

论文阅读 | Learning Neural Sequence-to-Sequence Models from Weak Feedback with Bipolar Ramp Loss
论文地址: https://arxiv.org/abs/1907.03748
已有研究工作:
已有的研究工作主要关注完全监督情况下的问题,如有对应文本的机器翻译,在弱监督领域研究较少,往往使用结构化的预测目标。
本文的创新点:
本文主要研究的是从弱反馈中提取输出结构监控信号的方法。也就是对于不依赖于BLEU、F-score这样的指标的任务,如提出的答案和正确的答案匹配来指导语义解析器进行正确的解析的任务,将提出的翻译与链接文档匹配来指导机器翻译中的学习的任务。在这样的情况下,外部度量的判断可能不可靠,因此无法选择良好的更新方向,而直观上,一个更可靠的信号可以通过微弱的正反馈来鼓励好的输出,并积极地阻止坏的输出。也就是通过这种方式,系统可以更加有效地了解什么是好的输出,什么是坏的输出。本文在机器翻译和语义解析这两个较弱的监督任务上,采用了多个坡道损失函数(ramp loss)在神经模型中。
研究方法:
Ramp loss的目标函数如下:
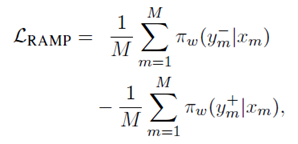
公式当中,M是mini batch的大小,y-是坏的输出(fear),需要被阻止,y+是好的输出(hope),需要被鼓励。这个损失函数将fear和hope结合在一个目标函数中。
另外本文提出了一个token级别的损失函数如下:
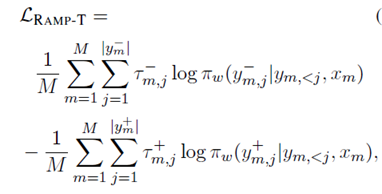
其中的t-和t+被设置为0,1,或1.具体定义如下:
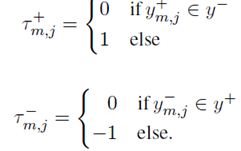

具体应用:
语义解析:语义解析也就是把自然语言问题映射到机器可读的解析中,这个解析在返回答案a的数据库上执行,通过比较输出的答案与正确的答案得到,指标如下:
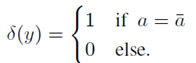
在这里,y+就是令函数等于1的答案,y-就是令函数等于0的答案。
弱监督机器翻译:弱监督机器翻译也就领域内的引用不可用的机器翻译,通过将输出与跨语言链接的文档匹配来获得弱反馈。对于每个输入的句子x,可以获得一组相关的文档D,D是目标语言文档的集合,本文通过维基百科文档之间的链接获得。不同于语义解析中的任务奖励,这里使用在0到1之间的连续的任务奖励。在完全监督的机器翻译中,可以通过BLEU分数作为奖励,但是计算翻译和文档之间的BLEU分数是没有意义的。因此本文提出了两个替代指标如下:
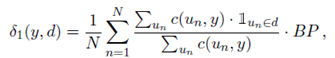
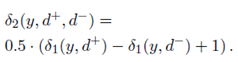
第一个指标是为了计算如何翻译匹配相关的文档,第二个指标是为了计算如何区分相关和不相干的文档。具体地,第一个公式中通过比较翻译和文档之间的n-gram的精度,其中BP作为惩罚项存在。而第二个公式在第一个公式的基于上做了线性变换。
综合评价:
同样是关注端到端学习。本文的切入点是在弱反馈任务中的损失函数问题,设计了两种基于ramp函数的损失函数。本文的论述跟实验还是非常详细的,另外本文的损失函数同样可以用在全监督的翻译任务中,同样取得了很好的效果。
