Scrapy模拟登录赶集网
1.打开赶集网登录界面,先模拟登录并抓包,获得post请求的request参数
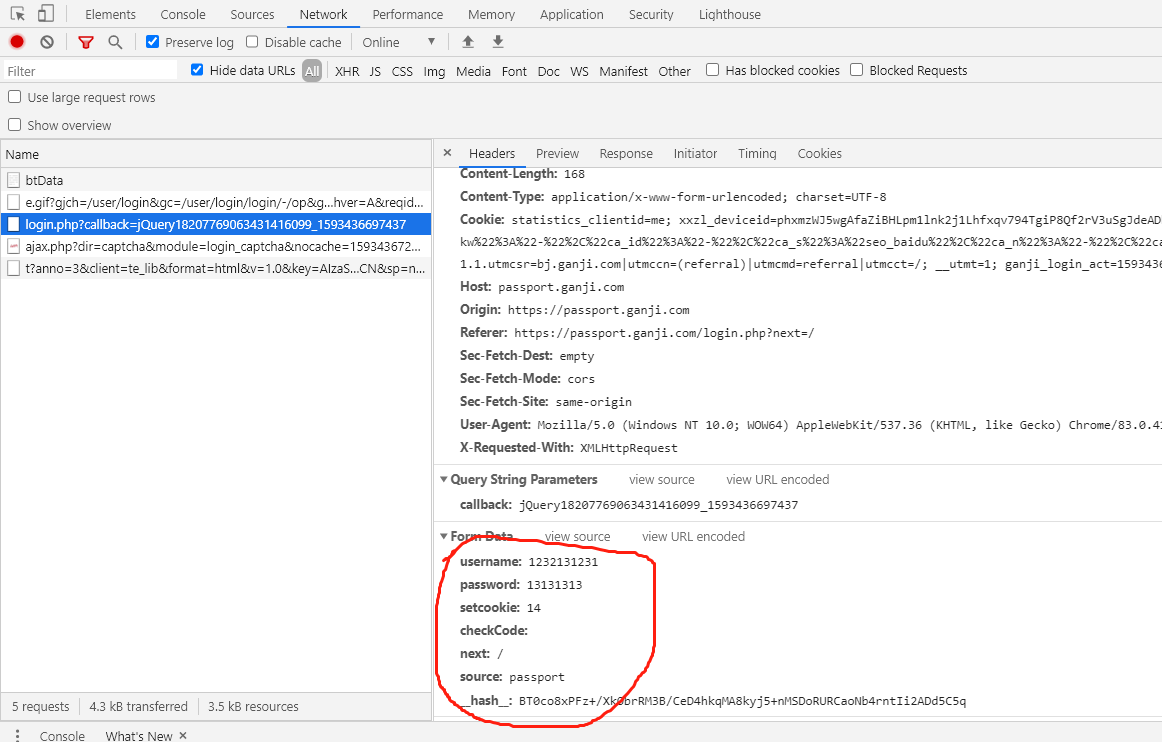
2. 我们只需构造出上面的参数传入formdata即可
参数分析:
setcookie:为自动登录所传的值,不勾选时默认为0。
__hash__值的分析:只需要查看response网页源代码即可 ,然后用正则表达式提取。
3.代码实现
1.workon到自己的虚拟环境 cmd切换到项目目录,输入scrapy startproject ganjiwangdenglu,然后就可以用pycharm打开该目录啦。
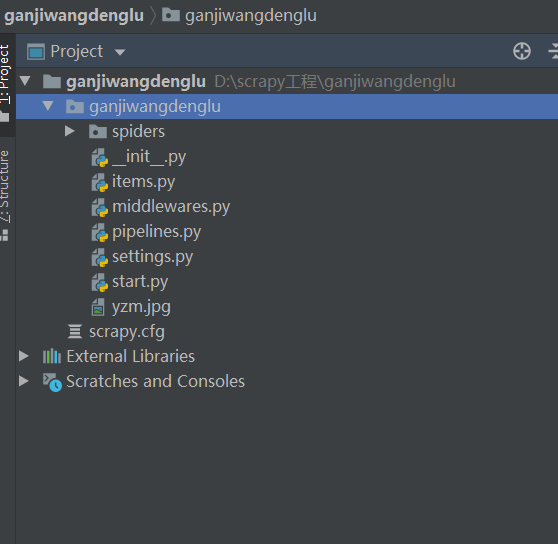
2.在pycharm terminal中输入scrapy ganji ganjicom 创建地址,如下为项目目录
3. 代码详情
import scrapy import re class GanjiSpider(scrapy.Spider): name = 'ganji' allowed_domains = ['ganji.com'] start_urls = ['https://passport.ganji.com/login.php'] def parse(self, response): hash_code = re.search(r'"__hash__":"(.+)"}', response.text).group(1) # 正则获取哈希 img_url = 'https://passport.ganji.com/ajax.php?dir=captcha&module=login_captcha' # 验证码url yield scrapy.Request(img_url, callback=self.do_formdata, meta={'hash_code': hash_code}) # 发送获取验证码请求并保存验证码到本地 def do_formdata(self, response): with open('yzm.jpg', 'wb') as f: f.write(response.body) # 验证码三种方案:1,保存下来手动输入,2,云打码,3 tesseract模块,在这里我们手动输入 code = input('请输入验证码:') # 创建表单 formdata = { 'username': 'your_username', 'password': 'your_password', 'setcookie': '14', 'checkCode': code, 'next': '', 'source': 'passport', '__hash__': response.request.meta['hash_code'] # meta是在respose.request中 } login_url = "https://passport.ganji.com/login.php" yield scrapy.FormRequest(url=login_url, formdata=formdata, callback=self.after_login) # 发送登录请求 def after_login(self, response): print(response.text)
4.终端输入scrapy carwl ganji 即可大功告成 。
返回来的json字符串解析如下:
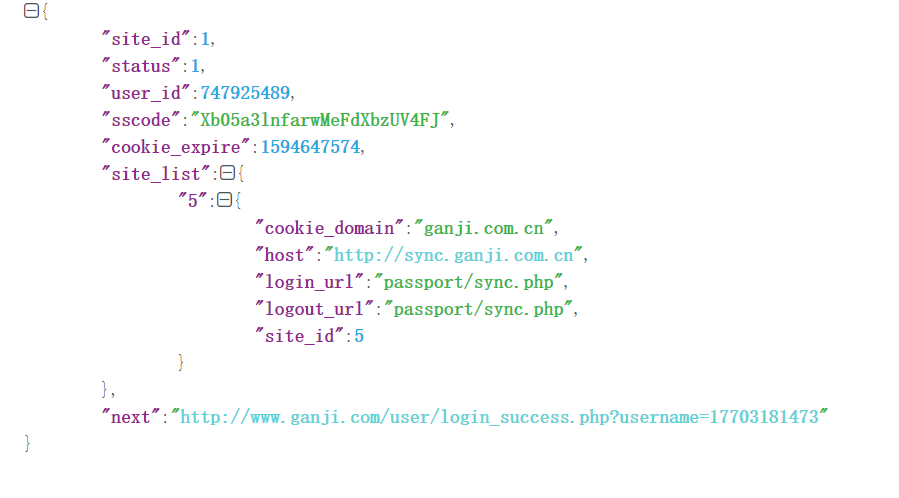
注:setting中的设置不在赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号