
Practical Lessons from Predicting Clicks on Ads at Facebook
ABSTRACT
这篇paper中作者结合GBDT和LR,取得了很好的效果,比单个模型的效果高出3%。随后作者研究了对整体预测系统产生影响的几个因素,发现Feature(能挖掘出用户和广告的历史信息)+Model(GBDT+LR)的贡献程度最大,而其他因素(数据实时性,模型学习速率,数据采样)的影响则较小。
1. INTRODUCTION
介绍了先前的一些相关paper。包括Google,Yahoo,MS的关于CTR Model方面的paper。
而在Facebook,广告系统是由级联型的分类器(a cascade of classifiers)组成,而本篇paper讨论的CTR Model则是这个cascade classifiers的最后一环节。
2. EXPERIMENTAL SETUP
作者介绍了如何构建training data和testing data,以及Evaluation Metrics。包括Normalized Entropy和Calibration。
Normalized Entropy的定义为每次展现时预测得到的log loss的平均值,除以对整个数据集的平均log loss值。之所以需要除以整个数据集的平均log loss值,是因为backgroud CTR越接近于0或1,则越容易预测取得较好的log loss值,而做了normalization后,NE便会对backgroud CTR不敏感了。这个Normalized Entropy值越低,则说明预测的效果越好。下面列出表达式:
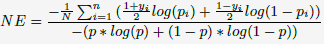
Calibration的定义为预估CTR除以真实CTR,即预测的点击数除以真实观察到的点击数。这个值越接近1,则表明预测效果越好。
3. PREDICTION MODEL STRUCTURE
作者介绍了两种Online Learning的方法。包括Stochastic Gradient Descent(SGD)-based LR:

和Bayesian online learning scheme for probit regression(BOPR):
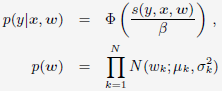
BOPR每轮迭代时的更新公式为:
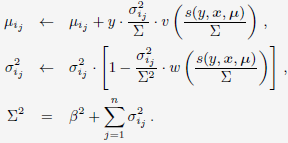
3.1 Decision tree feature transforms
Linear Model的表达能力不够,需要feature transformation。第一种方法是对连续feature进行分段处理(怎样分段,以及分段的分界点是很重要的);第二种方法是进行特征组合,包括对离散feature做笛卡尔积,或者对连续feature使用联合分段(joint binning),比如使用k-d tree。
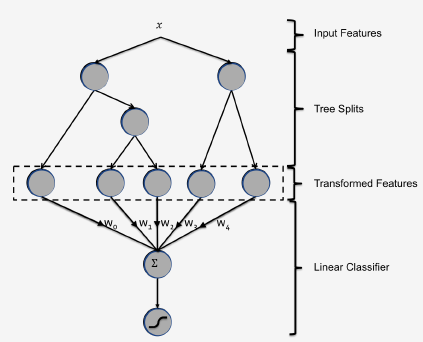
而使用GBDT能作为一种很好的feature transformation的工具,我们可以把GBDT中的每棵树作为一种类别的feature,把一个instance经过GBDT的流程(即从根节点一直往下分叉到一个特定的叶子节点)作为一个instance的特征组合的过程。这里GBDT采用的是Gradient Boosting Machine + L2-TreeBoost算法。这里是本篇paper的重点部分,放一张经典的原图:
3.2 Data freshness
CTR预估系统是在一个动态的环境中,数据的分布随时在变化,所以本文探讨了data freshness对预测效果的影响,表明training data的日期越靠近,效果越好。
3.3 Online linear classifier
探讨了对SGD-based LR中learning rate的选择。最好的选择为:
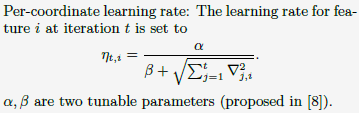
1)global效果差的原因:每个维度上训练样本的不平衡,每个训练样本拥有不同的feature。那些拥有样本数较少的维度的learning rate下降过快,导致无法收敛到最优值。
2)per weight差的原因:虽然对于各个维度有所区分,但是其对于各个维度的learning rate下降速度都太快了,训练过早结束,无法收敛到最优值。
SGD-based LR vs BOPR
1)SGD-based LR对比BOPR的优势:
1-1)模型参数少,内存占用少。SGD-based LR每个维度只有一个weight值,而BOPR每个维度有1个均值 + 1个方差值。
1-2)计算速度快。SGD-LR只需1次内积计算,BOPR需要2次内积计算。
2)BOPR对比SGD-based LR的优势:
2-1)BOPR可以得到完整的预测点击概率分布。
4 ONLINE DATA JOINER
Online Data Joiner主要是用于在线的将label与相应的features进行join。同时作者也介绍了正负样本的选取方式,以及选取负样本时候的waiting time window的选择。
5 CONTAINING MEMORY AND LATENCY
作者探讨了GBDT中tree的个数,各种类型的features(包括contextual features和historical features),对预测效果的影响。结论如下:
1)NE的下降基本来自于前500棵树。
2)最后1000棵树对NE的降低贡献低于0.1%。
3)Submodel 2 过拟合,数据量较少,只有其余2个模型的约四分之一。
4)Importance为feature带来的累积信息增益 / 平方差的减少
5)Top 10 features贡献了将近一半的importance
6)最后的300个features的贡献不足1%
6 COPYING WITH MASSIVE TRANING DATA
作者探讨了如何进行样本采样的过程,包括了均匀采样(Uniform subsampling),和负样本降采样(Negative down sampling),以及对预测效果的影响。
版权声明:
本文由笨兔勿应所有,发布于http://www.cnblogs.com/bentuwuying。如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号