
python基础--常用模块
一 time与datetime模块
时间戳:计算时间用time()--float clock()
localtime:本地时间localtime --struct_time
UTC时间: gmtime --struct_time
返回struct_time的函数主要有gmtime(),localtime(),strptime()
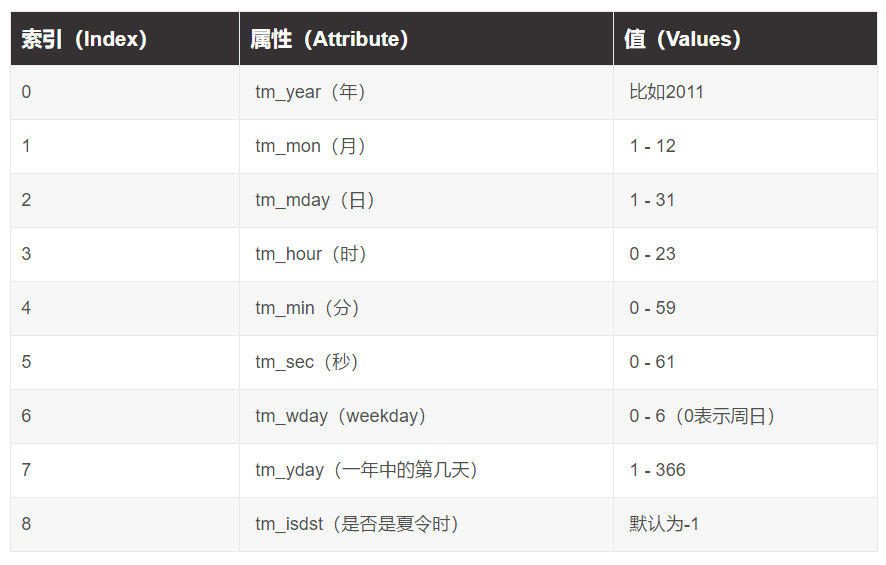
time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
time.time():返回当前时间的时间戳。
time.mktime(t):将一个struct_time转化为时间戳。
time.sleep(secs):线程推迟指定的时间运行。单位为秒。
time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
time.strptime(string[, format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
1 """ 2 datetime 3 python实现的一个时间处理模块 4 time 用起来不太方便 所以就有了datetme 5 总结 datetime相比time 更灵活 更本土化 6 7 timedelta表示时间差 8 两个时间差可以 +-*/ 9 时间差和datetime 可以+- 10 """ 11 import datetime 12 13 # 获取时间 获取当前时间 并且返回的是格式化字符时间 14 print(datetime.datetime.now()) 15 16 # 单独获取某个时间 年 月 17 d = datetime.datetime.now() 18 print(d.year) 19 print(d.day) 20 21 # 手动指定时间 22 d2 = datetime.datetime(2018,8,9,9,50,00) 23 print(d2) 24 25 # 计算两个时间的差 只能- 不能加+ 26 print(d - d2) 27 28 # 替换某个时间 29 print(d.replace(year=2020)) 30 31 # 表示时间差的模块 timedelta 32 print(datetime.timedelta(days=1)) 33 34 t1 = datetime.timedelta(days=1) 35 t2 = datetime.timedelta(weeks=1) 36 print(t2 - t1) 37 # 时间差可以和一个datetime进行加减 38 print(d + t2)
二 random模块
random.randint(1,10)语句的含义是产生1至10(包含1与10)的一个随机数(整数int型)。(参数为整数不可为浮点数否则会报错)
random.random()生成一个0到1之间的随机浮点数,包括0但不包括1,也就是[0.0, 1.0)。
random.uniform(a, b)生成a、b之间的随机浮点数。不过与randint不同的是,a、b可以不是整数,也不用考虑大小。
即
random.uniform(3.65,10.56)#可以这样
random.uniform(10.56, 3.65)#也可以这样
random.choice(seq)从序列中随机选取一个元素。seq需要是一个序列,比如list、元组、字符串。
random.randrange(start, stop, step)生成一个从start到stop(不包括stop),间隔为step的一个随机整数。start、stop、step都要为整数,且start<stop。
random.sample(p, k)从p序列中,随机获取k个元素,生成一个新序列。sample不改变原来序列。
这个模块很 666,还支持三角、β分布、指数分布、伽马分布、高斯分布等等非常专业的随机算法。
random.shuffle(x)把序列x中的元素顺序打乱。shuffle直接改变原有的序列。
三 os模块
os.getcwd() 获取当前⼯工作⽬目录,即当前python脚本⼯工作的⽬目录路路径
os.chdir("dirname") 改变当前脚本⼯工作⽬目录;相当于shell下cd
os.curdir 返回当前⽬目录: ('.')
os.pardir 获取当前⽬目录的⽗父⽬目录字符串串名:('..')
os.makedirs('dirname1/dirname2') 可⽣生成多层递归⽬目录
os.removedirs('dirname1') 若⽬目录为空,则删除,并递归到上⼀一级⽬目录,如 若也为空,则删除,依此类推
os.mkdir('dirname') ⽣生成单级⽬目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空⽬目录,若⽬目录不不为空则⽆无法删除,报错;相 当于shell中rmdir dirname
os.listdir('dirname') 列列出指定⽬目录下的所有⽂文件和⼦子⽬目录,包括隐藏⽂文件, 并以列列表⽅方式打印 os.remove() 删除⼀一个⽂文件
os.rename("oldname","newname") 重命名⽂文件/⽬目录 os.stat('path/filename') 获取⽂文件/⽬目录信息
os.sep 输出操作系统特定的路路径分隔符,win下为"\\",Linux下为"/" os.linesep 输出当前平台使⽤用的⾏行行终⽌止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出⽤用于分割⽂文件路路径的字符串串 win下为;,Linux下为:
os.name 输出字符串串指示当前使⽤用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运⾏shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路路径
os.path.split(path) 将path分割成⽬目录和⽂文件名⼆二元组返回
os.path.dirname(path) 返回path的⽬目录。其实就是os.path.split(path)的第 ⼀一个元素 os.path.basename(path) 返回path后的⽂文件名。如何path以/或\结尾, 那么就会返回空值。即os.path.split(path)的第⼆二个元素
os.path.exists(path) 如果path存在,返回True;如果path不不存在,返回 False
os.path.isabs(path) 如果path是绝对路路径,返回True
os.path.isfile(path) 如果path是⼀一个存在的⽂文件,返回True。否则返回False
os.path.isdir(path) 如果path是⼀一个存在的⽬目录,则返回True。否则返回 False os.path.join(path1[, path2[, ...]]) 将多个路路径组合后返回,第⼀一个绝对路路径之 前的参数将被忽略略
os.path.getatime(path) 返回path所指向的⽂文件或者⽬目录的后存取时间
os.path.getmtime(path) 返回path所指向的⽂文件或者⽬目录的后修改时间
os.path.getsize(path) 返回path的⼤大⼩小
# normcase ⽤用于将路路规范化 会将大写转为小写 斜杠改为当前系统分隔符 print(os.path.normcase("\\a\\b\\ABCS")) # normpath用于将路路径规范化 不仅将非法的分隔符替换为合法分隔符 还将 大写转为小写 并且会执行行..的回到上一层 print(os.path.normpath("/a/b/../ABCS"))
四 sys模块
-
sys.argv: 实现从程序外部向程序传递参数。 -
sys.exit([arg]): 程序中间的退出,arg=0为正常退出。 -
sys.getdefaultencoding(): 获取系统当前编码,一般默认为ascii。 -
sys.setdefaultencoding(): 设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 setdefaultencoding('utf8'),此时将系统默认编码设置为utf8。(见设置系统默认编码 ) -
sys.getfilesystemencoding(): 获取文件系统使用编码方式,Windows下返回'mbcs',mac下返回'utf-8'. -
sys.path: 获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。 -
sys.platform: 获取当前系统平台。 -
sys.stdin,sys.stdout,sys.stderr: stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们
五 shutil模块
主要作用与拷贝文件用的。
1.shutil.copyfileobj(文件1,文件2):将文件1的数据覆盖copy给文件2。
2.shutil.copyfile(文件1,文件2):不用打开文件,直接用文件名进行覆盖copy。
3.shutil.copymode(文件1,文件2):只拷贝权限,内容组,用户,均不变。
4.shutil.copystat(文件1,文件2):仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
5.shutil.copy(src, dst)拷贝文件和权限
6.l.copy2(src, dst)拷贝文件和状态信息
7.shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
8.shutil.rmtree(path[, ignore_errors[, onerror]])递归的去删除文件
9.shutil.move(src, dst)递归的去移动文件,它类似mv命令,其实就是重命名。
压缩与解压缩
shutil 可以打包,但是⽆无法解包,并且打包也是调⽤用tarfile 和 zipFile完成,解压需要按照格式调用对应的模块
打包
shutil.make_archive("test","tar","/Users/jerry/PycharmProjects/package/packa ge1")
import tarfile ,zipfile
zip 压缩
z = zipfile.ZipFile ("test.zip","w") z.write ("sys.py") z.write ("start.py") z.close ()
zip 解压
z = zipfile.ZipFile ("test.zip",'r') z.extractall ("/Users/jerry/PycharmProjects/package/aaa") z.close ()
tar 压缩
t = tarfile.open ("test.tar","w") t.add ("start.py") t.add ("sys.py") t.close ()
tar 解压
t = tarfile.open ("test.tar") t.extractall ("aaa/") t.close()
六 json&pickle模块
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。
Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
- json.dumps(): 对数据进行编码。
- json.loads(): 对数据进行解码。
""" pickle产生的数据 只能由python读取 (跨平台性差) 今后你开发程序不可能就是单机程序 你需要和其他设备 其他平台 交换数据 一三八四三八零零四三八 我们需要找到一种通用的数据格式 让各个平台都能识别 json模块 用于处理json格式数据的模块 json 全称 JavaScrip Object Notation js的对象表示法 所以json能支持的数据类型就是js支持数据类型 json格式标准 能存储的有 str int float dic list bool 案列 要求 数据的最开始和最末尾 必须是{} [] {"name":"yyh"} json是一种通用的数据交换格式 目前主流的语言都能够轻松解析 注意: 在使用json格式的时候 数据类型必须按照要求来写 并且 不支持python 元祖 True/Flase '' ''' 常用方法 序列化 dump 处理文件 dumps 处理字符串 反序列化 load 处理文件 loads 处理字符串 """ # 将python格式的数据序列化为json格式 python中的任何类型都能被转化为json格式 表现形式不同 import json users = {'name':"音乐会","age":20,"hobbies":("music","movies")} # # print(json.dumps(users)) # json.dump(users,open("users.json","wt",encoding="utf-8")) # # json的反序列化 jsonstr = json.load(open("users.json","r",encoding="utf-8")) print(jsonstr)
pickle产生的数据 只能由python读取 (跨平台性差) 今后你开发程序不可能就是单机程序 你需要和其他设备 其他平台 交换数据 一三八四三八零零四三八 我们需要找到一种通用的数据格式 让各个平台都能识别 json模块 用于处理json格式数据的模块 json 全称 JavaScrip Object Notation js的对象表示法 所以json能支持的数据类型就是js支持数据类型 json格式标准 能存储的有 str int float dic list bool 案列 要求 数据的最开始和最末尾 必须是{} [] {"name":"yyh"} json是一种通用的数据交换格式 目前主流的语言都能够轻松解析 注意: 在使用json格式的时候 数据类型必须按照要求来写 并且 不支持python 元祖 True/Flase '' ''' 常用方法 序列化 dump 处理文件 dumps 处理字符串 反序列化 load 处理文件 loads 处理字符串
""" pickle模块 作用于序列化 序列化就是将内存中的数据持久化到硬盘 回顾 使用文件读写也能完成把数据持久化存储 但是有局限性 当数据比较复杂时用起来就很麻烦 例如 需要把一个字典存储到硬盘中 先转成字符串 写入 读取为字符串 转为原始的格式 所以就有了pickle 1.能将所有python中的数据序列化 int float str dic list tuple set bool 2.反序列化 将之前序列化的数据 在恢复成python的数据格式 pickle产生的数据 只能由python读取 (跨平台性差) 今后你开发程序不可能就是单机程序 你需要和其他设备 其他平台 交换数据 一三八四三八零零四三八 我们需要找到一种通用的数据格式 让各个平台都能识别 """ users = {"name":"yyh","age":20,"hobbies":["打豆豆","飘"]} # f = open("a.txt","wt",encoding="utf-8") # f.write(str(users)) # f.close() import pickle # # print(pickle.dumps(users)) # 序列化 # f = open("p.txt","wb") # f.write(pickle.dumps(users)) # f.close() # # 反序列化 # f = open("p.txt","rb") # print(type(pickle.loads(f.read()))) # f.close() # 序列化 # pickle.dump(users,open("pp.txt","wb")) # print(pickle.load(open("pp.txt","rb")))
七 re模块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号