hadoop(一)hadoop简介
1. Hadoop 版本衍化历史
Hadoop 是一个由 Apache 基金会所开发的开源分布式系统基础架构。用户可以在不了解 分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。解 决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的 可靠存储和处理。适合处理非结构化数据,包括 HDFS,MapReduce 基本组件。
1. Hadoop 版本衍化历史 由于 Hadoop 版本混乱多变对初级用户造成一定困扰,所以对其版本衍化历史有个大概 了解,有助于在实践过程中选择合适的 Hadoop 版本。 Apache Hadoop 版本分为分为 1.0 和 2.0 两代版本,我们将第一代 Hadoop 称为 Hadoop 1.0,第二代 Hadoop 称为 Hadoop 2.0。下图是 Apache Hadoop的版本衍化史:
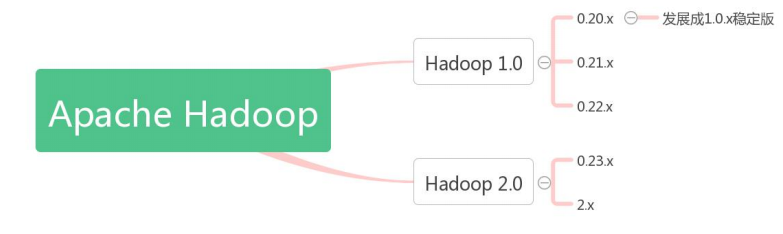
第一代 Hadoop 包含三个大版本,分别是 0.20.x,0.21.x 和 0.22.x,其中,0.20.x 最后演 化成 1.0.x,变成了稳定版。 第二代 Hadoop 包含两个版本,分别是 0.23.x 和 2.x,它们完全不同于 Hadoop 1.0,是 一套全新的架构,均包含 HDFS Federation 和 YARN 两个系统,相比于 0.23.x,2.x 增加了 NameNode HA 和 Wire-compatibility 两个重大特性。

Hadoop 遵从 Apache 开源协议,用户可以免费地任意使用和修改 Hadoop,也正因此, 市面上出现了很多 Hadoop 版本,其中比较出名的一是 Cloudera 公司的发行版,该版本称为 CDH(Cloudera Distribution Hadoop)。 截至目前为止,CDH 共有 4 个版本,其中,前两个已经不再更新,最近的两个,分别是 CDH3(在 Apache Hadoop 0.20.2 版本基础上演化而来的)和 CDH4 在 Apache Hadoop 2.0.0 版本基础上演化而来的),分别对应 Apache 的 Hadoop 1.0 和 Hadoop 2.0。
2. Hadoop 生态圈
架构师和开发人员通常会使用一种软件工具,用于其特定的用途软件开发。例如,他们 可能会说,Tomcat 是 Apache Web 服务器,MySQL 是一个数据库工具。 然而,当提到 Hadoop 的时候,事情变得有点复杂。Hadoop 包括大量的工具,用来协 同工作。因此,Hadoop 可用于完成许多事情,以至于,人们常常根据他们使用的方式来定 义它。 对于一些人来说,Hadoop 是一个数据管理系统。他们认为 Hadoop 是数据分析的核心, 汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。对于其他人, Hadoop 是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。 还有一些人认为 Hadoop 作为一个开源社区,主要为解决大数据的问题提供工具和软件。因 为 Hadoop 可以用来解决很多问题,所以很多人认为 Hadoop 是一个基本框架。 虽然 Hadoop 提供了这么多的功能,但是仍然应该把它归类为多个组件组成的 Hadoop 生态圈,这些组件包括数据存储、数据集成、数据处理和其它进行数据分析的专门工具。
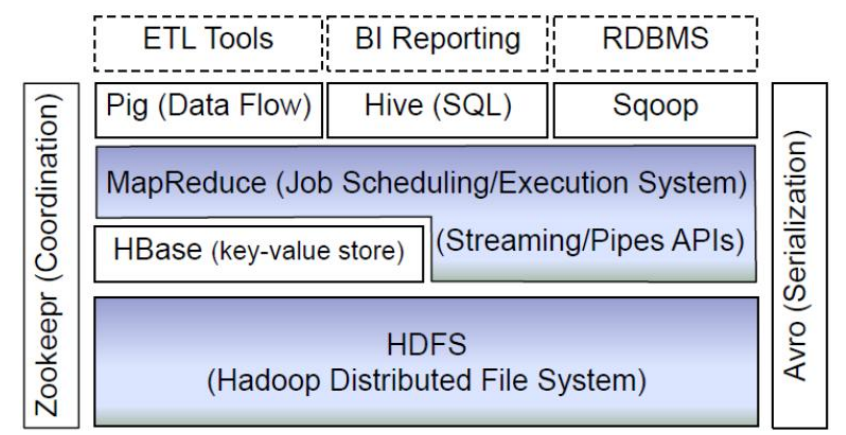
该图主要列举了生态圈内部主要的一些组件,从底部开始进行介绍:
1) HDFS:
Hadoop 生态圈的基本组成部分是 Hadoop 分布式文件系统(HDFS)。HDFS 是一 种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS 为 HBase 等工具提供了基础。
2) MapReduce:
Hadoop 的主要执行框架是 MapReduce,它是一个分布式、并行处理的编 程模型。MapReduce 把任务分为 map(映射)阶段和 reduce(化简)。开发人员使用存储在 HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce 工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
3) Hbase:
HBase 是一个建立在 HDFS 之上,面向列的 NoSQL 数据库,用于快速读/写大量 数据。HBase 使用 Zookeeper 进行管理,确保所有组件都正常运行。
4) ZooKeeper:
用于 Hadoop 的分布式协调服务。Hadoop 的许多组件依赖于 Zookeeper, 它运行在计算机集群上面,用于管理 Hadoop 操作。
5) Hive:
Hive 类似于 SQL 高级语言,用于运行存储在 Hadoop 上的查询语句,Hive 让不熟 悉 MapReduce 开发人员也能编写数据查询语句,然后这些语句被翻译为 Hadoop 上面 的 MapReduce 任务。像 Pig 一样,Hive 作为一个抽象层工具,吸引了很多熟悉 SQL 而 不是 Java 编程的数据分析师。
6) Pig:
它是 MapReduce 编程的复杂性的抽象。Pig 平台包括运行环境和用于分析 Hadoop 数据集的脚本语言(Pig Latin)。其编译器将 Pig Latin 翻译成 MapReduce 程序序列。
7) Sqoop:
是一个连接工具,用于在关系数据库、数据仓库和 Hadoop 之间转移数据。Sqoop 利用数据库技术描述架构,进行数据的导入/导出;利用 MapReduce 实现并行化运行和 容错技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号