
论文阅读 | Text Categorization by Learning Predominant Sense of Words as Auxiliary Task
论文地址:https://www.aclweb.org/anthology/P19-1105/
研究的问题:
关注的是结合语义的文本分类问题,以往的研究,比如用word2vec的方法,是将单词映射到一个隐空间中。但是word2vec对于一个单词,它的表示是固定的,所以无法解决一词多义的问题。
解决的一个思路,在限定了领域的情况下,会大大减少一词多义的情况,但仍然存在。ELMO、BERT这种也对语义建模的模型可以反映一词多义,但它们是无监督的模型,没有将每个词映射到它们所对应的领域。
总体来说,模型是一个多任务学习模型,在完成文本分类任务的同时,预测每个单词的主要含义。
研究方法:
主要框架如下图所示。
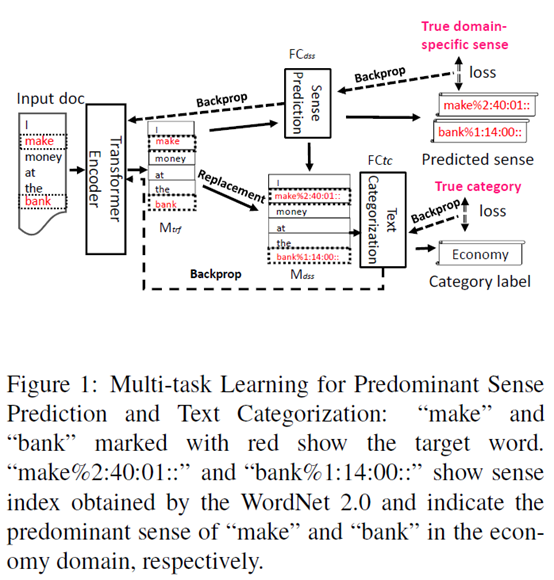
可以看到,文本的编码使用transformer,取encoder的输出矩阵,记为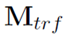
从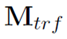 中提出需要识别领域的词,通过一个全连接层。这里其实也是一个分类任务,输出的维数是所有目标词的领域数,也是通过softmax输出结果。
中提出需要识别领域的词,通过一个全连接层。这里其实也是一个分类任务,输出的维数是所有目标词的领域数,也是通过softmax输出结果。
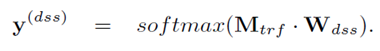
在得到了分类结果之后,在 替换相应的单词向量,得到
替换相应的单词向量,得到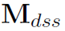 。
。
将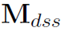 中所有向量合并得到一个文档向量,将它通过一个全连接层得到最终的分类结果。
中所有向量合并得到一个文档向量,将它通过一个全连接层得到最终的分类结果。
最终的损失函数如下:
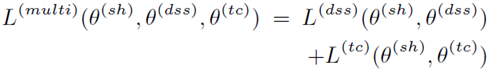
评价:
做的是一个有监督的情况下得到句子的向量表示,用于文本分类任务。对于多义词,使用有监督的模型得到它的领域和语义表示。也是一种很好的思路。之前看到过一篇做有监督的关键词提取的论文,也是用有监督的方法替换一般的用无监督方法得到的东西。不过本文只在文本分类上进行了实验,没有在其他NLP任务的实验结果。也没有跟BERT、ELMO这样的模型比,只是放在了future work当中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号