
论文阅读 | Multimodal Transformer Networks for End-to-End Video-Grounded Dialogue Systems
论文地址 :https://www.aclweb.org/anthology/P19-1564/
作者: Hung Le, Doyen Sahoo, Nancy Chen, Steven Hoi
机构 :Singapore Management University, Institute of Inforcomm Research, Salesforce Research Asia
研究的问题:
关注的是基于视频的对话系统。当前常用的是RNN+attention+seq2seq。这里举了一个例子:

本文提出了MTN(Multimodal Transformer Networks)对视频帧中的信息进行建模,包括了视频、字幕等信息。,整合不同形式的信息。任务是在给定的视频(包含图像和语音)的基础上,根据视频内容,视频标题,和已有的对话语句,来生成最合适的回复。
研究方法:
任务定义:给定视频V,标题C,t-1轮对话,每轮都包括一对QA,当前轮的问题Q_t,目标是生成回复A_t。
模型的整体框架如下图所示。
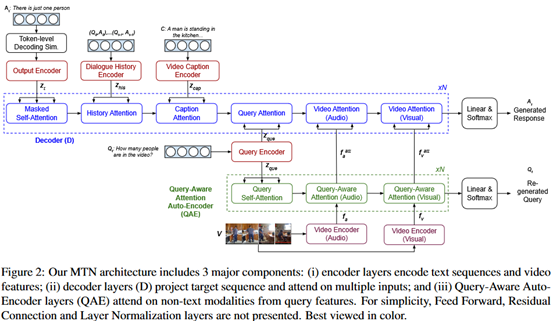
编码器:
(1)文本编码:和原始transformer相同,token embedding + position embedding,位置编码同样使用三角函数。不同的是,这里没有使用堆叠的编码层,编码层之后只经过一个层归一化的操作。(也就是没有feed forward network)。对于query、字幕、对话历史的编码方式是相同的。
(2)视频编码:使用一个n帧的滑动窗口来提取特征,特征包括图像和声音两个部分。通过一个线性层将维度转为与文本编码一致的维度。编码的结构如下图所示。

解码器:
包括n个相同的层,每层都是4+M个子层,每个子层都包含一个 multi-head attention 机制加一个 position-wise 的feed-forward层,来处理一个特定的编码输出,包括:目标序列的偏移,对话历史,视频标题,当前的query和视频中的非文本特征。(M对应的是非文本特征,在本文是使用的是视频和音频,也就是2。4对应的就是前边四个输出。)在attention的计算中使用了层归一化和残差连接。公式表示如下:

Auto-encoder:
这一层的目的是为了进一步加强视频中的非文本特征和当前的query之间的关系。包含N个层,每个层包括1+M个子层(这里的M同样是表示非文本特征,也就是两层,1对应的是query的编码)。query经过之前的编码层后,再经过一个 Self-Attention 模块,得到 query 自身的编码表示;视频中的图像和音频信息,与 query 编码分别进入 multi-attention 模块,得到视频特征中的 query-aware 编码表示。公式表示如下:
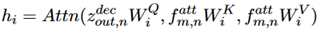
Simulated Token-level Decoding:
为了减少训练和测试时的差异,在测试的时候做以下操作:以一定的概率在某个位置(位置在2,…,L-1中均匀产生),将目标序列剪开,将剪开后左边的序列作为目标序列。
目标函数:
模型目标函数是目标序列的损失和auto-encoder的损失之和。
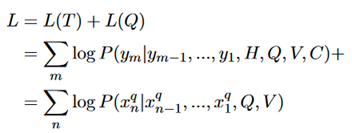
实验结果:
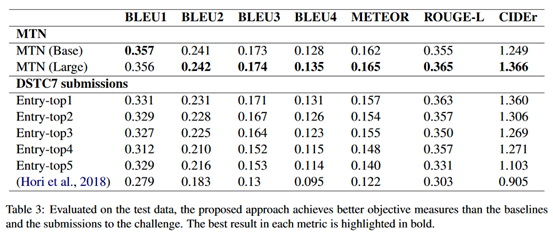
这里base/large是作者训练的两种规模的模型,可以看到结果有一定提升。
作者还做基于图片的对话任务上进行了实验,数据集是COCO。结果如下:
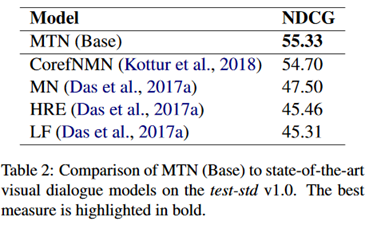
同样取得了很好的效果。
评价:
提供了一种组合文本特征和非文本特征的方式,从结果来看取得了比较好的效果。整体模型是基于transformer的,加入了一个auto-encoder来结合目标(回答query)进一步强化attention。文章的重点是介绍文本信息和非文本信息的结合方式,对于各自的信息提取(比如word embedding和feature extractor)没有做讨论,可能是一个改进的方向。
