

python 3.0读取文件出现编码错误(illegal multibyte sequence )
代码如下:
myfile2=open('e:/enterprise.xlsx',mode = 'r')
file2_content=myfile2.readlines()
print(file2_content)
执行时报错信息如下:illegal multibyte sequence

尝试解决方式一:添加编码方式:gb18030,失败
myfile2=open('e:/enterprise.xlsx',encoding = 'gb18030',mode = 'r') #添加编码方式:gb18030
file2_content=myfile2.readlines()
print(file2_content)

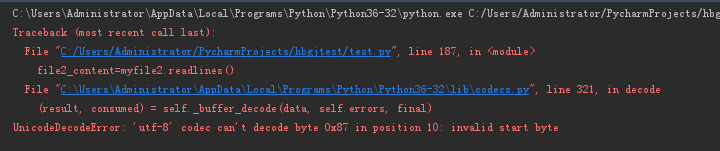
尝试解决方式二:编码方式调整为:uft-8,失败
myfile2=open('e:/enterprise.xlsx',encoding = 'utf-8',mode = 'r') #编码方式调整为:uft-8
file2_content=myfile2.readlines()
print(file2_content)
尝试解决方式二:errors 忽略,失败
myfile2=open('e:/enterprise.xlsx',mode = 'r',errors = 'ignore') #errors 忽略
file2_content=myfile2.readlines()
print(file2_content)
执行后,不报错了,但是文件内容被解析为乱码。

该问题未解决?

