线上系统/tmp 目录不断增长分析与总结
1、问题描述
系统配置为单核4G, web 工程配置堆2G, /tmp目录 二进制文件不断增加,平均一天增加20G, 手动清理/tmp目录,重启系统,问题依旧。
2、分析
2.lsof -p pid 确定tmp文件都被进程id为10791的同一个Java进程打开。

根据上面的分析,这些文件应该是该进程的临时文件,而且不断在增加,有可能是文件句柄泄露。
查看该进程的句柄图

12.15号,系统打开的句柄数量在逐步的增加,而且没有出现相对平稳的迹象,确定是句柄泄露了,这印证了我们的猜想。
下来需要进一步分析究竟是什么原因造成的句柄泄露。
谷歌搜索关键字,确定FlateDecode是解码 PDF stream 的一个工具。查看程序中引用相关pdf的代码,如下图所示:
public static byte[] transfer(byte[] bytes, int pageNum) throws IOException {
LOG.info("PDF合同转IMAGE开始...pageNum={}", pageNum); PdfDecoder decode_pdf = new PdfDecoder(true);
decode_pdf.scaling = 1.5F; FontMappings.setFontReplacements(); byte[] outbytes = new byte[0];
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
decode_pdf.openPdfArray(bytes); //bytes is byte[] array with PDF BufferedImage img = decode_pdf.getPageAsImage(pageNum); ImageIO.write(img, "jpg", out); outbytes = out.toByteArray(); LOG.info("PDF合同转IMAGE成功...pageNum={}", pageNum); } catch (Exception e) {
LOG.error("PDF合同转IMAGE异常...pageNum={},e={}", pageNum, e); } finally {
out.close(); } return outbytes;
} |
这段代码用来将pdf转化成一个jpg的图片,使用了jpedal第三方库。
jpedal是一个开源的纯Java的PDF文档解析库,可以用来方便的查看和编辑文字和图片。
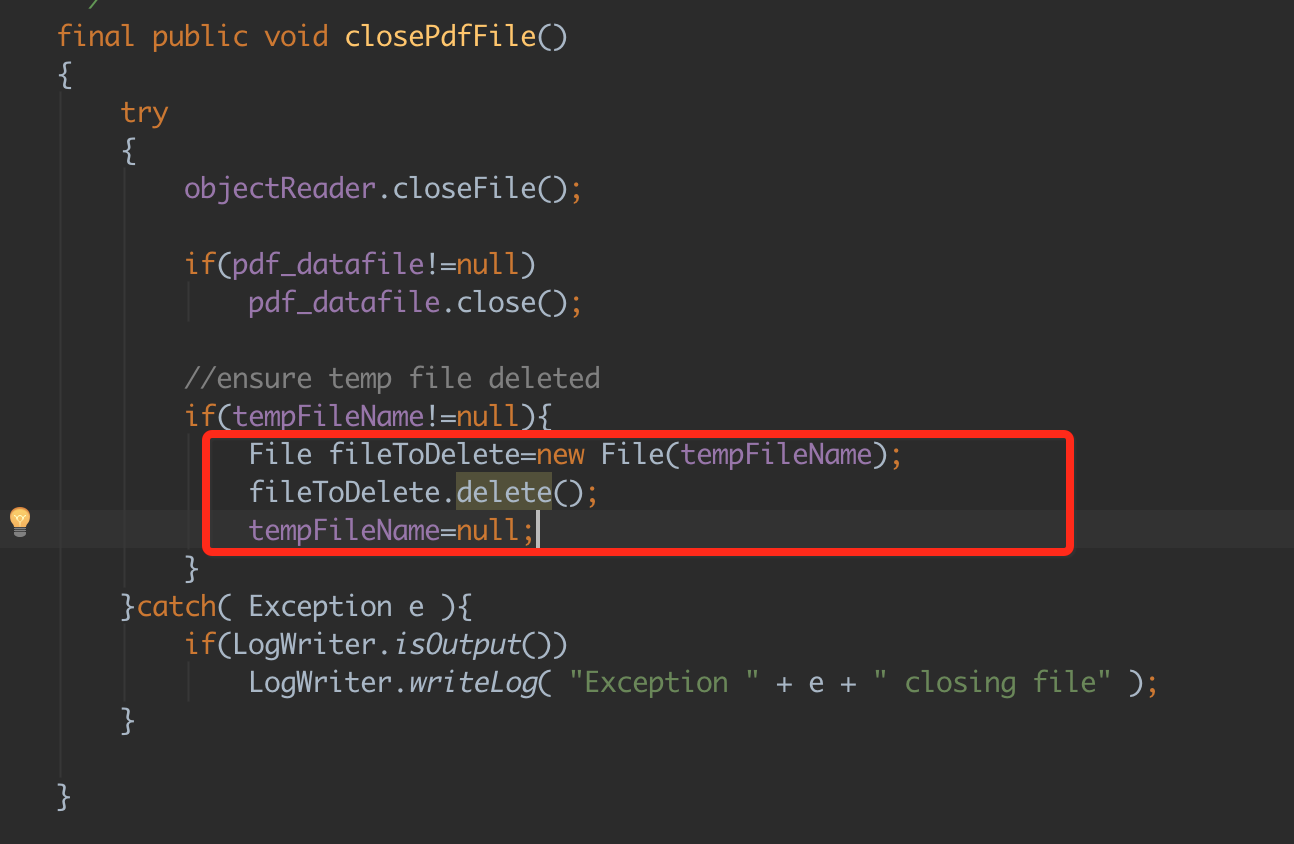
回到代码, 按照以往编码的经验,有可能是PdfDecoder没有释放资源,导致生成的临时文件一直没有释放掉。查看jpedal文档,发现的确提供了closePdfFile 关闭pdf文件的方法。
finally 块里添加
decode_pdf.flushObjectValues(true);
decode_pdf.closePdfFile();
重新发版,发现之后句柄图达到了相对平稳的状态,tmp目录也不再继续增加临时文件。
虽然问题解决了,但是还有一些困惑。临时文件怎么生成的?page fault为啥这么多?
1、临时文件到底是怎么生成的?
decode_pdf.openPdfArray(bytes) 根据传进来的字节流 打开pdf文件,

jpedal在这里做了一个优化,当pdf文件小于16k时或者alwaysCacheInMemory = -1时,直接内存缓存该pdf。
当pdf文件的大小大于16k时,会在临时目录下生成一个前缀为page,后缀为bin的二进制文件,该临时目录由系统参数 java.io.tmpdir 指定,默认在/tmp目录下。
这样,由于线上环境的pdf基本都大于16k,所以/tmp目录下就会看到不断的临时文件生成。这个临时文件命名规则为page***.bin。
2、添加closePdf文件之后,为啥问题就解决了呢?
closePdf会调用PdfReader的closePdfFile()方法,该方法根据缓存的临时文件名称删除该临时文件。
3、未关闭pdf文件,为啥会引起较多的page fault呢?
page fault 分为 minor page fault 和major page fault。
major page fault也称为hard page fault, 指需要访问的内存不在虚拟地址空间,也不在物理内存中,需要从慢速设备载入。从swap回到物理内存也是hard page fault。
minor page fault也称为soft page fault, 指需要访问的内存不在虚拟地址空间,但是在物理内存中,只需要MMU建立物理内存和虚拟地址空间的映射关系即可。
(通常是多个进程访问同一个共享内存中的数据,可能某些进程还没有建立起映射关系,所以访问时会出现soft page fault)
正常情况下,系统也会有一些pagefault,如下图所示:

,所以pagefault和该问题没有直接关系。minflt表示从内存加载数据时每秒出现的小的错误数目,可以忽略。如果majflt较大,表示从磁盘载入内存页面,发生了swap,此时需要关注。
3、总结
我们详细的回顾了此次线上发生的问题,以及如何去定位,然后去解决问题的整个过程。
(1)问题发现,收到系统磁盘空间不足的报警。
(2)问题定位,先根据du确认是tmp目录增长过快的问题,然后根据lsof和进程句柄图确定是文件句柄泄露,再根据临时文件的文件内容,定位相关的源代码,查看源代码,确认是文件句柄资源没有正确释放。
(3)解决问题,查看api,确认是资源泄露的问题,修复代码上线。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号