺序
SELECT 语句中的 FROM、WHERE、GROUP BY 和 HAVING 等子句称为表表达式,它们在执行 SELECT 语
句时首先被测试,并且每个子句按照某种次序被依次测试。了解了这种测试顺序,在用户创建较复杂
的 SELECT 语句时非常有用。
测试表示 SELECT 语句在系统中的执行,其结果是一个虚拟表,用于以后的测试。具体地说,前一
个子句的测试结果将用于下一个子句,直到表表达式的每个子句都被测试完毕。SELECT 语句中首先要
测试的子句是 FROM 子句。如果指定了 WHERE 子句,那么 FROM 子句的测试结果将用于 WHERE 子句。如
果没有 WHERE 子句,那么 FROM 子句的测试将用于下一个指定的子句。在表达式中的最后一个子句被测
试完之后,此时的测试结果才用于 SELECT 子句,而 SELECT 子句的测试结果用于 ORDER BY 子句。总的
来说,SELECT 语句的测试顺序为:
FROM 子句 WHERE 子句(可选) GROUP BY 子句(可选) HAVING 子句(可选) SELECT 子句 ORDER BY 子句(可选)
了解该测试顺序对于提高查询效率有很大意义,这种效率在简单的查询语句中表现的并不明显。
但是一旦用户使用了复杂的查询语句,尤其是在处理连接和子查询时,不了解 SELECT 语句的测试顺序
将严重影响 SELECT 语句的查询效率。
2) .引用对象名称约定
若使用 SELECT 语句查询时,所引用对象的数据库不是当前数据库或引用的列名不明确时,为了保
证查询的正确性,在引用数据表或列时需要使用数据库或数据表名来限定数据表或列的名称。
如果要引用某数据表名称,而当前数据库不是所引用对象的数据库,就需要使用 USE 语句将当前
数据库设置为该表所在的数据库。例如,当前数据库为“student”,而现在要引用“zxt”数据库中
的“answer”数据表,这时需要在前面加上“USE student”语句。
如果当前使用的列名不明确是哪个数据表中的列,就需要通过给该列指定表名来确定其数据源。
例如,在同一数据表中的多个表中都存在着名为“学号”的列,当进行多表操作时,如果只使用“学
号”指定选择条件,就会出现歧义,所以需要通过表名来明确所要指定的“学号”列,即使用
“stuinfo.stuno 和 exam.stuno”表示。
3.1. 使用 SELECT 语句
前面已经详细介绍了 SELECT 及其子句的语法格式,本节将主要列举实例,单独介绍 SELECT 语句
的使用方法而并不涉及它的各个子句。关于其子句的使用方法及其特点将在后面的章节中详细介绍。
(1) 查询全部行和列
语法:select {列举所有字段名|*} from 表名
--查询全表 Select * from stuinfo; --按字段列表查询 Select stuno,stuName,stuAge,stuSex,stuTel,stuAddress from stuinfo;
注意:当你要把所有字段的值都要查询出来时,可以用“*”号取代替所有字段。但我们也应
该清楚地明白,用“*”号代替所有字段,在代码上我们是省事了,尤其是有些几十上百个字段的表,
但执行的效率上来说是不可取的,执行“*”要先从数据字典中查询出待查询的表的所有字段后再进行
查询的。因此性能上来说差了很多。
(2) 查询全部行和部分列
语法:select column1,column2…from 表名
举例:
Select stuno,stuname from stuinfo; Select stuName,stuTel,stuAddress from stuinfo;
注意:当我们只要查看表中的某些列值时,必须指定字段名进行查询。而且还可以在字段名
上加函数进行运算。
(3) 查询部分行和全部列
语法:select 所有字段名 from 表名 where 查询条件语句集合
举例:
--查询手机号是13800138000的学员的所有资料 Select * from stuinfo where stuTel=’13800138000’ --查询姓名为刘志峰的学员的所有资料 Select * from stuinfo where stuname=’刘志峰’
注意:where 子句中的条件可以是多个,多个条件之间可以用 or 或 a nd 等逻辑运算符连接
起来。如:
--查询手机号以139开头的珠海的学员的所有资料 Select stuno,stuName,stuAge,stuSex,stuTel,stuAddress from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
(4) 查询部分行和部分列
语法:select 部分字段名 from 表名 where 查询条件语句集合
举例:
--查询手机号以139开头的珠海的学员的学号、姓名与具体地址 Select stuno,stuName,stuAddress from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
(5) 添加 top n 查询顶部几条记录
语法:Select top n 部分字段名| 所有字段名 from 表名
举例:
--查询手机号以139开头的珠海的前3个学员的学号、姓名与具体地址 Select top 3 stuno,stuName,stuAddress from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
注意:top n 必须放在 select 关键字后面,第一个被查询字段的前面。使用 top n 时也可以
用*表示要查询所有的字段,top n 中的 n 表示要显示查询结果集中的前 n 条记录。
(6) 添加 top n percent 查询表中百分比的记录
语法:Select top n percent 部分字段名| 所有字段名 from 表名
举例:
--查询手机号以139开头的珠海的学员的学号、姓名与具体地址,显示前10%的记录 Select top 10 percent stuno,stuName,stuAddress from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
(7) 使用+ 号并列查询
语法:select 字段名 m+字段名 n,其他字段名 from 表名
举例:
--查询手机号以139开头的珠海的学员的学号、姓名与地址,出生日期 Select stuno,stuName+'('+stuAddress+')',birthday from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
注意:把多个字段与某些常量或表达式通过运算符“+”号把它们合并在一起,生成新的值如
“张三(珠海香洲)”格式并显示出来。
(8) 查询中使用 as 以别名显示字段名
语法:select 字段名 m+字段名 n a s 别名,其他字段名 from 表名
举例:
--查询手机号以139开头的珠海的学员的学号、姓名与地址,出生日期 Select stuno,stuName+'('+stuAddress+')' as fullName,birthday from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
注意:多个字段或常量或表达式通过运算符合起来的字段如果不用 a s 命一个别名,这个字段
名将会很长,而且难以认识。这里的 a s 还可以省略,上面的例子可以写成如下:
--查询手机号以139开头的珠海的学员的学号、姓名与地址,出生日期 Select stuno,stuName+'('+stuAddress+')' fullName,birthday from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
(9) 查询中使用= 号代替 as 的用途
语法:select 别名=字段名 m+字段名 n,其他字段名 from 表名
举例:
--查询手机号以139开头的珠海的学员的学号、姓名与地址,出生日期 Select stuno, fullName = stuName+'('+stuAddress+')',birthday from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
注意:这种命别名的方式与前一种只是语法格式上不同,效果是一样的。
(10) 查询中使用 as 添加常量列
语法:select 部分字段名|全部字段名, '常量值' a s 新字段名 from 表名
举例:
--查询手机号以139开头的珠海的学员的学号、姓名与地址,出生日期 Select stuno,stuname, ‘中国’ as country ,stuAddress from stuinfo where stuTel like ’139%’ and stuAddress like ‘%珠海%’
3.2. 使用 FROM 子句
FROM 子句是 SELECT 语句中必不可少的子句,该语句用于指定要读取的数据所在的一个表或几个表
的名称,使用 FROM 子句表示要输出信息的来源。FROM 子句的基本语法格式如下所示:
FROM table_source
其中,table_source 指定要在 Transact-SQL 语句中使用的表、视图或派生表源(有无别名均
可)。虽然语句中可用的表源个数的限值根据可用内存和查询中其他表达式的复杂性而有所不同,但
一个语句中最多可使用 256 个表源。单个查询可能不支持最多有 256 个表源,可将 table 变量指定为
表源。
如果查询中引用了许多表,查询性能会受到影响。编译和优化时间也受到其他因素的影响。这些
因素包括:每个<table_source>是否有索引和索引视图,以及 SELECT 语句中<select_list>的大小。
表源在 FROM 关键字后的顺序不影响返回的结果集。如果 FROM 子句中出现重复的名称,SQL Server 会
返回错误。
在指定 table_source 表的同时也可以使用 AS 关键字给该表定义一个别名,别名可带来使用上的
方便,也可用于区分自连接或子查询中的表或视图。别名往往是一个缩短了的表名,用于在连接中引
用表的特定列。如果连接中的多个表中存在相同的列名,SQL Server 要求使用表名、视图名或别名来
限定列名。如果定义了别名则不能使用表名。
下面来对“STUDENT”数据库中的“StuInfo”表进行简单查询,并对“stuInfo”表定义别名为
“s”。具体查询语句如下所示:
SELECT * FROM StuInfo AS s
3.3. 使用 WHERE 子句
在 SQL Server 数据库中查询数据时,有时需要定义严格的查询条件,只查询所需要的数据,而并
非是数据表中的所有数据,那么就可以使用 SELECT 语句中的 WHERE 子句来实现。它类似一个筛选器,
通过用户定义的查询条件,来保留从 FROM 子句中返回并满足条件的数据。
WHERE 子句被用于选取需要检索的数据行,灵活地使用 WHERE 子句能够指定许多不同的查询条件,
以实现更精确的查询,如精确查询数据库中某条语句的某项数据值或在 WHERE 子句中使用表达式。
在 SELECT 查询语句中,使用 WHERE 子句时一般语法结构为:
SELECT condition FROM table WHERE searchcondition
其中,search_conditions 为用户选取所需查询的数据行的条件,即查询返回的行记录的满足条
件。对于用户所需要的所有行,search_conditions 条件为 true;而对于其他行,search_conditions
条件为 false 或者未知。WHERE 子句使用灵活,searchcondition 有多种使用方式,表 4-8 列出了
WHERE 子句中可以使用的条件。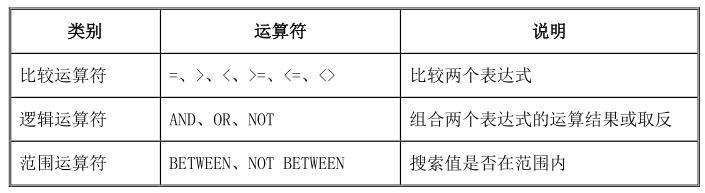
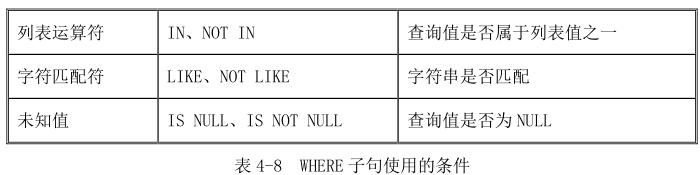
针对表 4-8 列举的查询条件,下面将详细介绍他们在 WHERE 子句中的使用方法及其功能。
(1) 比较运算符
WHERE 子句的比较运算符主要有=、<、>、>=、<=、<>和!=,分别表示等于、小于、大于、大于等
于、小于等于、不等于(<>和!=都表示不等于),使用他们对查询条件进行限定。下面通过几个实
例,详细介绍这些比较运算符的使用方法。
等于“= = ”运算符
在“student”数据库“stuinfo”表中查询学号为'13540607014'的“学员姓名”、“出生日期” 以及“地址”,此时,用户可以使用下面的语句: SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuno= '13540607014'
上面语句中使用“stuno= '13540607014'”指定查询条件,且该条件中“=”后面的内容使用单引
号括起来。
使用小于“< ”运算符
小于运算符使用方法和注意事项与等于运算符基本相同,使用小于运算符可以指定查询的某个范
围,例如查询“学员信息”表中“年龄”小于 30 岁的“学员姓名”、“出生日期”以及“地址”,使
用下面语句:
SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuage<30
使用不等于运算符
比较运算符中!=和<>都表示不等于,例如查询“学员信息”表中“年龄”不等于 30 岁的“学员姓
名”、“出生日期”以及“地址”,使用下面语句:,使用下面语句:
SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuage<>30
上面使用!=符号,其中!也是一种运算符,如!<表示不小于(大于等于),而!>表示不大于(小于
等于)。
(2) 逻辑运算符
有时,在执行查询任务时,仅仅指定一个查询条件不能够满足用户需求,此时需要指定多个条件
来限制查询,那么就要使用逻辑运算符将多个查询条件连接起来,同时指定多个条件进行查询。
WHERE 子句中可以使用 AND、OR 和 NOT 这三个逻辑运算符,表 4-9 列举了它们的作用与使用方法。
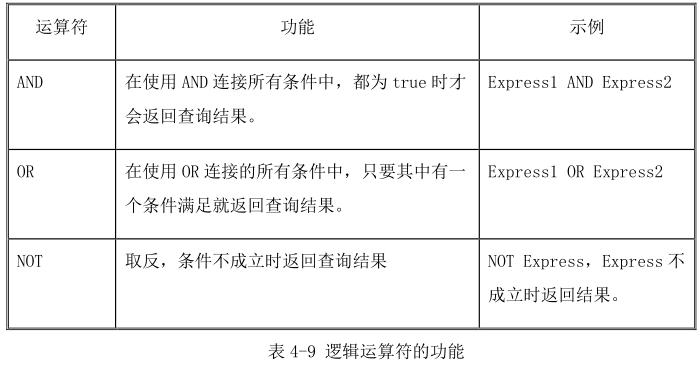
这三个逻辑运算符可以混合使用,在 WHERE 子句中使用逻辑运算符来限定查询条件的语法格式
为:
WHERE NOT expression|expression1 logical_operator expression2
其中,logical_operator 表示逻辑运算符 AND 和 OR 中的任意一个。如果在 WHERE 子句中使用 NOT
运算符,则将 NOT 放在表达式的前面。
例如,在“ student”数据库中,查询“学员信息”表中年龄>=20,且年龄<30 的“学员姓名”、
“出生日期”以及“地址”,使用下面语句:
USE student SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuage>=20 and stuage<30
默认情况下,NOT 只对紧跟着它后面的那个条件取反,因此使用 NOT 运算符时,如果连接多个条件
同时取反,需要将这多个条件用括号括起来。
NOT 运算符使用很灵活,在 WHERE 子句可以与多种条件共用,例如 NOT LIKE、NOT BETWEEN、IS
NOT NULL 等。当 NOT 与 AND 或 OR 结合使用时,具有如下规则:
NOT(A AND B)=(NOT A)OR(NOT B) NOT(A OR B)=(NOT A)AND(NOT B) NOT(NOT A)=A
在使用 AND 和 OR 两个逻辑运算符时,它们只对紧挨着它的两个条件有限定作用,如果它们需要连
接一组条件时,需要将这一组条件用括号括起来。例如下面的语句:
USE student SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuAddress=’珠海’ and (stuage<20 or stuage>30)
(3) 使用 IN 条件
在 SQL Server 数据库中,执行查询操作时,会遇到查询某表达式的取值属于某一列表之一的数
据,虽然可以结合使用比较运算符和逻辑运算符来满足查询条件,但是这样编写 SELECT 语句会使
SELECT 语句的直观性下降。使用 IN 或 NOT IN 关键字限定查询条件,更能直观地查询表达式是否在列
表值中,也可作为查询特殊信息集合的方法。使用 IN 关键字来限定查询条件的基本语法格式为:
WHERE expression [NOT] IN value_list
上述语句中 NOT 为可选值,而 value_list 表示列表值,当值不止一个时需要将这些值用括号括起
来,各列表值之间使用逗号隔开。
例如在“学员信息”表中查询“学号”为 13540607014、13550418023、13540925028、
13550304010 的“学员姓名”、“出生日期”以及“地址”,可以使用下面语句:
USE student SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuno in('13540607014','13550418023','13540925028','13550304010')
上面语句中
('13540607014','13550418023','13540925028','13550304010')定义了一个列表值,查询的内容
为“学号”属于列表值中的内容。执行语句。
从执行语句和返回结果中可以看到,使用 IN 可以返回一组特定的结果,上面的实例也可以使用逻
辑运算符写成下面的形式:
USE student SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuno = '13540607014' Or stuno = '13550418023' Or stuno = '13540925028' Or stuno = '13550304010'
通过比较两种写法可以看出,在这种情况下使用逻辑运算符明显比较复杂,SELECT 也比较长。因
此选用合适的条件进行 SELECT 查询,能提高语句的可读性并能提高执行效率。
使用 IN 条件时还应注意,在列表值中各值必须具有相同的数据类型。另外,列表值中各项不能包
含 NULL 值。同样,在使用 NOT IN 时也应该注意这些,例如使用下面的语句查询不属于列表值的内
容:
USE student SELECT stuNo,stuName,birthday,stuAddress FROM stuinfo WHERE stuno not in('13540607014','13550418023','13540925028','13550304010')
(4) 使用 BETWEEN 条件
在 WHERE 子句中使用 BETWEEN 关键字查找在某一范围内的数据,也可以使用 NOT BETWEEN 关键字
查找不在某一范围内的数据。使用 BETWEEN 关键字来限定查询条件的语法格式如下所示:
WHERE expression [NOT] BETWEEN value1 AND value2
其中 NOT 为可选项,value1 表示范围的下限,value2 表示范围的上限。注意 value1 必须不大于
value2,绝对不允许 value1 大于 value2。
例如,在“学员信息”表中查询年龄在 20 与 30 之间学员的“学员姓名”、“出生日期”、“年
龄”以及“地址”,可以使用下面语句:
USE student SELECT stuNo,stuName,stuAge,birthday,stuAddress FROM stuinfo WHERE stuAge between 20 and 30
上面的语句中,通过在 WHERE 子句中使用 BETWEEN 关键字查询了“年龄”在 20-30 之间的所有数
据。
如果想查询“年龄”在 20 至 30 之外的所有数据,则只需在 BETWEEN 关键字前面加上 NOT 即可,
语句如下所示:
USE student SELECT stuNo,stuName,stuAge,birthday,stuAddress FROM stuinfo WHERE stuAge not between 20 and 30
(5) 使用 LIKE 匹配条件
在 SQL Server 数据库中,执行查询任务时,可能无法确定某条记录中的具体信息,如果要查找该
记录时则需要使用模糊查询。比如查找学员信息中姓“王”的相关信息,或者查询学员所在地区为
“江西”的相关信息。
在 WHERE 子句中使用 LIKE 与通配符搭配使用,可以实现模糊查询。在 WHERE 子句中使用 LIKE 关
键字的作用是将表达式与字符串作比较。LIKE 关键字同样也可以与 NOT 运算符一起使用。使用 LIKE
关键字限定查询条件的语法格式为:
WHERE expression [NOT] LIKE 'string'
其中,[NOT]为可选项,'string'表示进行比较的字符串。WHERE 子句实现对字符串的模糊匹配,
进行模糊匹配时在 string 字符串中使用通配符。在 SQL Server 2008 中使用含有通配符时必须将字符
串连同通配符用单引号括起来。表 4-10 中列出了几种比较常用的通配符表示方式和说明。
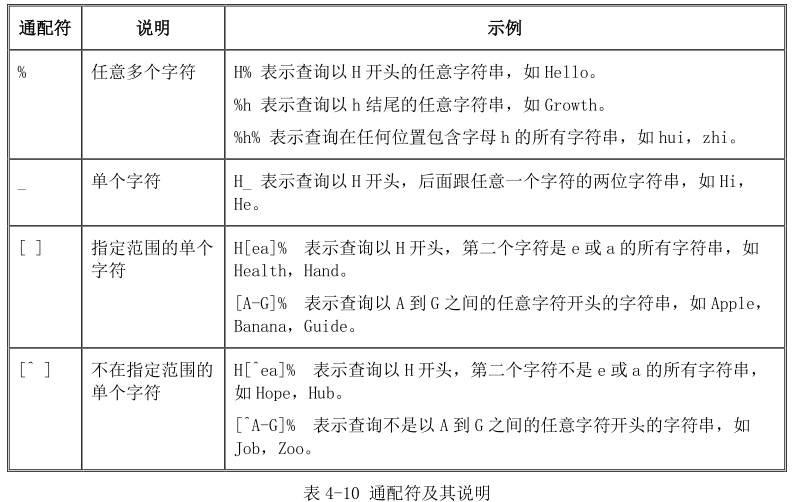
例如,在“学员信息”表中查询学员的地址为“珠海”的“学员姓名”、“出生日期”、“年
龄”以及“地址”,可以使用下面语句:
USE student SELECT stuNo,stuName,stuAge,birthday,stuAddress FROM stuinfo WHERE stuAddress like ‘%珠海%’
上面语句中使用 LIKE 与通配符%结合查询所在地址在“珠海”的所有学员。
(6) 使用 IS NULL 条件
NULL 表示未知、不可用或将在以后添加数据,NULL 值与零、零长度的字符串或空白(字符值)的
含义不同。相反,空值可用于区分输入的是零(数值列)或空白(字符列)还是无数据输入(NULL 可
用于数值列和字符列)。
在 WHERE 子句中使用 IS NULL 条件可以查询某一数据值为 NULL 的数据信息。反之要查询数据库中
的值不为 NULL 时,可以使用 IS NOT NULL 关键字。使用 IS NULL 条件的语法格式为:
WHERE column IS [NOT] NULL
例如,在“学员信息”表中查询“出生日期”列为 NULL 的学员信息,可以使用下面的语句:
USE student SELECT stuNo,stuName,stuAge,birthday,stuAddress FROM stuinfo WHERE birthday is null
在上面的语句中,WHERE 子句限定了“出生日期”列为 NULL 的学员信息,执行语句后。
3.4. 使用 ORDER BY 子句
ORDER BY 子句一般位于 SELECT 语句的最后,它的功能是对查询返回的数据进行重新排序。用户可
以通过 ORDER BY 子句来限定查询返回结果的输出顺序,如正序或者倒序等。
ORDER BY 子句在 SELECT 语句中的语法格式为:
ORDER BY order_expression [ASC | DESC]
其中,order_expression 表示用于排序列或列的别名及表达式。当有多个排序列时,每个排序列
之间用半角逗号隔开,而且列后都可以跟一个排序要求:当排序要求为 ASC 时,行按排序列值的升序
排序;排序要求为 DESC 时,结果集的行按排序列值的降序排列。如没指定排序要求,则使用默认值
ASC。
例如,将“STUDENT”数据库的“学员信息”表按照“年龄”进行升序排列,以查看学员的信息。
可以使用下面的语句:
USE student SELECT * FROM stuinfo ORDER BY stuAge ASC
上面的语句,使用 ORDER BY 指定“stuAge”进行升序排序。
默认情况下为正序排列,因此在使用 ORDER BY 子句时不需要指定 ASC,系统也会自动进行正序排
列。
如果用户对表比较熟悉,在对列进行排序时,可以直接指定列在表中的位置号,以方便操作。例
如,“stuno”列在“学员信息”表中为第 1 列。上列语句就可以直接将排序依据的“stuno”列改为
1。
使用 ORDER BY 子句还可以同时对多个列进行排序。例如,对学员信息表中的数据查询时先按“性
别”进行升序排列,如果“性别”列中有相同的数据,那么再按照“年龄”进行降序排列,具体的
SELECT 语句如下所示:
SELECT * FROM stuinfo ORDER BY stuSex ASC,stuAge DESC
3.5. 使用 GROUP BY 子句
数据库具有基于表的特定列对数据进行分析的能力。可以使用 GROUP 子句对某一列数据的值进行
分组,分组可以使同组的元组集中在一起,这也使数据能够分组统计。换句话说,就是 GROUP BY 子句
用于归纳信息类型,以汇总相关数据。
GROUP BY 子句的语法格式为:
GROUP BY group_by_expression [WITH ROLLUP|CUBE]
其中,group_by_expression 表示分组所依据的列,ROLLUP 表示只返回第一个分组条件指定的列
的统计行,若改变列的顺序就会使返回的结果行数据发生变化。CUBE 是 ROLLUP 的扩展,表示除了返
回由 GROUP BY 子句指定的列外,还返回按组统计的行。GROUP BY 子句通常与统计函数联合使用,如
COUNT、SUM 等。在表 4-11 中列出了几个常用的统计函数及功能。
COUNT 求组中项数,返回整数 SUM 求和,返回表达式中所有值的和 AVG 求均值,返回表达式中所有值得平均值 MAX 求最大值,返回表达式中所有值得最大值 MIN 求最小值,返回表达式中所有值的最小值
在使用 GROUP BY 子句时,将 GROUP BY 子句中的列称为分割列或分组列,而且必须保证 SELECT 语
句中的列是可计算的值或者在 GROUP BY 列表中。
例如,要在学员信息表中按照“出生日期”查询出对应每年出生的统计人数,具体 SELECT 语句如
下所示:
USE STUDENT select YEAR(birthday) year,COUNT(*) as amount from StuInfo group by YEAR(birthday)
执行上述语句后,将对 stuInfo 表中 birthday 列的年进行分组,并且对于出生日期为同一年的每
一组使用 COUNT()函数统计出每年出生的人数。
GROUP BY 子句通常用于对某个子集或其中的一组数据,而不是对整个数据集中的数据进行合计运
算。在 SELECT 语句中指定的列必须是 GROUP BY 子句中的列名,或者被聚合所使用的列,并且在
GROUP BY 子句中必须使用列的名称、而不能使用 AS 子句中指定的列的别名。
课堂作业:
1、分别向 BookType(图书类型表)、Bookes(图书表)添加几条测试数据。
2、查询所有的图书类型信息。查询价钱>=40 的所有图书信息,按价钱降序显示。
四、作业
1、创建电子商城数据库MallDB,创建商品表Goods,字段要求如下:
编号 bh int 主键,自动增长从1开始每次增加1
名称 mc nvarchar(50) 不为空 唯一键
价格 jg numeric(8,2) 默认值为0 可空
上货日期 shrq datetime 默认值为当前日期getDate()
2、使用SQL脚本向数据库中添加10条记录,insert
3、将所有商品的价格提高10%,update
4、将价格大于15的商品降价20%,update
5、将每个商品的名称后面增加字符“天狗商城”,update
五、考试题
1、创建一个图书数据库(BookDb)到d:\data目录下,10分
2、创建一个图书表Books,字段要求如下 10分
编号 bh int 主键 自动增长
书名 sm nvarchar(50) 非空
价格 jg numeric(10,2) 可空
出版社 cbs nvarchar(50) 可空
3、使用insert语句添加至少10行记录 10分
1、张爱玲:《倾城之恋》、35.1、机械工业出版社
2、马格利特·杜拉斯:《情人》、27.8、清华大学出版社
3、考林·麦卡洛:《荆棘鸟》、19.9、人民邮电出版社
4、村上春树:《挪威的森林》、57.8、清华大学出版社
5、渡边淳一:《失乐园》、13.6、机械工业出版社
6、钱钟书:《围城》、33.1、电子工业出版社
7、劳伦斯:《虹》、76.3、清华大学出版社
8、泰戈尔:《飞鸟集》、28.8、人民邮电出版社
9、塞林格:《麦田里的守望者》、19.5、机械工业出版社
10、米兰·昆德拉:《生命中不能承受之轻》、54.3、电子工业出版社
11、德克旭贝里:《小王子》、10.9、人民邮电出版社
4、将编号为5的出版社修改成“清华大学出版社”10分
5、将价格小于20的图书增加3.5元 10分
6、删除编号为7的图书 10分
8、查询价格超过40元的图书名称 10分
9、统计“清华大学出版社”的图书数量、最高价格、最低价格、平均价格、总价格 10分
10、查询价格不在20-30间的图书名称与价格 10分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号