
使用wireshark查看Kafka客户端的网络连接 - Producer
Kafka客户端包括producer及consumer API,通过在wireshark中查看所捕获的请求,能更好的理解从producer及consumer到broker的网络连接过程。对于producer端,为了发送数据,需要建立client到broker节点的TCP长连接,此长连接可用于更新metadata,发送消息到broker,在超过配置的空闲时间后,为了节省资源,长连接将被关闭。
1:producer kerberos 认证连接
在创建producer实例时,调用KafkaProducer类中的函数createChannelBuilder,因为配置了kerberos认证,将启动client到KDC的认证过程
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) { ...... ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config.values()); ...... }
上面第一个参数里配置的authentication为SASL_PLAINTEXT,所以此方法将创建一个SaslChannelBuilder 通道构造器,
channelBuilder = new SaslChannelBuilder(mode, loginType, securityProtocol, clientSaslMechanism, saslHandshakeRequestEnable);
对应输入参数为 mode = CLIENT loginType = CLIENT securityProtocol = SASL_PLAINTEXT clientSaslMechanism = GSSAPI saslHandshakeRequestEnable = true 创建好通道构造器后,就是设置配置信息,调用channelBuilder.configure(configs);在此方法中将创建loginManager实例,而在loginManager构造的时候,将取得KerberosLogin实例,并登陆,
login = hasKerberos ? new KerberosLogin() : new DefaultLogin(); login.configure(configs, loginContext); login.login();
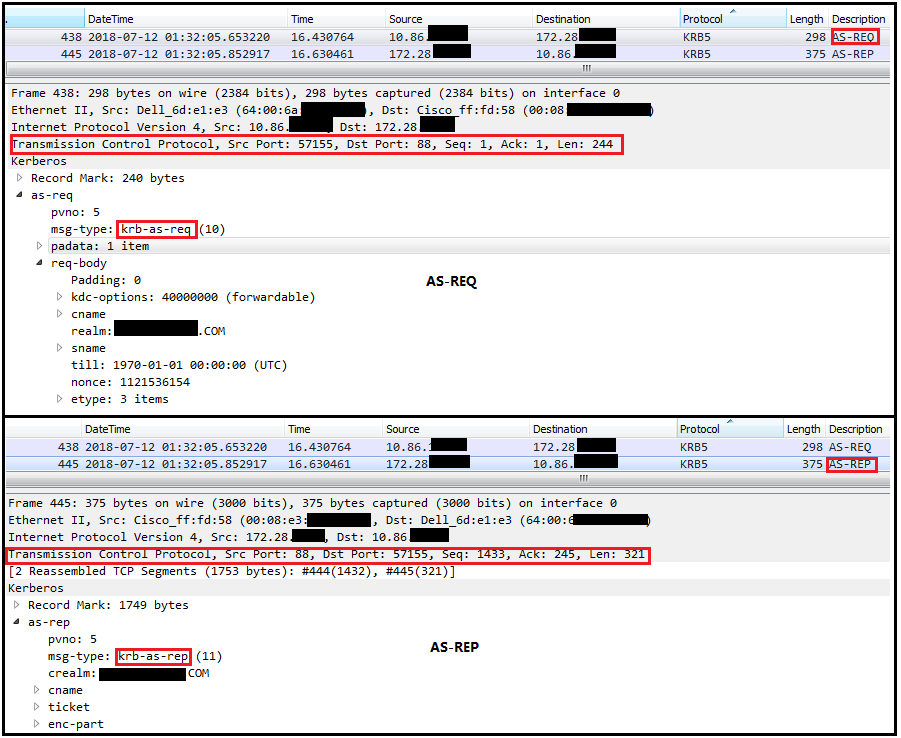
从Wireshark的捕获可以看到请求与响应的过程,默认情况下,kerberos使用UDP协议,前面4条便是使用的UDP协议,但因为受限于请求包的长度限制,所以返回失败,错误码是KRB5KDC_ERR_PREAUTH_REQUIRED及KRB5KRB_ERR_RESPONSE_TOO_BIG,于是在第5条重新使用TCP发送AS-REQ请求到目标端口88,并收到AS-REP响应

下面是到KDC的Authentication Service的连接过程:
请求AS成功后,紧接着就是到KDC的Ticket Granting Service以获取票据的连接过程
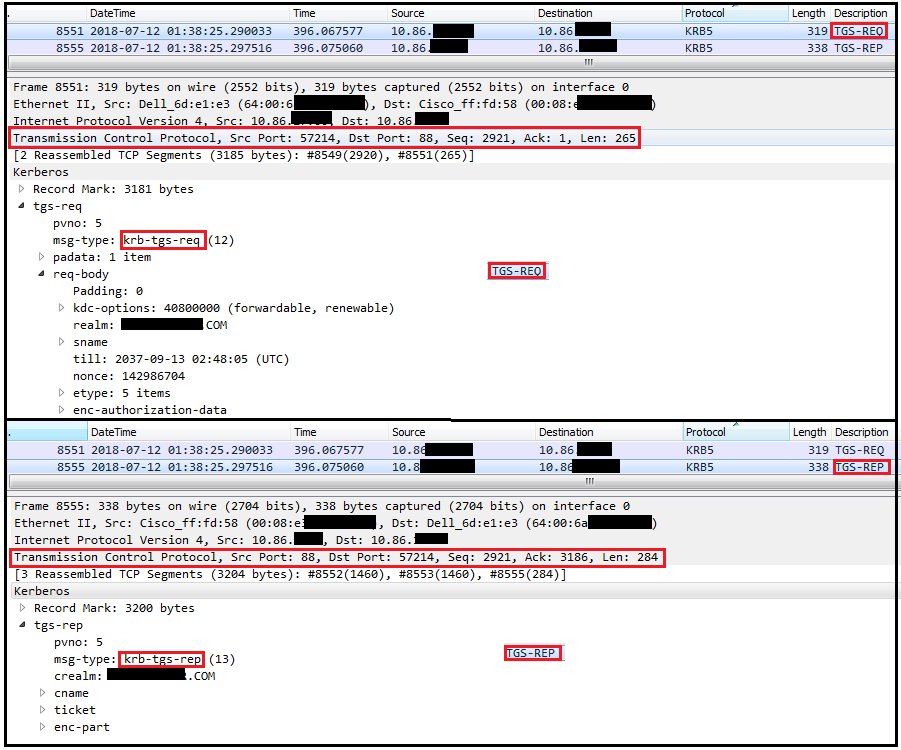
具体可以参考文章:KRB5KDC_ERR_PREAUTH_REQUIRED

2:producer sender线程
在创建producer实例过程中,将先初始化一个metadata实例,这个metadata保存的是集群的配置信息,如broker的列表topic,partition与broker的映射关系
private KafkaProducer(ProducerConfig config, Serializer<K> keySerializer, Serializer<V> valueSerializer) { try { ...... //初始化metadata对象,设置属性metadata.max.age.ms,这个值从producer 的配置文件获取,表示更新meta的时间周期 this.metadata = new Metadata(retryBackoffMs, config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG)); ...... //设置初始的broker节点信息,是从配置的bootstrap.servers属性获取 this.metadata.update(Cluster.bootstrap(addresses), time.milliseconds()); ...... String ioThreadName = "kafka-producer-network-thread" + (clientId.length() > 0 ? " | " + clientId : ""); this.ioThread = new KafkaThread(ioThreadName, this.sender, true); this.ioThread.start(); } } catch (Throwable t) { // call close methods if internal objects are already constructed // this is to prevent resource leak. see KAFKA-2121 close(0, TimeUnit.MILLISECONDS, true); // now propagate the exception throw new KafkaException("Failed to construct kafka producer", t); } }
同时将启动一个sender IO线程,在这个线程中将真正建立从client到broker的连接,从broker获取metadata 信息及当发送的数据在缓存中达到阈值时,从accumulator中获取消息并发送给broker。NetworkClient是kafka客户端的网络接口层,实现了接口KafkaClient,封装了Java NIO对网络的调用,函数initiateConnect进行初始化连接,所连接的broker 节点由函数leastLoadedNode确定
public class NetworkClient implements KafkaClient { /** * Initiate a connection to the given node */ private void initiateConnect(Node node, long now) { String nodeConnectionId = node.idString(); try { log.debug("Initiating connection to node {} at {}:{}.", node.id(), node.host(), node.port()); this.connectionStates.connecting(nodeConnectionId, now); selector.connect(nodeConnectionId, new InetSocketAddress(node.host(), node.port()), this.socketSendBuffer, this.socketReceiveBuffer); } catch (IOException e) { /* attempt failed, we'll try again after the backoff */ connectionStates.disconnected(nodeConnectionId, now); /* maybe the problem is our metadata, update it */ metadataUpdater.requestUpdate(); log.debug("Error connecting to node {} at {}:{}:", node.id(), node.host(), node.port(), e); } } }
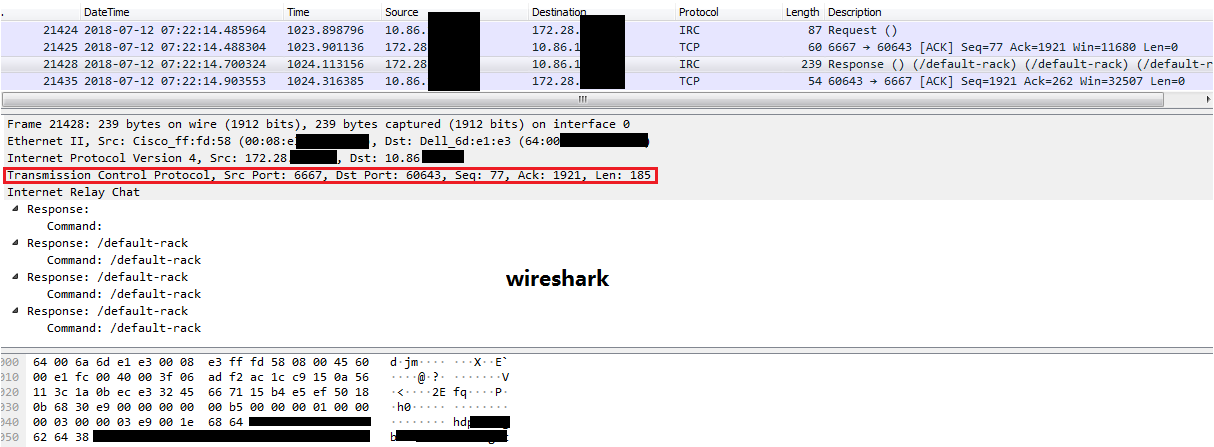
在wireshark中可以看到建立连接的TCP 3次握手过程

3:metadata的获取更新
建立好连接后,sender线程中调用KafkaClient 的poll来对socket进行实际的读写操作,在poll函数中首先调用metadataUpdater.maybeUpdate(now)来判断是否需要更新metadata,
{Class NetworkClient} //do actual reads and writes to sockets public List<ClientResponse> poll(long timeout, long now) { long metadataTimeout = metadataUpdater.maybeUpdate(now); //判断是否需要更新metadata try { this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs)); } catch (IOException e) { log.error("Unexpected error during I/O", e); } ...... }
如果canSendRequest返回true,则调用dosend发送请求到某个broker node获取metadata,其实dosend只是把获取metadata的request放到队列中,由selector.poll从队列中获取数据并实际发送请求到broker
{Class DefaultMetadataUpdater} public long maybeUpdate(long now) { ...... if (metadataTimeout == 0) { // Beware that the behavior of this method and the computation of timeouts for poll() are // highly dependent on the behavior of leastLoadedNode. Node node = leastLoadedNode(now); maybeUpdate(now, node); } return metadataTimeout; } private void maybeUpdate(long now, Node node) { if (node == null) { log.debug("Give up sending metadata request since no node is available"); // mark the timestamp for no node available to connect this.lastNoNodeAvailableMs = now; return; } String nodeConnectionId = node.idString(); if (canSendRequest(nodeConnectionId)) { this.metadataFetchInProgress = true; MetadataRequest metadataRequest; if (metadata.needMetadataForAllTopics()) metadataRequest = MetadataRequest.allTopics(); else metadataRequest = new MetadataRequest(new ArrayList<>(metadata.topics())); ClientRequest clientRequest = request(now, nodeConnectionId, metadataRequest); log.debug("Sending metadata request {} to node {}", metadataRequest, node.id()); doSend(clientRequest, now); //发送请求到某个broker node,使用下面initiateConnect建立的与此node的长连接 } else if (connectionStates.canConnect(nodeConnectionId, now)) { // we don't have a connection to this node right now, make one log.debug("Initialize connection to node {} for sending metadata request", node.id()); initiateConnect(node, now);//建立到node的长连接 } else { // connected, but can't send more OR connecting // In either case, we just need to wait for a network event to let us know the selected // connection might be usable again. this.lastNoNodeAvailableMs = now; } }
在wireshark中,可以看到从broker获取metadata的Request / Response 过程,从broker node返回的是所有的broker 列表。
4:producer 发送数据
当用户调用下面方法发送数据时
producer.send(producerRecord, new ProducerCallBack(requestId))
其实是将数据保存在accumulator中的,在doSend方法中会先确定是否有metadata信息,如果有metadata,则对数据做key及value的序列化,然后将数据append到accumulator中便返回
{Class KafkaProducer}
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) { TopicPartition tp = null; try { // first make sure the metadata for the topic is available long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs); long remainingWaitMs = Math.max(0, this.maxBlockTimeMs - waitedOnMetadataMs); byte[] serializedKey; ...... serializedKey = keySerializer.serialize(record.topic(), record.key()); //key 序列化 byte[] serializedValue; ...... serializedValue = valueSerializer.serialize(record.topic(), record.value()); //value 序列化 int partition = partition(record, serializedKey, serializedValue, metadata.fetch()); int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
......
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs); return result.future; ...... }
在sender线程中,将从accumulator中获取数据,并发送到相应的broker node
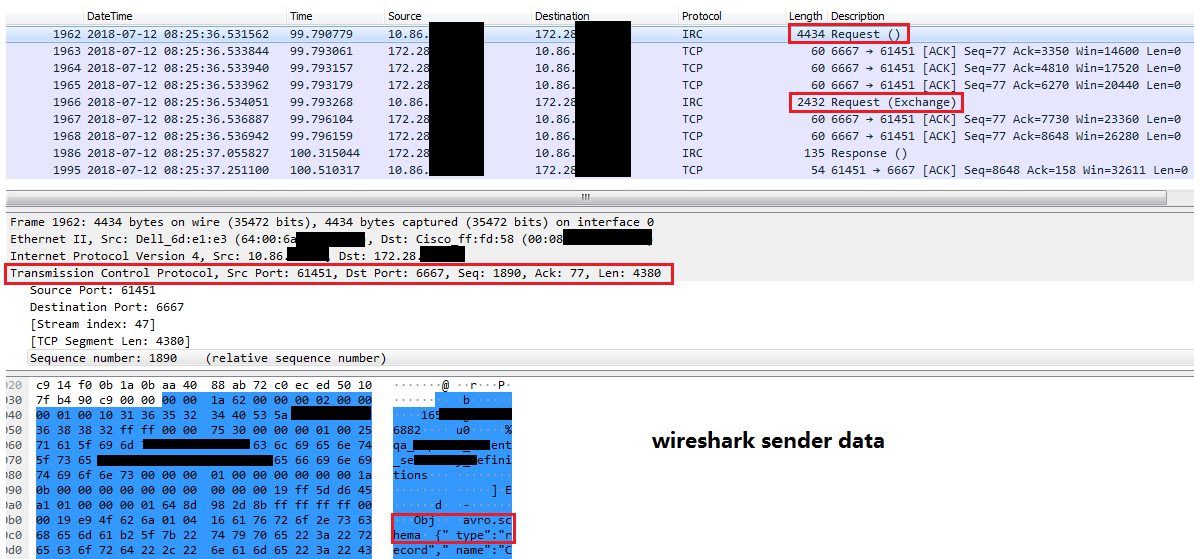
从上面的网络连接可以看到有2次发送请求的过程,Request() 及 Request(Exchange),在TCP的封包中,也可以看到有avro.schema的模式信息
总结:
1:如果配置kerberos认证,则需要到KDC (AS/TGS)进行TCP连接的请求
2:初始情况,根据bootstrap.servers配置的broker列表,建立到每个节点的TCP长连接
3:一个kafka producer实例对应一个sender线程,客户端根据leastLoadedNode返回的节点,向此节点发送获取metadata的更新请求,可以得到全部的brokers,也就是说在bootstrap.server中的节点只是全部节点的一个子集
4:创建producer后,如果立刻发送数据,数据保存在accumulator中,sender线程会读取accumulator,并获取metadata,使用已有连接(如果没有连接则建立TCP连接)发送数据
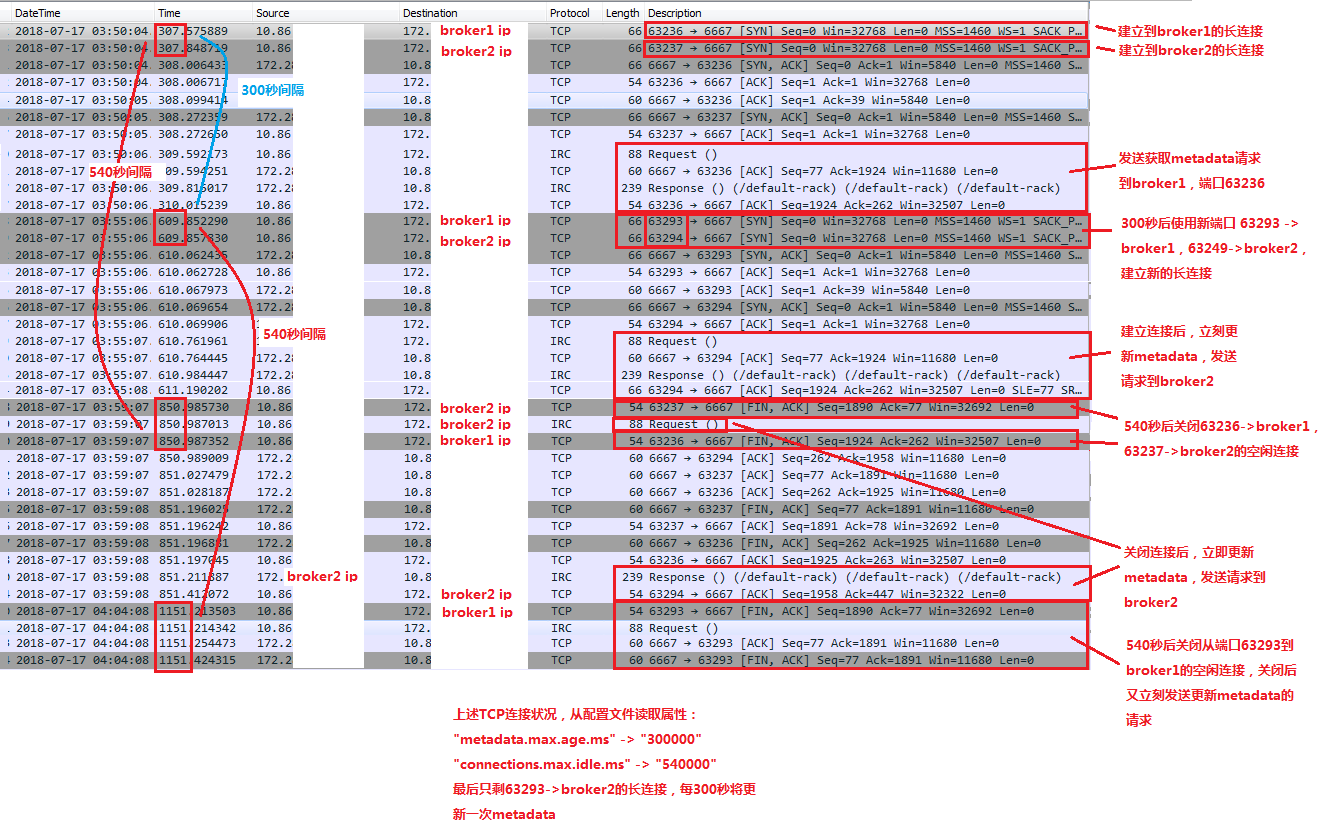
5:sender线程调用NetworkClient.poll不断的轮询,按metadata.max.age.ms配置的时间周期性的更新metadata,在本文中配置的是"metadata.max.age.ms" -> "300000",故会每300秒更新一次metadata。
6:在创建到某个node的长连接后,如果时间到了上面metadata更新周期,又将创建一个新的长连接,更新metadata后,如果原来那个连接在"connections.max.idle.ms" -> "540000"所配置的默认时间没有使用过,会断开空闲的长连接,一旦断开连接,立刻又请求更新metadata
下图为抓取的从producer客户端到broker的TCP连接的请求过程,仅供参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号