编码
为什么会有编码,以及编码的发展历程?
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为”字节“。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为”计算机“。
这八个开合的晶体管的随机组合得到了256种不同的状态,所以得到了不通的字节
一个或多个字节的组合,我们称为字符

根据组成字符字节数据的不同,有不同的编码方式:ASCII Unicode UTF-8 GBK GBK-2312等
使用字符编码如何操作计算机?
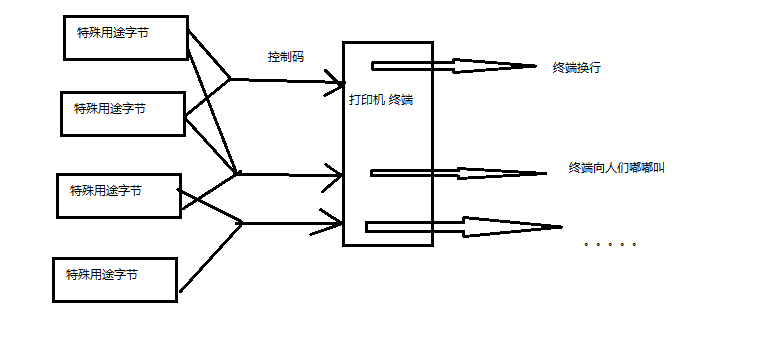
遇上0×10, 终端就换行;
遇上0×07, 终端就向人们嘟嘟叫;
遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母。
人们看到这样很好,于是就把这些0×20以下的字节状态称为”控制码”。
ASCII的出现
GBK的出现
背景:出现:
Unicode的出现
UTF-8的出现
背景: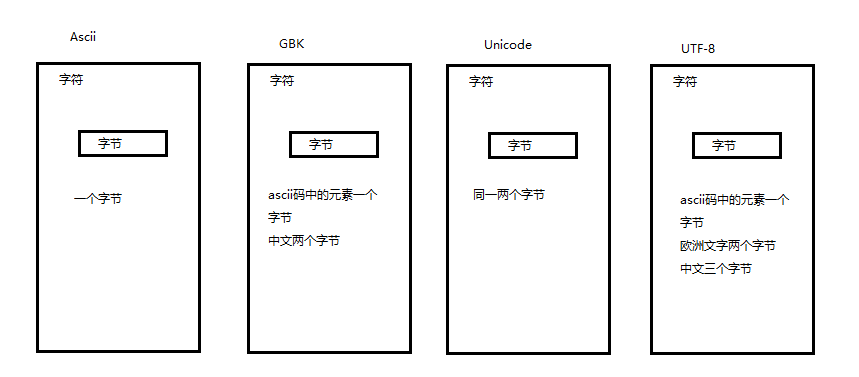
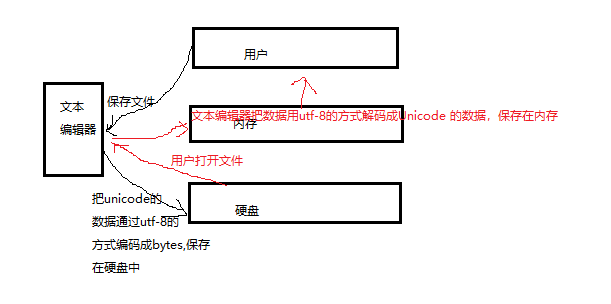
文件从磁盘到内存的编码(******)
python2与python3的编码方式
python2默认编码方式:ASCII
python3默认编码方式:UTF-8
python2与python3的字符串类型
python2 str == python3 bytes
python2 unicode == python3 str
常见的编码问题
1 cmd下的乱码问题
原因:
我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身也一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print'苑昊'时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe用来显示,而在py2里这个内容就是utf8编码的字节数据,可这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,cmd.exe可以识别内容,所以显示没问题。
解决方法:print (u'苑昊')
2 open()中的编码问题
原因:
因为你的win的操作系统安装时是默认的gbk编码,而linux操作系统默认的是utf8编码;
当执行open函数时,调用的是操作系统打开文件,操作系统用默认的gbk编码去解码utf8的文件,自然乱码。
解决方法:指定utf-8解码方式
字节码和机械码
机械码:由0,1组成的二进制代码,这种类型的代码即称为机器码,机器码是计算机可以直接执行的、速度最快的代码
python的字节码:
当我们运行python文件程序的时候,Python解释器将源码转换为字节码,然后再由解释器来执行这些字节码。
执行流程:
-
完成模块的加载和链接;
-
将源代码翻译为PyCodeObject对象(这货就是字节码),并将其写入内存当中(方便CPU读取,起到加速程序运行的作用);
-
从上述内存空间中读取指令并执行;
-
程序结束后,根据命令行调用情况(即运行程序的方式)决定是否将PyCodeObject写回硬盘当中(也就是直接复制到.pyc或.pyo文件中);
-
之后若再次执行该脚本,则先检查本地是否有上述字节码文件。有则执行,否则重复上述步骤。

字节码文件:文件名以.pyc结尾,或许你已经听说过它们就是Python的“字节码”文件。(但在Python 3上却难觅其踪 -- 原因是它们不再与.py文件出现在同一个目录中,而是放在一个名为__pycache__的子目录中了)。或许你也已听说过这是一种程序加速机制。通过防止Python每次运行时都重新解析源代码从而加快程序运行。一般py文件改变后,都会重新生成pyc文件。
主动生成pyc文件:
为什么?主要是不想把源代码暴露出来。
生成单个
1 python -m foo.py
2 import py_compile
py_compile.compile('/path/to/foo.py')
批量生成pyc文件
import compileall
compileall.compile_dir(r'/path')
参考:https://www.cnblogs.com/575dsj/p/7112767.html
https://www.zhihu.com/question/23374078/answer/69732605
https://blog.csdn.net/m0_37550221/article/details/78907972

 浙公网安备 33010602011771号
浙公网安备 33010602011771号