MapReduce案例二:好友推荐
1.需求
推荐好友的好友
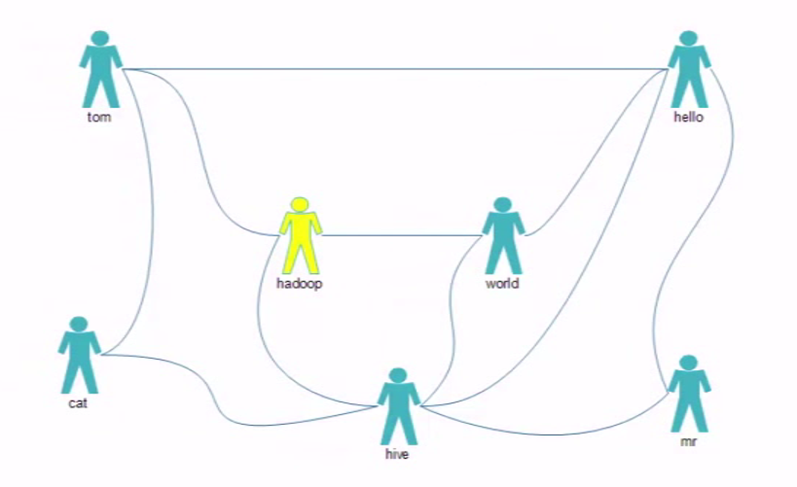
图1:


2.解决思路

3.代码
3.1MyFoF类代码
说明:
该类定义了所加载的配置,以及执行的map,reduce程序所需要加载运行的类
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyFoF { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //conf Configuration conf = new Configuration(true); Job job=Job.getInstance(conf); job.setJarByClass(MyFoF.class); //map job.setMapperClass(FMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //map阶段的分区排序都使用默认的不用额外设置 job.setReducerClass(FReducer.class); //input ... output Path input=new Path("/data/fof/input"); FileInputFormat.addInputPath(job, input); Path output=new Path("/data/fof/output"); if(output.getFileSystem(conf).exists(output)){ output.getFileSystem(conf).delete(output); } FileOutputFormat.setOutputPath(job, output); //submit job.waitForCompletion(true); } }
3.2FMapper类代码
说明:
该类的作用是编写map阶段的代码,对文本数据做一个预处理,按照规划比较每组的kv 做比较,这里面的k是偏移量longwritable类型,v是文本的字符串行 text类型。
代码逻辑:
1.双重for循环,外层循环比较直接关系,内层循环比较间接关系,最终map生成一个中间数据集,会有直接关系和间接关系。
2.将相同key的内容放在一起,交由reduce处理,如果是0代表为直接关系不作推荐,如果为1代表是间接关系,需要被推荐。
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.util.StringUtils; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text mkey=new Text(); IntWritable mval=new IntWritable(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //tom hello hadoop cat String[] strs = StringUtils.split(value.toString(),' '); //双重for循环,外层循环比较直接关系,内层循环比较间接关系,最终map生成一个中间数据集,会有直接关系和间接关系, //将相同key的内容放在一起,交由reduce处理,如果是0代表为直接关系不作推荐,如果为1代表是间接关系,需要被推荐。 for (int i = 0; i < strs.length; i++) { mkey.set(getFoF(strs[0],strs[i])); mval.set(0); context.write(mkey, mval); for (int j = i+1; j < strs.length; j++) { mkey.set(getFoF(strs[i],strs[j])); mval.set(1); context.write(mkey, mval); } } } //定义一个比较方法如果前一个数s1小于后面一个数s2,就拼接为s1+s2,否则s2+s1 public static String getFoF(String s1,String s2){ if(s1.compareTo(s2)<0){ return s1+":"+s2; } return s2+":"+s1; } }
3.3FReducer类代码
说明:
该类的作用是对map的输出做进一步处理,两两出现的value不为0的相同key的value累加起来,将累加的结果赋给key
package com.hadoop.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable rval=new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int flag=0; int sum=0; //增加for循环迭代values // hello:hadoop 0 // hello:hadoop 1 // hello:hadoop 0 for (IntWritable v : values) { //如果获取到的values是0则将flag置为1,如果不为0则将所有的values叠加 if(v.get()==0){ flag=1; } sum+=v.get(); } //如果获取到的values不为0,就将相同key且values不为0的values叠加赋值给reduce中key中对应的值 if(flag==0){ rval.set(sum); context.write(key, rval); } } }
4.服务端执行
4.1创建文件输入目录
[root@node01 test]# hdfs dfs -mkdir -p /data/fof/input
4.2上传文件到hdfs
[root@node01 test]# cat fof.txt tom hello hadoop cat world hadoop hello hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world hello tom world hive mr [root@node01 test]#hdfs dfs -put ./fof.txt /data/fof/input
4.3执行jar包
[root@node01 test]# hadoop jar ../jar_package/MyFOF.jar com.hadoop.mr.fof.MyFoF
4.4查看生成的输出文件
[root@node01 test]# hdfs dfs -ls /data/fof/output/ Found 2 items -rw-r--r-- 2 root supergroup 0 2019-01-01 06:11 /data/fof/output/_SUCCESS -rw-r--r-- 2 root supergroup 116 2019-01-01 06:11 /data/fof/output/part-r-00000
[root@node01 test]# hdfs dfs -cat /data/fof/output/part-r-00000 cat:hadoop 2 cat:hello 2 cat:mr 1 cat:world 1 hadoop:hello 3 hadoop:mr 1 hive:tom 3 mr:tom 1 mr:world 2 tom:world 2
说明:通过图1可以发现
cat 和hadoop、hello都有2个共同的朋友tom、hive
cat和mr、world有1个共同的朋友hive
hadoop和hello有3个共同的朋友 tom、world、hive
hadoop和hive有1个共同的朋友world
hive和tom有3个共同的朋友cat、hadoop、hello
mr和tom有1个共同的朋友hello
mr和world有2个共同的朋友hello、hive
tom和world有2个共同的朋友hello、hadoop
5.报错解决
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot delete /data/fof/output. Name)
这个异常表示hadoop处于安全状态,而你又对它进行了上传,修改,删除文件的操作。
刚启动完hadoop的时候,hadoop会进入安全模式,此时不能对hdfs进行上传,修改,删除文件的操作。
命令是用来查看当前hadoop安全模式的开关状态
hdfs dfsadmin -safemode get
命令是打开安全模式
hdfs dfsadmin -safemode enter
命令是离开安全模式
hdfs dfsadmin -safemode leave
离开安全模式再次执行即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号