MIT 6.1810 Lab: Multithreading
lab网址:https://pdos.csail.mit.edu/6.828/2022/labs/cow.html
xv6Book:https://pdos.csail.mit.edu/6.828/2022/xv6/book-riscv-rev3.pdf
schedule代码分析
scheduler在内核初始化的最后调用,内核初始化由main函数承担,运行在特权模式,main函数由start函数调用,start函数运行在机器模式。main函数会先用一个核心完成内核初始化,然后开启多CPU模式,每个核心在结束时调用scheduler。在entry.S中提到qemu会将每个核心都加载到start函数的入口处。
// start() jumps here in supervisor mode on all CPUs.
void
main()
{
if(cpuid() == 0){
consoleinit();
printfinit();
printf("\n");
printf("xv6 kernel is booting\n");
printf("\n");
kinit(); // physical page allocator
kvminit(); // create kernel page table
kvminithart(); // turn on paging
procinit(); // process table
trapinit(); // trap vectors
trapinithart(); // install kernel trap vector
plicinit(); // set up interrupt controller
plicinithart(); // ask PLIC for device interrupts
binit(); // buffer cache
iinit(); // inode table
fileinit(); // file table
virtio_disk_init(); // emulated hard disk
userinit(); // first user process
__sync_synchronize();
started = 1;
} else {
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging
trapinithart(); // install kernel trap vector
plicinithart(); // ask PLIC for device interrupts
}
scheduler();
}之后scheduler采用轮询的方法依次激活进程,swtch函数改变CPU的context,当CPU的PC、和其他寄存器都切换后,进程切换已经实质上的完成了。swtch定义在汇编文件中,将当前的context保存在a0寄存器指向的位置,即&c->context,加载新的context从a1寄存器指向的位置&p->context。
// Per-CPU process scheduler.
// Each CPU calls scheduler() after setting itself up.
// Scheduler never returns. It loops, doing:
// - choose a process to run.v
// - swtch to start running that process.
// - eventually that process transfers control
// via swtch back to the scheduler.
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}每个CPU拥有一个scheduler,scheduler的上下文储存在struct cpu -> context中。当想激活scheduler时,只需要将struct cpu中的context写入CPU。调度程序scheduler通过swtch(&c->context, &p->context);退出执行,将执行流让给新进程。
// Per-CPU state.
struct cpu {
struct proc *proc; // The process running on this cpu, or null.
struct context context; // swtch() here to enter scheduler().
int noff; // Depth of push_off() nesting.
int intena; // Were interrupts enabled before push_off()?
};sched函数用于激活调度程序,通过swtch(&p->context, &mycpu()->context);完成。sched函数切换前验证当前进程状态设置以完成。保护intena,局部变量保存在栈中,当前进程再次执行时的第一条语句为mycpu()->intena = intena;。因此用户进程的切换发生在用户进程的内核态,sched函数处。
// Switch to scheduler. Must hold only p->lock
// and have changed proc->state. Saves and restores
// intena because intena is a property of this
// kernel thread, not this CPU. It should
// be proc->intena and proc->noff, but that would
// break in the few places where a lock is held but
// there's no process.
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}Uthread: switching between threads
这个实验要求我们实现用户级的线程,用户级线程与内核线程由很多相似之处。考虑以下问题:1.何时发生调度,2.如何保存和恢复现场。内核线程每个时钟中断发生调度,将寄存器的值保存在内存中来保护和恢复现场。在xv6中,用户线程的调度可以通过程序显示调用,即thread_schedule()。每个进程的栈保存在struct thread中,线程切换同样需要更改寄存器,修改这些寄存器不需要特权模式。
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context context;
};因此可以如下设计。程序的主线程始终使用系统栈,将每个线程的栈储存在thread->stack中,主线程加载新线程时,将栈指针指向线程栈,控制流的通过ra寄存器完成。相比与内核调度,由于调度程序是被显示调用的,因此不需要保存调度程序的现场,这样调度程序也必须每次从头运行。
void
thread_schedule(void)
{
struct thread *t, *next_thread;
/* Find another runnable thread. */
next_thread = 0;
t = current_thread + 1;
for(int i = 0; i < MAX_THREAD; i++){
if(t >= all_thread + MAX_THREAD)
t = all_thread;
if(t->state == RUNNABLE) {
next_thread = t;
break;
}
t = t + 1;
}
if (next_thread == 0) {
printf("thread_schedule: no runnable threads\n");
exit(-1);
}
if (current_thread != next_thread) { /* switch threads? */
next_thread->state = RUNNING;
t = current_thread;
current_thread = next_thread;
/* YOUR CODE HERE
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
+++ thread_switch(&t->context,¤t_thread->context);
//here to pause
} else
next_thread = 0;
}thread_create函数用于创建新线程,记录线程对应的函数地址,线程栈顶,注意sp寄存器保存栈顶,栈向低地址延申,RISC-V无需栈底寄存器。
void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
t->context.ra = (uint64)func;
t->context.sp = (uint64)t->stack+STACK_SIZE;
}线程切换只需保护callee-saved,在RISC-V中,部分寄存器由调用函数保护到栈中,因此无需保护这些寄存器。
diff --git a/user/uthread.c b/user/uthread.c
index 06349f5..5bc255c 100644
--- a/user/uthread.c
+++ b/user/uthread.c
@@ -10,14 +10,34 @@
#define STACK_SIZE 8192
#define MAX_THREAD 4
+struct context {
+ uint64 ra;
+ uint64 sp;
+
+ // callee-saved
+ uint64 s0;
+ uint64 s1;
+ uint64 s2;
+ uint64 s3;
+ uint64 s4;
+ uint64 s5;
+ uint64 s6;
+ uint64 s7;
+ uint64 s8;
+ uint64 s9;
+ uint64 s10;
+ uint64 s11;
+};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
+ struct context context;
};
+
struct thread all_thread[MAX_THREAD];
struct thread *current_thread;
-extern void thread_switch(uint64, uint64);
+extern void thread_switch(struct context *, struct context *);
void
thread_init(void)
@@ -62,6 +82,8 @@ thread_schedule(void)
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
+ thread_switch(&t->context,¤t_thread->context);
+ //here to pause
} else
next_thread = 0;
}
@@ -76,6 +98,8 @@ thread_create(void (*func)())
}
t->state = RUNNABLE;
// YOUR CODE HERE
+ t->context.ra = (uint64)func;
+ t->context.sp = (uint64)t->stack+STACK_SIZE;
}
void
diff --git a/user/uthread_switch.S b/user/uthread_switch.S
index 5defb12..65eec2c 100644
--- a/user/uthread_switch.S
+++ b/user/uthread_switch.S
@@ -8,4 +8,34 @@
.globl thread_switch
thread_switch:
/* YOUR CODE HERE */
+ sd ra, 0(a0)
+ sd sp, 8(a0)
+ sd s0, 16(a0)
+ sd s1, 24(a0)
+ sd s2, 32(a0)
+ sd s3, 40(a0)
+ sd s4, 48(a0)
+ sd s5, 56(a0)
+ sd s6, 64(a0)
+ sd s7, 72(a0)
+ sd s8, 80(a0)
+ sd s9, 88(a0)
+ sd s10, 96(a0)
+ sd s11, 104(a0)
+
+ ld ra, 0(a1)
+ ld sp, 8(a1)
+ ld s0, 16(a1)
+ ld s1, 24(a1)
+ ld s2, 32(a1)
+ ld s3, 40(a1)
+ ld s4, 48(a1)
+ ld s5, 56(a1)
+ ld s6, 64(a1)
+ ld s7, 72(a1)
+ ld s8, 80(a1)
+ ld s9, 88(a1)
+ ld s10, 96(a1)
+ ld s11, 104(a1)
ret /* return to ra */Using threads
这部分希望我们利用本机完成线程的使用,解决给出代码的线程竞争问题。
pthread_create 是 POSIX 线程库中的一个函数,用于创建新的用户线程,这个函数的原型如下
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void *), void *arg);- pthread_t *thread:指向新创建的线程 ID 的指针。
- const pthread_attr_t *attr:指定线程的属性,通常传入 NULL 以使用默认属性。
- void *(*start_routine)(void *):指定新线程要执行的函数,这个函数的返回类型是 void*,接受一个 void* 类型的参数。
- void *arg:传递给 start_routine 函数的参数
pthread_join 是 POSIX 线程库中的一个函数,用于等待一个指定的线程终止,并获取该线程的退出状态。
int pthread_join(pthread_t thread, void **retval);- pthread_t thread:要等待的线程的标识符。
- void **retval:用于存储目标线程的返回值(退出状态)的指针。这是一个指向指针的指针,因为线程的返回值是一个指针类型。
- pthread_join 函数的返回值为 0 表示成功,非零值表示错误。成功调用 pthread_join 会阻塞当前线程,直到指定的线程终止。
为什么程序在多线程时,发生了异常呢。我们可以在insert中,n是表头,p指向表头,在多线程运行时,e->next = n;中的n可能已经不是当前的表头了,最后*p = e设置新表头时,就有可能漏掉了其他线程添加的表项。
static void
insert(int key, int value, struct entry **p, struct entry *n)
{
struct entry *e = malloc(sizeof(struct entry));
e->key = key;
e->value = value;
e->next = n;
*p = e;
}因此可以通过添加锁来解决这个问题。为每个剪纸桶添加一个锁,在获取表头前获取锁,设置新表头后释放。
pthread_mutex_t lock; // declare a lock
pthread_mutex_init(&lock, NULL); // initialize the lock
pthread_mutex_lock(&lock); // acquire lock
pthread_mutex_unlock(&lock); // release lockdiff --git a/notxv6/ph.c b/notxv6/ph.c
index 82afe76..5f8ab08 100644
--- a/notxv6/ph.c
+++ b/notxv6/ph.c
@@ -17,6 +17,8 @@ struct entry *table[NBUCKET];
int keys[NKEYS];
int nthread = 1;
+pthread_mutex_t locks[NBUCKET]; // declare a lock
+
double
now()
@@ -52,7 +54,9 @@ void put(int key, int value)
e->value = value;
} else {
// the new is new.
+ pthread_mutex_lock(&locks[i]); // acquire lock
insert(key, value, &table[i], table[i]);
+ pthread_mutex_unlock(&locks[i]); // release lock
}
}
@@ -117,7 +121,11 @@ main(int argc, char *argv[])
for (int i = 0; i < NKEYS; i++) {
keys[i] = random();
}
-
+ for (int i = 0; i < NBUCKET; i++)
+ {
+ pthread_mutex_init(&locks[i], NULL); // initialize the lock
+ }
+
//
// first the puts
//Barrier
这部分希望我们实现一个函数,当所有线程都调用该函数时,才可以继续进行。
pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond修改bstate时先获取锁,如果不满足条件,则调用pthread_cond_wait(&cond, &mutex);,该函数会阻塞线程并释放锁,当满足条件后,每个线程依次获取锁退出函数。
diff --git a/notxv6/barrier.c b/notxv6/barrier.c
index 12793e8..f224554 100644
--- a/notxv6/barrier.c
+++ b/notxv6/barrier.c
@@ -30,7 +30,16 @@ barrier()
// Block until all threads have called barrier() and
// then increment bstate.round.
//
-
+ pthread_mutex_lock(&bstate.barrier_mutex); // acquire lock
+ bstate.nthread++;
+ if(bstate.nthread == nthread){
+ bstate.round++;
+ bstate.nthread = 0;
+ pthread_cond_broadcast(&bstate.barrier_cond); // wake up every thread sleeping on cond
+ } else {
+ pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up
+ }
+ pthread_mutex_unlock(&bstate.barrier_mutex); // release lock
}
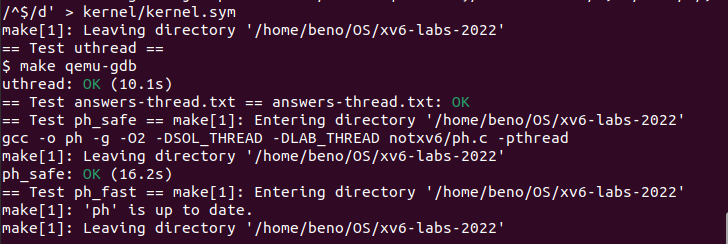
static void *结果
最后成功通过所有测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号