
AWS Lambda 查询 Redshift Serverless
在应用程序中,经常在Lambda 中调用redshift data api 去查询 redshift serverless 的数据,以下描述具体实现过程:
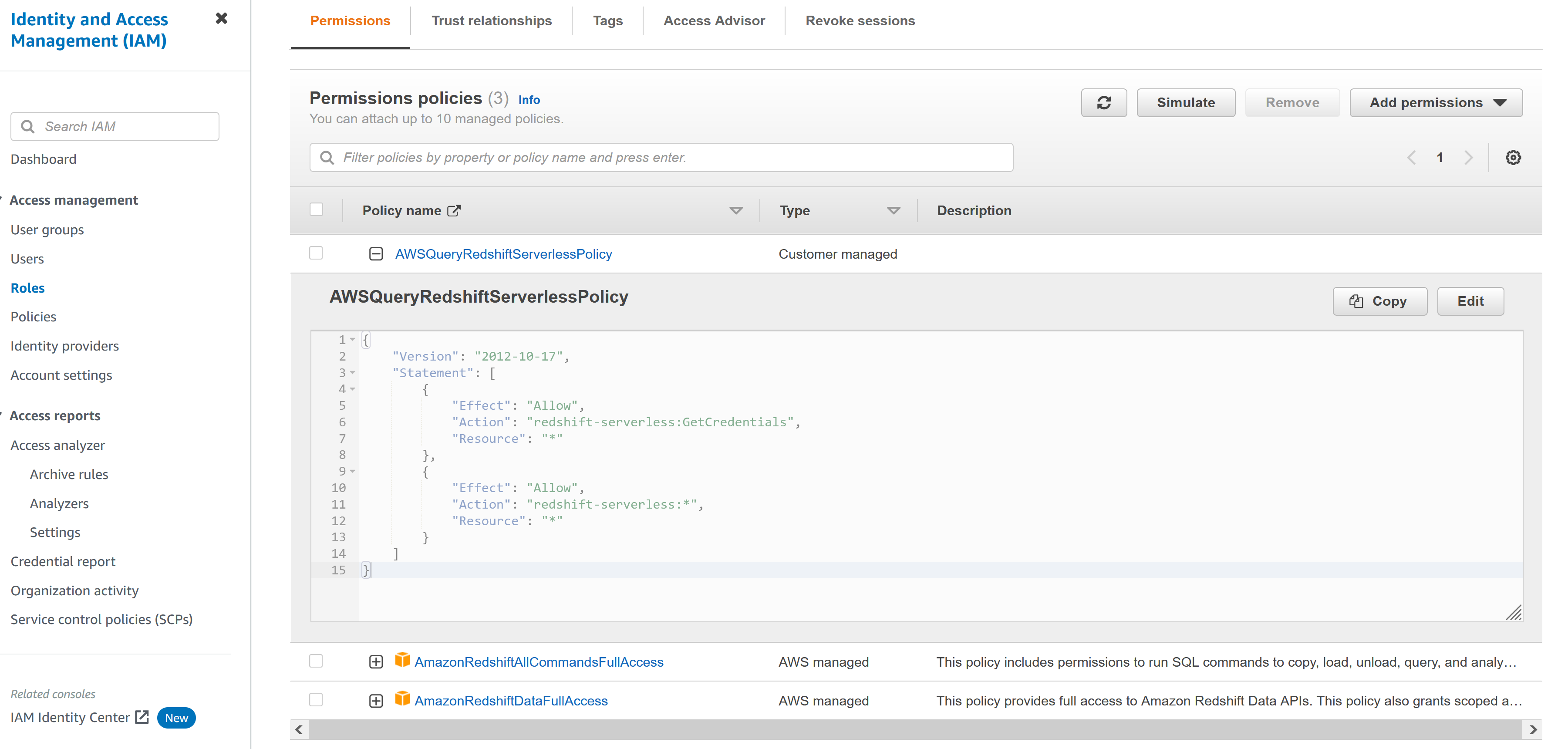
1:给Lambda 创建一个执行Lambda的IAM Role,并具有访问redshift serverless 权限,同时需要指定获取临时凭证的策略(参考:授予对 Amazon Redshift 数据 API 的访问权限)

因为在Lambda 执行的Role 将被转化为redshift serverless 对应的用户,加速role 名是:test-redshift-role,则对应的用户是:IAMR:test-redshift-role,下面是创建的测试IAM Role
2:创建Lambda脚本,在脚本中使用redshift data api 访问redshift serverless:
import time import traceback import boto3 import logging from collections import OrderedDict print('boto3 version: ' + boto3.__version__) logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): # input parameters passed from the caller event # cluster identifier for the Amazon Redshift cluster redshift_workgroup_name = event['redshift_workgroup_name'] # database name for the Amazon Redshift cluster redshift_database_name = event['redshift_database'] # IAM Role of Amazon Redshift cluster having access to S3 redshift_iam_role = event['redshift_iam_role'] # run_type can be either asynchronous or synchronous; try tweaking based on your requirement run_type = event['run_type'] sql_statements = OrderedDict() res = OrderedDict() if run_type != "synchronous" and run_type != "asynchronous": raise Exception( "Invalid Event run_type. \n run_type has to be synchronous or asynchronous.") isSynchronous = True if run_type == "synchronous" else False # initiate redshift-data redshift_data_api_client in boto3 redshift_data_api_client = boto3.client('redshift-data') sql_statements['SELECT'] = "select top 10 * from \"taxlot\".\"public\".\"lot\" where accountnumber = '7LD701824' and cusip = '256219106';" logger.info("Running sql queries in {} mode!\n".format(run_type)) try: for command, query in sql_statements.items(): logging.info("Example of {} command :".format(command)) res[command + " STATUS: "] = execute_sql_data_api(redshift_data_api_client, redshift_database_name, command, query,redshift_workgroup_name, isSynchronous) except Exception as e: raise Exception(str(e) + "\n" + traceback.format_exc()) return res def execute_sql_data_api(redshift_data_api_client, redshift_database_name, command, query, redshift_workgroup_name, isSynchronous): MAX_WAIT_CYCLES = 20 attempts = 0 # Calling Redshift Data API with executeStatement() res = redshift_data_api_client.execute_statement(Database=redshift_database_name, Sql=query, WorkgroupName=redshift_workgroup_name) logger.info("Query result{}!\n".format(res)) query_id = res["Id"] desc = redshift_data_api_client.describe_statement(Id=query_id) query_status = desc["Status"] logger.info("Query status: {} .... for query-->{}".format(query_status, query)) logger.info("Query status: {} ".format(desc)) done = False # Wait until query is finished or max cycles limit has been reached. while not done and isSynchronous and attempts < MAX_WAIT_CYCLES: attempts += 1 logger.info("Query cycle: {} ".format(attempts)) time.sleep(1) desc = redshift_data_api_client.describe_statement(Id=query_id) query_status = desc["Status"] logger.info("Query status: {} ".format(query_status)) if query_status == "FAILED": raise Exception('SQL query failed:' + query_id + ": " + desc["Error"]) elif query_status == "FINISHED": logger.info("query status is: {} for query id: {} and command: {}".format(query_status, query_id, command)) done = True # print result if there is a result (typically from Select statement) if desc['HasResultSet']: response = redshift_data_api_client.get_statement_result(Id=query_id) logger.info("Printing response of {} query --> {}".format(command, response['Records'])) else: logger.info( "Current working... query status is: {} ".format(query_status)) # Timeout Precaution if done == False and attempts >= MAX_WAIT_CYCLES and isSynchronous: logger.info("Limit for MAX_WAIT_CYCLES has been reached before the query was able to finish. We have exited out of the while-loop. You may increase the limit accordingly. \n") raise Exception("query status is: {} for query id: {} and command: {}".format( query_status, query_id, command)) return query_status
测试时传入参数:

至此,Lambda部分设置完,但在执行时将报权限拒绝错误,因为此时,Lambda 的执行Role:test-redshift-role 在数据库中对应的用户 IAMR:test-redshift-role 是没有访问权限的,所以需要在Redshift Serverless console中继续下面的第3步
"errorMessage": "SQL query failed:77d160f1-40ef-476b-bdc5-b5d64432e96d: ERROR: permission denied for relation lot\nTraceback (most recent call last):\n File \"/var/task/lambda_function.py\", line 44
3:给IAM Role设置访问权限,此处是将用户加入到一个group中,并授予这个group访问全部表的select 权限,如下图所示
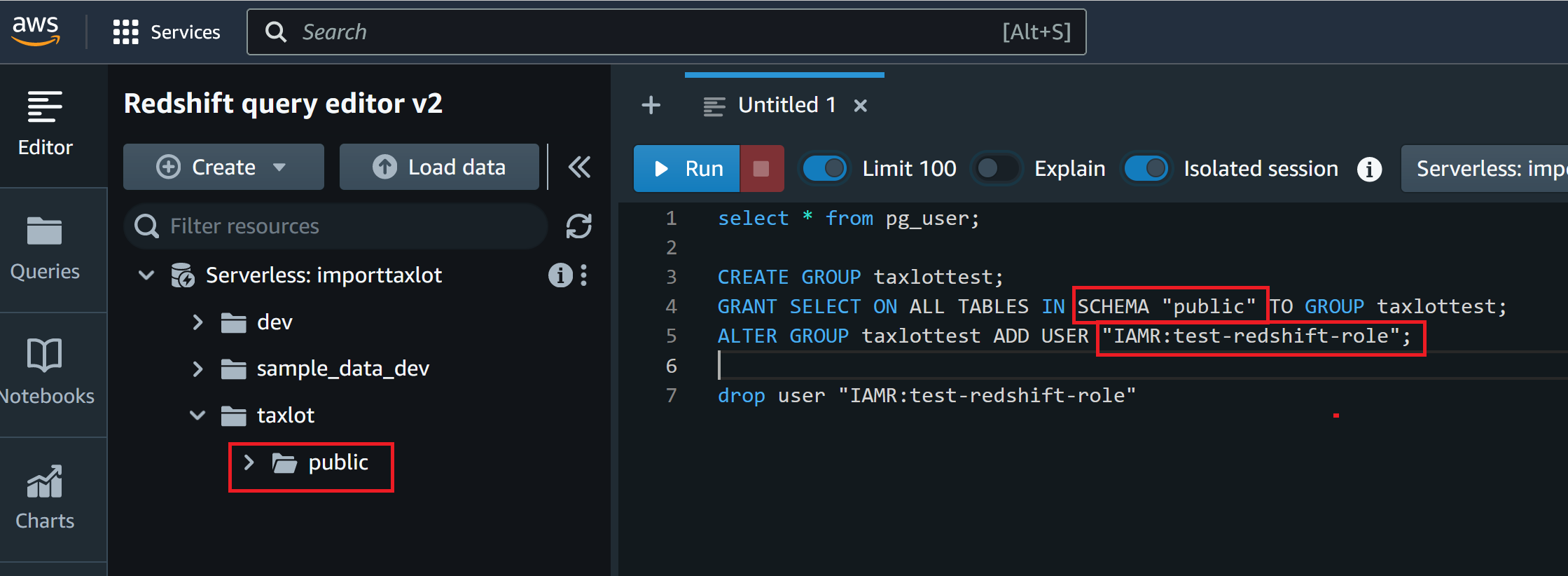
或者直接赋予IAM Role 相应的权限,
grant all on table "taxlot"."public"."lot" to "IAMR:test-redshift-role";
如果只想给lambda赋予查询权限,则可以单独赋予select权限
grant select on table "taxlot"."public"."lot" to "IAMR:test-redshift-role";
设置完后,再回到lambda,执行redshift serverless 查询成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号