

论文阅读 | Categorical Metadata Representation for Customized Text Classification
论文地址:https://www.aclweb.org/anthology/Q19-1013/
研究的问题:
主要关注的是有附加信息的文本分类问题,比如使用用户/产品信息进行情感分类,实现自定义化的文本分类任务。比如可以提供用户信息来定制分类器,也可以向分类器提供特定于文本的类别列表来预测分类。框架如下图所示。
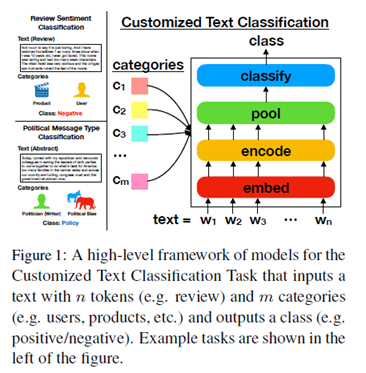
同时,作者通过对多个数据集的实验证明,使用当下流行的一些方法甚至比简单地连接文本和类别特征向量更差,认为之前的研究结果是无效的。原因在于模型在学习时使用的分类特征在稠密向量表示的优化方面存在问题。
因此作者提出了使用低维向量来缓解分类特征的优化问题,同时减少了训练参数的数量。
研究方法:
问题定义:给定文本t={W,C},其中W={w1,w2,…,wn},C={c1,c2,…,cm},目标是优化映射函数f(W)来预测一个标签y。W作为输入文本,C作为分类类别。
基本分类器:使用BiLSTM作为分类模型,将C作为偏置向量加入其中。公式如下:
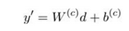
Baseline:为了将类别合并到分类器中,直接将类别特征和文档向量d连接起来,具体做法是为不同的类别创建向量空间,得到类别向量c1,c2,…,将连接之后的向量作为特征向量。
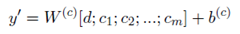
定制模型:定制Bi-LSTM。在baseline1中的方法虽然将类别作为了附加信息加入到分类器中,但它没有利用文本和类别的一些依赖关系。比如说,预测一篇论文的接受率时,考虑到领域是NLP,分类器应更多地关注于NLP单词,较少地关注不相关的单词。下面分别介绍5种定制方法。
1、在偏置向量上的自定义。比如对一个政治家所写的信息进行分类时,他可能偏向于去写个人信息而非政策信息。具体是给每个类别使用额外的多重偏置向量替换掉单一的偏置向量。
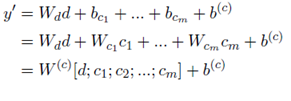
2、在线性转换上的自定义。比如在情感分析任务中,如果一个用户不喜欢糖果,那么评估“The food is very sweet”就是一个负面的情绪。具体是给每个类别使用不同的权重矩阵,而非单一的权重矩阵W(c)。
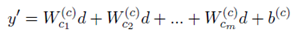
3、对attention的自定义。比如对一篇论文分类时,如果领域是NLP,那么NLP的相关词汇应该得到更多的注意力。具体是给每个种类使用不同的上下文向量。

4、对编码器权重的自定义。比如对于“deep learning for political message classification”,当研究领域是政治时,应忽略其他词的语义。具体是给每个LSTM使用多个权重,每个类别使用一个权重向量。
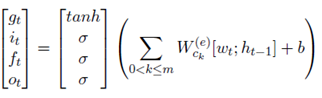
5、对词嵌入的自定义。比如用户可能使用“terribly”这个词作为积极的副词,而不是一个消极的词语。具体是添加了一个基于使用类别特征权重的词向量的非线性变化计算出的向量。
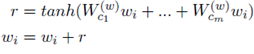
其图示如下:
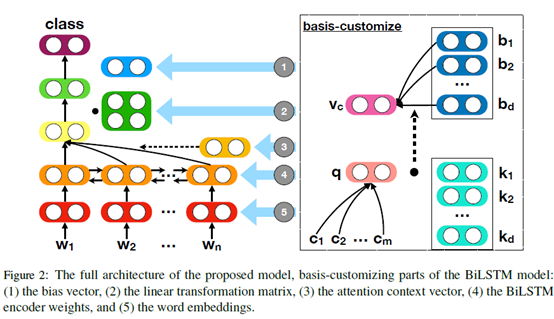
上述方法存在的问题在于,需要训练更多的权重,但分类信息本身是孤立的,在种类较多的时候需要引入大量参数,难以训练。解决的方法是使用基向量来生成自定义权重,具体是训练d个基向量,d<<原始权重的维数,由于d较小,从而将搜索空间限制为一个较小的向量空间,更快地找到最优值。
具体做法,设B={b1,b2,…bd}为一组基向量,d为基向量的个数,Vc为最佳权重的向量控开关及,则可以通过来表示。参数的训练由下面的式子得到:
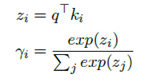
实验结果:
实验分别在三个数据集上进行,Yelp 2013,评论情感分析数据集;AAPR,论文接受率数据集;PolMed,政治信息分类数据集。实验结果如下:

评价:
研究的是附加信息的文本分类问题。方法是通过定制化的模型实现,分别在模型的5个地方实现定制,在一定程度上也加强了网络的可解释性。而通过基向量的引入减少了定制所需要的参数量。文中也用了许多例子和分析来展示他们idea的有效性。
