

论文阅读 | Heuristic Authorship Obfuscation
论文地址:https://www.aclweb.org/anthology/P19-1104/
已有研究工作:
修改一篇文章的作者风格尚未有很可靠的方法,基于规则的方法不够灵活,也没有针对特定作者足够的规则集,基于单语机器翻译缺乏足够数据集,循环使用多语翻译的方法已经被证明是无效的,同时,这些方法缺少对文本质量的控制。
本文的工作和创新点:
关注的是作者身份验证的问题,也就是看两段文本是否同一个作者编写。本文的主要工作分为两个部分:将写作风格的差异性建模为n-gram之间的Jensen-Shannon距离;使用启发式搜索修改作者的写作风格。在文章变化最小的前提下,使用作者身份混淆方法击败验证方法。
研究方法:
首先从验证的角度来处理混淆问题:给定同一作者的文章,其中一篇文章是该作者所写,但不为公众所知。目标是改写这篇文章使验证方法失效。
为了知道何时停止混淆文本,需要测量文本之间的距离,当距离超过一定阈值时,就可以停止模糊处理程序了。这里使用的是字符的三元组的频率来表示文本,这包含了词汇、标点、词法等特点,使用Kullbach-Leibler divergence(KLD)作为风格距离度量,公式如下:
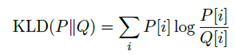
其中,P、Q分时是待处理文本和已知文本中对应字符三元组的离散概率分布。
KLD本身存在一些问题,比如它是不对称,作者的改进方法是使用一个对称的Jensen-Shannon散度(JSD)。定义如下:
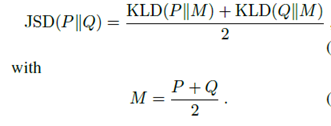
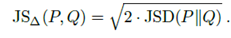
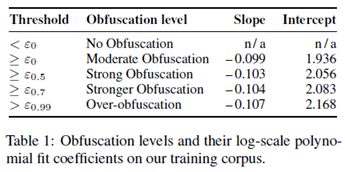
在实验中作者发现,一个固定的阈值不能胜任。通过实验发现,它和文本的长度呈反比,如下图所示。
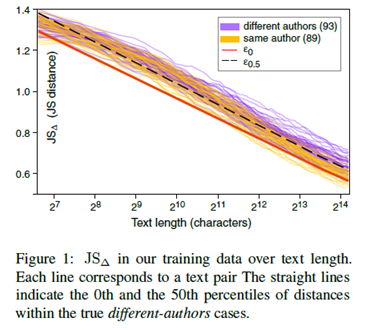
因此,具体的阈值定义如下:
在前边已经定义了JSD散度用来衡量文本间的距离,通过求导可以对于三元组的影响长度排序,公式如下:
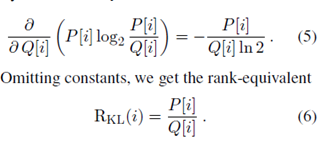
那么,一个简单的、基于贪心思想的混淆步骤就可以归结为,删除导数值最大的三元组,直到达到阈值,但这样很容易被逆向,含义也有可能被改变,因此需要合理的搜索策略。
在本文替换策略上,有以下三个目标:
1、对于每个词项,在不影响整体的前提下最大化它的JSD。
2、尽可能减少意译带来的文本质量损失。
3、最小化文本操作的数量。
设h(n)为达到期望的阈值的搜索的最优代价,设g(n)为从原始文本节点s到n的路径代价。定义操作符和它们对应的代价如下:

对应的公式如下:
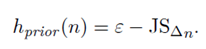

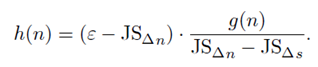
使用启发式的搜索策略代替基于贪心的搜索策略。
实验结果:
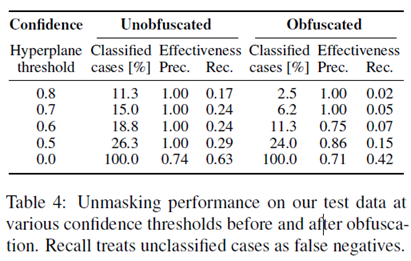
一个对文本修改的实际例子:

评价:
首先通过定义JSD散度来衡量两个文本之间的距离,再制定启发式搜索算法来对文章修改。这个过程其实还是有不少可以改进的地方,比如由于搜索空间较大,作者使用介于深度和广度搜索之间的方法来提高搜索效率,在这个过程中使用了一些未经验证的假设。不过本文在实验的评估部分还是比较详细的。
