Kafka 消息的序列化与反序列化(一)
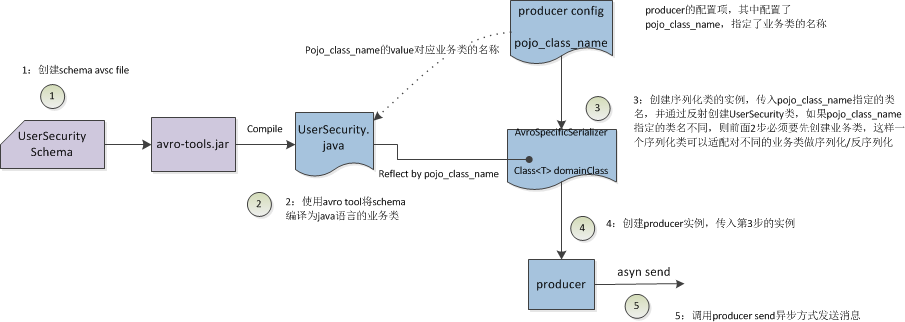
在使用Kafka发送接收消息时,producer端需要序列化,consumer端需要反序列化,在大多数场景中,需要传输的是与业务规则相关的复杂类型,这就需要自定义数据结构。Avro是一种序列化框架,使用JSON来定义schema,shcema由原始类型(null,boolean,int,long,float,double,bytes,string)和复杂类型(record,enum,array,map,union,fixed)组成,schema文件以.avsc结尾,表示avro schema,有2种序列化方式
- 二进制方式:也就是Specific方式,定义好schema asvc文件后,使用编译器(avro-tools.jar)编译生成相关语言(java)的业务类,类中会嵌入JSON schema
- JSON方式:也就是Generic方式,在代码中动态加载schema asvc文件,将FieldName - FieldValue,以Map<K,V>的方式存储
序列化后的数据,是schema和data同时存在的,如下图

1:自定义序列化类:
先定义序列化类,使用Specific序列化方式,下面方法中使用了SpecificDatumWriter类
public class AvroWithSchemaSpecificSer<T, E> implements Serializer<T> { public byte[] serialize(String topic, T data) { SpecificData specificData = new SpecificData(); //用于日期和时间格式的转换 specificData.addLogicalTypeConversion(new DateConversion()); specificData.addLogicalTypeConversion(new TimeConversion()); specificData.addLogicalTypeConversion(new TimestampConversion()); DatumWriter<T> datumWriter = new SpecificDatumWriter(this.schema, specificData); byte[] bytes = new byte[0]; if (data != null) { ByteArrayOutputStream baos = new ByteArrayOutputStream(); DataFileWriter<T> dataFileWriter = new DataFileWriter(datumWriter); dataFileWriter.setCodec(CodecFactory.fromString(this.codecName)).create(this.schema, baos); dataFileWriter.append(data); dataFileWriter.flush(); baos.flush(); bytes = baos.toByteArray(); dataFileWriter.close(); baos.close(); } return bytes; } }
2:创建producer对象:
KafkaProducer<K,V>是用于创建producer实例的线程安全的客户端类,多个线程可以共用一个producer实例,而且通常情况下共用一个实例比每个线程创建一个producer实例性能要好。在创建produce实例时,Properities必须配置的3个参数为:bootstrap.servers,key.serializer,value.serializer,关于KafkaProducer类,可参看官方文档KafkaProducer
创建producer对象,并加入到虚拟机关闭钩子中,用于在虚拟机关闭是清理producer
Serializer<K> keyDeserClass = (Serializer) Class.forName(props.getProperty("key.serializer")).newInstance();
Class<?> cl = Class.forName(props.getProperty("value.serializer"));
Constructor<?> cons = cl.getConstructor(Map.class);
Serializer<V> valueSerClass = (Serializer)cons.newInstance(consumerConfig.get("pojo_class_name"), null);
Producer<K,V> producer = new KafkaProducer<>(props, keySerClass, valueSerClass);
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
producer.close();
}
});
函数原型如下:
public class KafkaProducer<K, V> implements Producer<K, V> { public KafkaProducer(Properties properties, Serializer<K> keySerializer, Serializer<V> valueSerializer) }
第一个参数是一个Properties类型,配置如下
{
security.protocol=SASL_PLAINTEXT,
schema.registry.url=http://yourregistryurl.youcompany.com:8080,
bootstrap.servers=yourbootstrap1.youcompany.com:7788, yourbootstrap2.youcompany.com:7788,
key.serializer=org.apache.kafka.common.serialization.LongSerializer,
value.serializer=com.youcompany.serialization.AvroSchemaSpecificSer,
pojo_class_name=UserSecurity
client.id=18324@xxx,
acks=all
}
第二个参数是key的序列化实例,从第一个参数的key.serializer获取类名字 "org.apache.kafka.common.serialization.LongSerializer",并反射创建类实例
第三个参数是value的序列化实例,从第一个参数的value.serializer获取类名字 "com.youcompany.serialization.AvroSchemaSpecificSer",应用反射创建类实例,这是一个自定义的序列化类,用于序列化pojo_class_name所指向的avro类(由avro schema定义并经过编译后的业务类)UserSecurityRequest
Class<?> cl = Class.forName(props.getProperty("value.serializer"));
Constructor<?> cons = cl.getConstructor(Map.class);
Serializer<V> valueSerClass = (Serializer)cons.newInstance(produceConfig.get("pojo_class_name"), null);
注: 在生成producer实例过程中,将调用方法:ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config.values()); 因为上面第一个参数里配置的authentication为SASL_PLAINTEXT,所以此方法将创建一个SaslChannelBuilder 通道构造器,
这个过程将使用kerberos方式登陆认证,可参见另外一篇博客
3:producer发送消息:
ProducerRecord<K, V> producerRecord = new ProducerRecord<>("mytopic",data); producer.send(producerRecord, new ProducerCallBack(requestId));
先使用avro业务对象(UserSecurityRequest)data创建producerRecord,然后调用producer发送消息,有同步和异步2种发送方式,此处使用的是异步方式,消息将被存储在待发送的IO缓存后即刻返回,这样可以并行无阻塞的发送更多消息,提高producer性能,并在回调函数中获取消息的offset。在send的过程中,如果有拦截器,则先调用拦截器,再继续发送消息,send的源代码如下:
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) { ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record); return this.doSend(interceptedRecord, callback); }
在do.Send函数中,可以看到调用了value的序列化
byte[] serializedValue; try { serializedValue = this.valueSerializer.serialize(record.topic(), record.value()); } catch (ClassCastException var16) { throw new SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + this.producerConfig.getClass("value.serializer").getName() + " specified in value.serializer"); }
而对于value的序列化,正是使用了自定义的对avro schema序列化的类
4:架构图:
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号