

论文阅读 | Pre-Learning Environment Representations for Data-Efficient Neural Instruction Following
论文地址 : https://arxiv.org/abs/1907.09671?context=cs.LG
研究的问题:
神经网络复杂强大的表达能力是以牺牲了数据效率为代价的,本文要做的就是以半监督的方式预先学习抽象的知识,将神经网络的表达能力和逻辑形式的数据效率结合起来。

如上图所示,模型经过两个阶段的学习,第一阶段从环境中学习,第二阶段结合指令/语言学习。
研究方法:
主要处理可以将指令映射到基于环境状态的操作的这类问题。即学习映射 ,其中s是环境状态,c是自然语言形式的命令。
,其中s是环境状态,c是自然语言形式的命令。
网络包括两个部分,语言模型L,动作解码器D。L和D之间的接口是向量a。
Environment learning:在这个阶段,训练一个conditional autoencoder,包括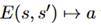 和
和 。E和D都获得初始状态s,E为终点状态
。E和D都获得初始状态s,E为终点状态 产生一个向量表示,让D来再次产生它。总体的训练用极大似然估计如下:
产生一个向量表示,让D来再次产生它。总体的训练用极大似然估计如下:
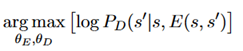
Language learning:对于给定的状态转换对 ,L作为编码器,D作为解码器,共同组成编码器-解码器结构。为了提高泛化能力,D被预训练过。如果D对于不同状态有良好的泛化能力,那么组成的函数
,L作为编码器,D作为解码器,共同组成编码器-解码器结构。为了提高泛化能力,D被预训练过。如果D对于不同状态有良好的泛化能力,那么组成的函数 也将有很好的泛化能力。语言模块L通过对D求微分来最大化它输出正确状态的概率来训练,公式表示如下:
也将有很好的泛化能力。语言模块L通过对D求微分来最大化它输出正确状态的概率来训练,公式表示如下:
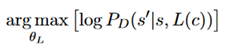
离散动作表示:网络的一个变体,使用离散的表示法表示a。具体操作是将a分成n个不同的离散随机变量。使用Gumbel-softmax来训练。
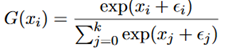
其中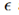 是从Gumbel(0,1)分布中采样得到的,x表示每个类别未归一化的对数概率。
是从Gumbel(0,1)分布中采样得到的,x表示每个类别未归一化的对数概率。
编码器表示匹配:从环境学习到语言学习可能遇到的一个问题是,语言模块L可能选择在环境学习期间编码器没有使用的部分动作表示空间。解决的思路是添加额外的损失项,来鼓励语言模块L产生编码器E输出的状态分布。设C为输入,s,s‘是语言模块的状态,公式表示如下:
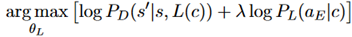
实验部分:
实验是块堆积的任务,通过在环境中添加或删除块来将开始状态转化为目标状态。实验结果如下:

可以看到,相比于baseline有不少提升,这里的baseline是没有环境学习部分的一个网络,但是相较于人类设计的系统仍有一定差距。
评价:
论文的实验不是那么的convincing,baseline是去掉了模型的第一阶段的训练的结果,不如加上第一阶段的结果是很显然的一个结论。和人工设计的系统差距还是比较明显的,并没有很好地体现出来它的效果。模型的适用范围也比较有限,仅适用于那种可以将指令映射到基于环境状态的操作的问题,比如字符串的匹配。
