prometheus监控k8s
1.Prometheus 是什么
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥 有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会 (CNCF),成为继Kubernetes之后的第二个托管项目。
官方链接:https://prometheus.io/ 托管git地址: https://github.com/prometheus
2.Prometheus组成及架构

- Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
- ClientLibrary:客户端库
- Push Gateway:短期存储指标数据。主要用于临时性的任务
- Exporters:采集已有的第三方服务监控指标并暴露metrics
- Alertmanager:告警
- Web UI:简单的Web控制台,展示功能较弱一般用来调试监控函数PromSQL,一般用grafana替代展示
- TSDB:时序数据库,用来存储监控数据。
3.数据模型
Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
每个时间序列都由度量标准名称和一组键值对(也成为标签)唯一标识。
时间序列格式:
<metric_name>{<lable_name>=<lable_value>, ...}
示例:api_http_requests_total{method="POST", handler="/messages"}
4.作业和示例
实例:可以抓取的目标称为实例(Instances)
作业:具有相同目标的实例集合称为作业(Job)
scrape_configs
5.K8S监控指标
Kubernetes本身监控
- Node资源利用率
- Node数量 • Pods数量(Node)
- 资源对象状态
Pod监控
- Pod数量(项目)
- Pod状态
- 容器资源利用率
- 应用程序

|
监控指标 |
具体实现 | 举例 |
| Pod性能 | cAdvisor | 容器CPU,内存利用率 |
| Node性能 | node-exporter | 节点CPU,内存利用率 |
| K8S资源对象 | kube-state-metrics |
Pod/Deployment/Service |
服务发现: https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
6.在K8S中部署Prometheus+Grafana
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
https://grafana.com/grafana/download
mkdir prometheus && cd prometheus
部署Prometheus
📎prometheus-service.yaml📎prometheus-statefulset.yaml📎prometheus-configmap.yaml📎prometheus-rbac.yaml
部署node-exporter
📎node-exporter-service.yaml📎node-exporter-ds.yml

浏览器 访问 nodeIp:30090


部署grafana
注意:为了数据的正常采集 务必保证集群间的时间同步

使用 node1-ip:30007 访问grafana
默认登录账号密码:admin/admin
登录后要求更新密码
展示监控数据 以下步骤,install grafana--》add data source---》new dashboard --》add users---》exporter plugin repository

step1:install grafana 已经完成。
step2:add data source

url 设置为 http://service_name:service_port,其他都默认然后保存


step 3:
推荐模板:
- 集群资源监控:3119
- 资源对象状态监控 :6417
- 工作节点监控 :8919
部署 kube-mertric-state
📎kube-state-metrics-rbac.yaml📎kube-state-metrics-service.yaml📎kube-state-metrics-deployment.yaml



集群资源监控:3119



资源对象状态监控 :6417




工作节点监控
使用自定义json :📎K8S工作节点监控-20191219.json

上传完json之后import


7.在K8S中部署Alertmanager

1. 部署Alertmanager
2. 配置Prometheus与Alertmanager通信
3. 配置告警
- prometheus指定rules目录
- configmap存储告警规则
- configmap挂载到容器rules目录
- 增加alertmanager告警配置
📎alertmanager-pvc.yaml📎alertmanager-service.yaml📎alertmanager-configmap.yaml📎alertmanager-deployment.yaml
其中alertmanager-configmap.yaml 中定义了 发件箱和 收件箱的信息,需要自定义设置一下

测试告警
修改 prometheus-rules.yaml 定义的磁盘使用率告警规则

将node节点根分区 使用默认大于80%告警 改为 大于40%
手动check 下 node1 和node 2 的 根分区使用率
node1 47%

node2 36%

重新应用配置
kubectl apply -f prometheus-rules.yaml
重建应用prometheus
kubectl delete pod prometheus-0 -n kube-system

打开 俺的 qq邮箱于是乎 收到了 磁盘告警的邮件。

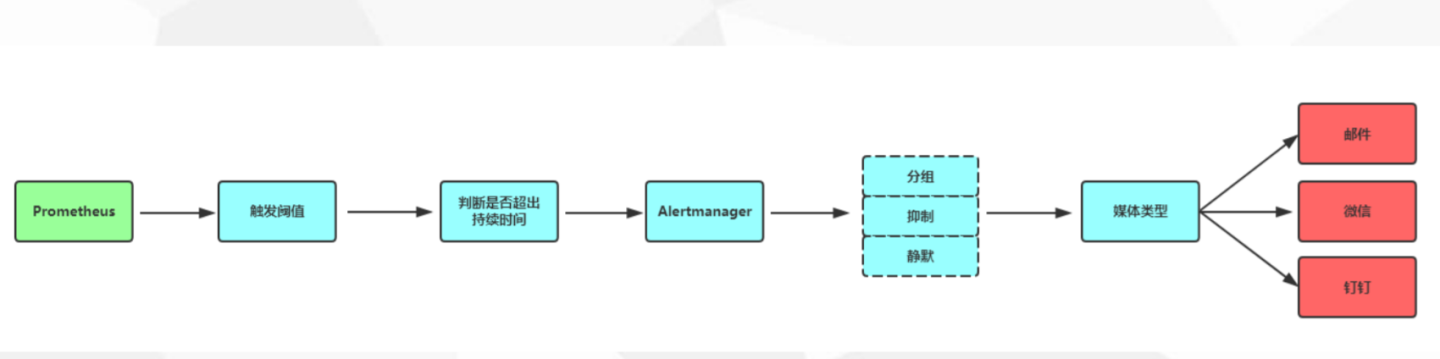
8.Prometheus告警状态
- Inactive:这里什么都没有发生。
- Pending:已触发阈值,但未满足告警持续时间
- Firing:已触发阈值且满足告警持续时间。警报发送给接受者。

9.Prometheus告警收敛
分组(group):将类似性质的警报分类为单个通知
抑制(Inhibition):当警报发出后,停止重复发送由此警报引发的其他警报
静默(Silences):是一种简单的特定时间静音提醒的机制
10.Prometheus一条告警怎么触发的?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号