AWS Glue 在数据湖仓中的应用
在AWS环境,一般会使用S3作为数据湖,在S3上存储组织中的结构化,半结构化及非结构化的数据,这里使用了一个网上比较典型的AWS 数据湖仓的架构
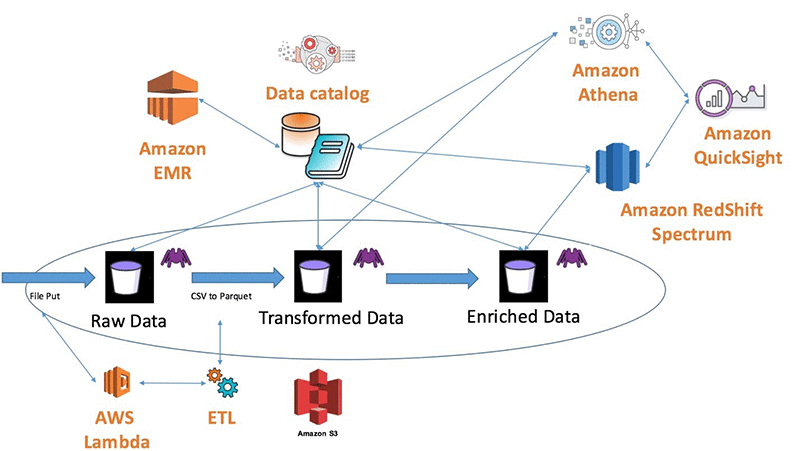
- Glue Catalog数据目录的建立
Glue可以使用Crawler 爬网程序读取一些特定格式的文件列头元数据,比如Avro,CSV,Apache Parquet,JSON,XML等,当然也可以手动在Catalog里添加元数据,元数据的建立过程是可选的,在Glue ETL job里,也可以通过脚本在代码里指定需要输出的文件列头及数据类型,但如果能将元数据保存在catalog里,是比较容易维护的,是一种优雅的做法
- Athena 数据查询
在元数据建立后,可以在Athena中使用标准的SQL语言直接查询S3上的文件了,这非常有助于直接对于源文件进行分析,而无需将文件转换到关系数据库里
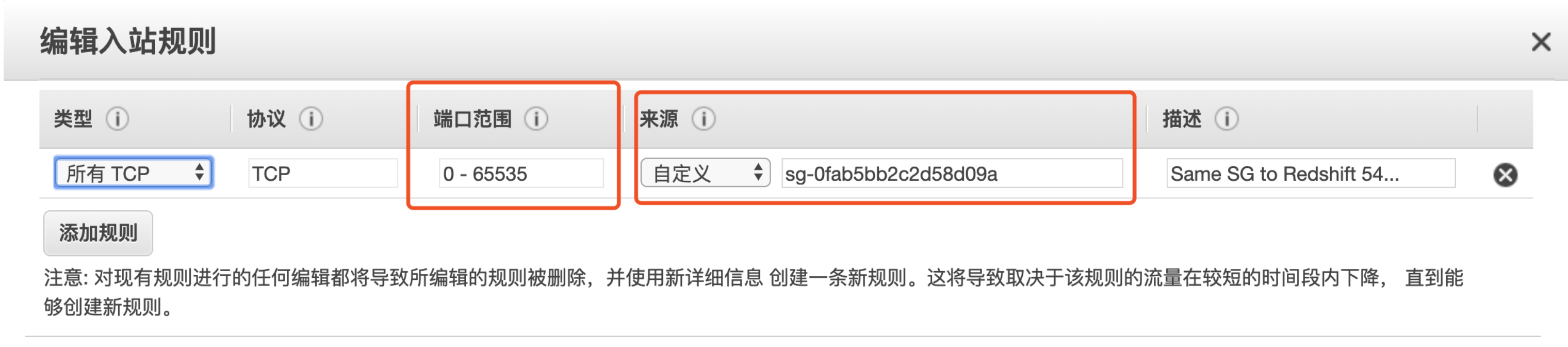
- Security Group的创建:Glue连接Redshift,需要一个VPC安全组,Glue在连接VPC内的服务时,是通过创建一个新的ENI,并使用私网地址连接,所以需要有能够访问VPC服务的Security Group,并编辑入站规则(端口范围选择所有TCP端口,来源把安全组ID粘贴上,表示只要有相同Security Group的AWS资源就可以访问5439端)
- Redshift Serverless Workgroup的创建
Redshift有2种类型,一种是prevision node的cluster类型,一种是去年新推的serverless类型,对于要求不高,不需要预留节点容量的应用,serverless是比较好的选择,不用再去维护基础架构了。
在创建Redshift serverless workgroup时,需要输入用户名及密码(比如admin/Test1234),并同时指定以下选项
- vpc
- security group :选择上面创建的安全组
- subnet (选择私有子网)
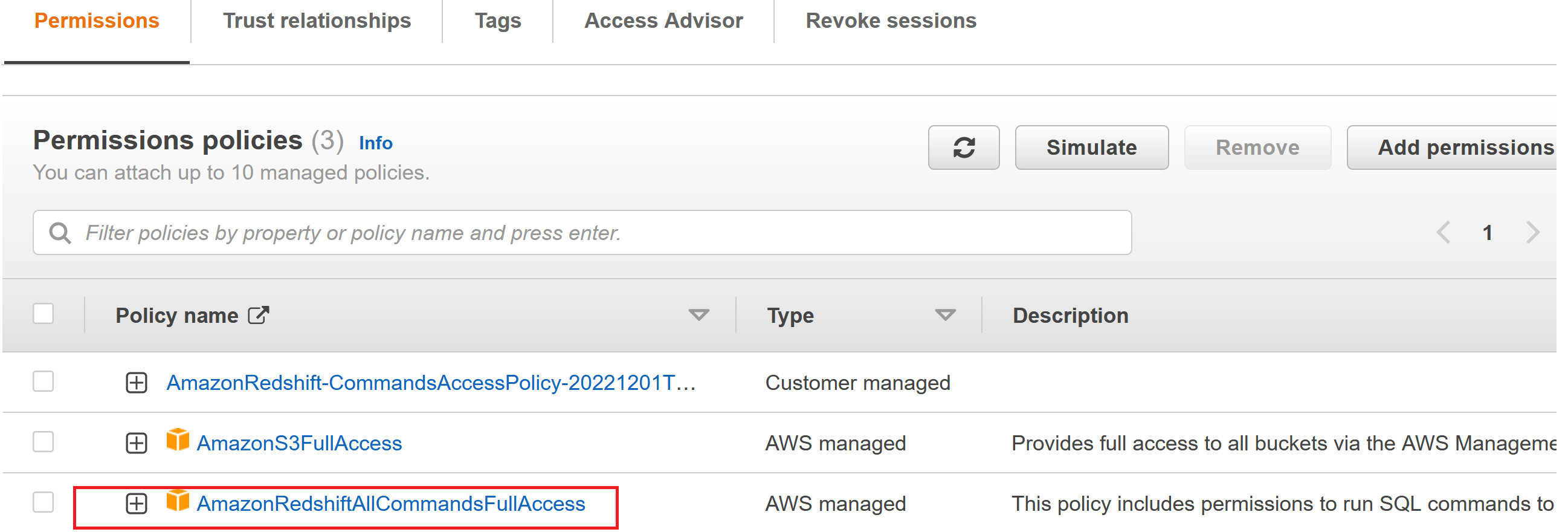
- 默认情况下会创建一个default IAM role,具有访问策略 AmazonRedshiftAllCommandsFullAccess
- 及默认创建一个vpc interface endpoint (VPC接口终端节点)(注:此处不确定是否能选择已经创建好的S3网关终端节点,好像没有选择的地方)
- Glue ETL & Connection 及 IAM role 设置
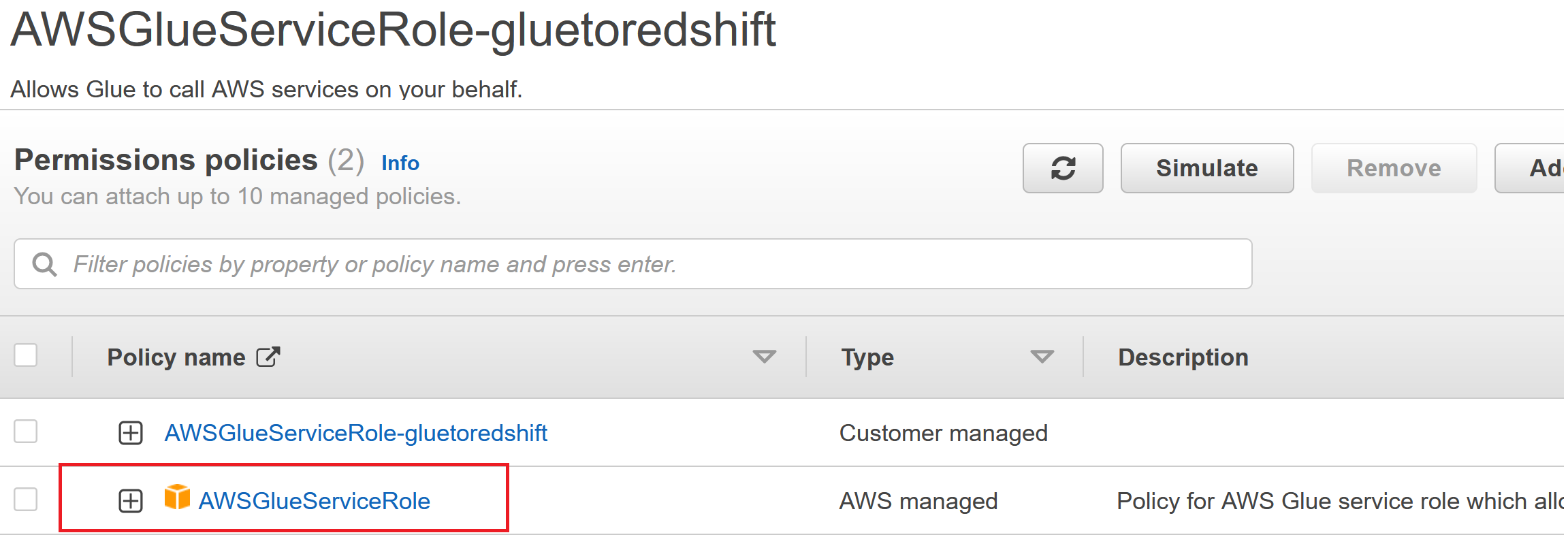
- IAM Role 创建,用于测试连接,包含策略AWSGlueServiceRole:
- Glue Connection 创建:
ConnectionType: 选择JDBC
JDBC URL:选择前面创建的Redshift Serverless的JDBC URL
Username/Password:选择Redshift Serverless的默认用户及密码
当设置好后,会默认给出Redshift Serverless所在的VPC,子网及安全组,并选择刚才创建的IAM role 测试连接,如果没问题,连接将成功
- Glue ETL job 创建,AWS Glue 是一种完全托管的数据目录和 ETL(提取、转换和加载)服务,Glue在后端使用的是spark serverless,一个典型的架构,当有文件在S3上传创建后,可以触发lambda来启动Glue ETL job,数据可以输出到不同的服务,比如AWS Redshift serverless 数据仓库
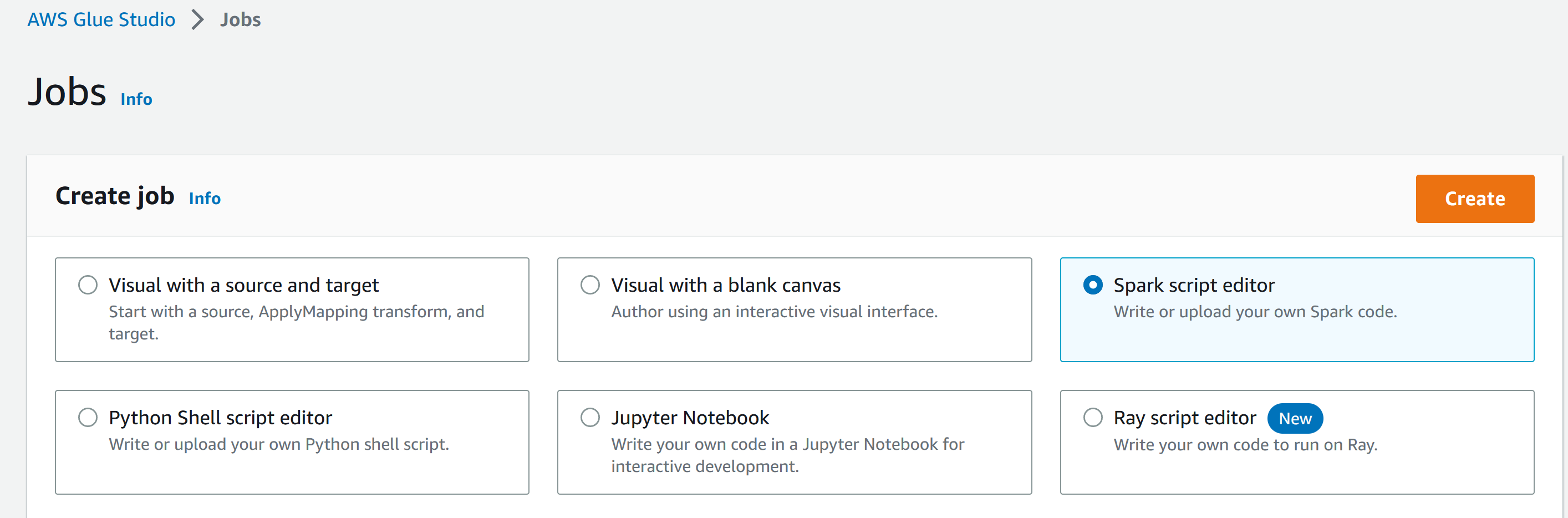
- 创建Glue job,选择Spark script editor
![]()
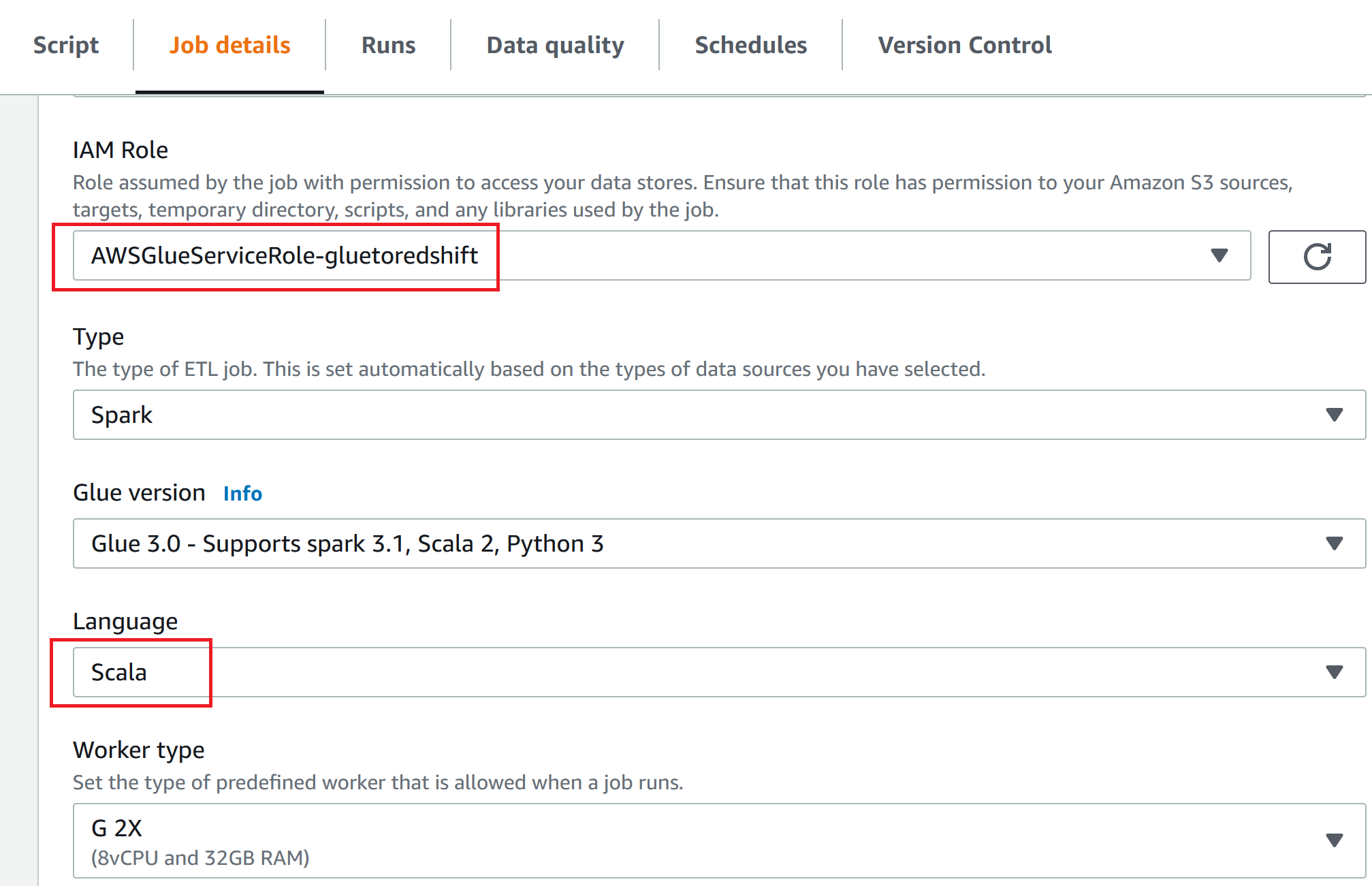
- 配置Job details 信息,选择前面创建的IAM Role,语音选择Scala,节点类型根据性能要求选择
![]()
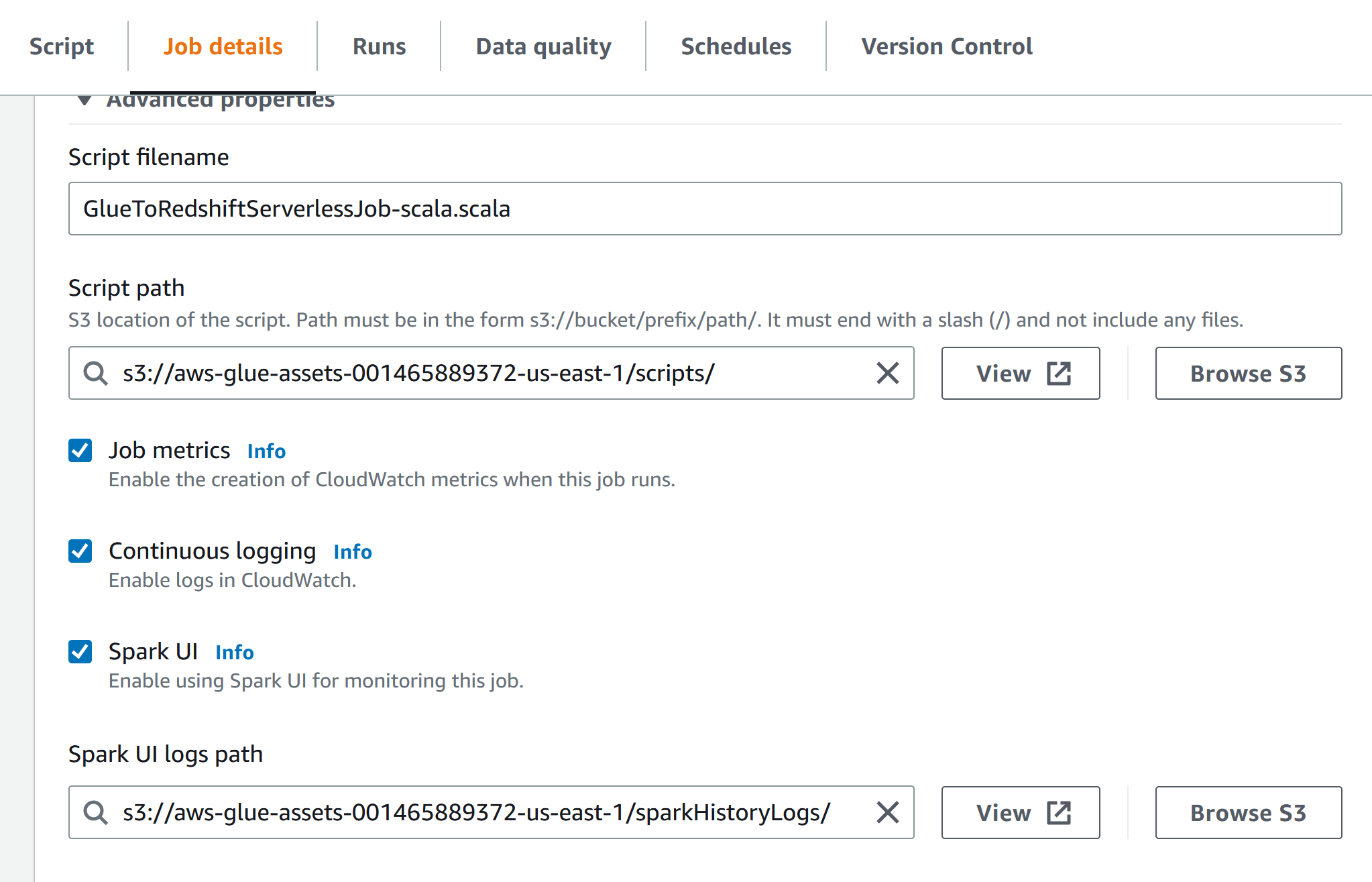
指定Spark 运行过程中的log 地址,这个log可以通过在本地启动docker来查看Spark UI,具体可以查看本文末尾的参考教程
![]()
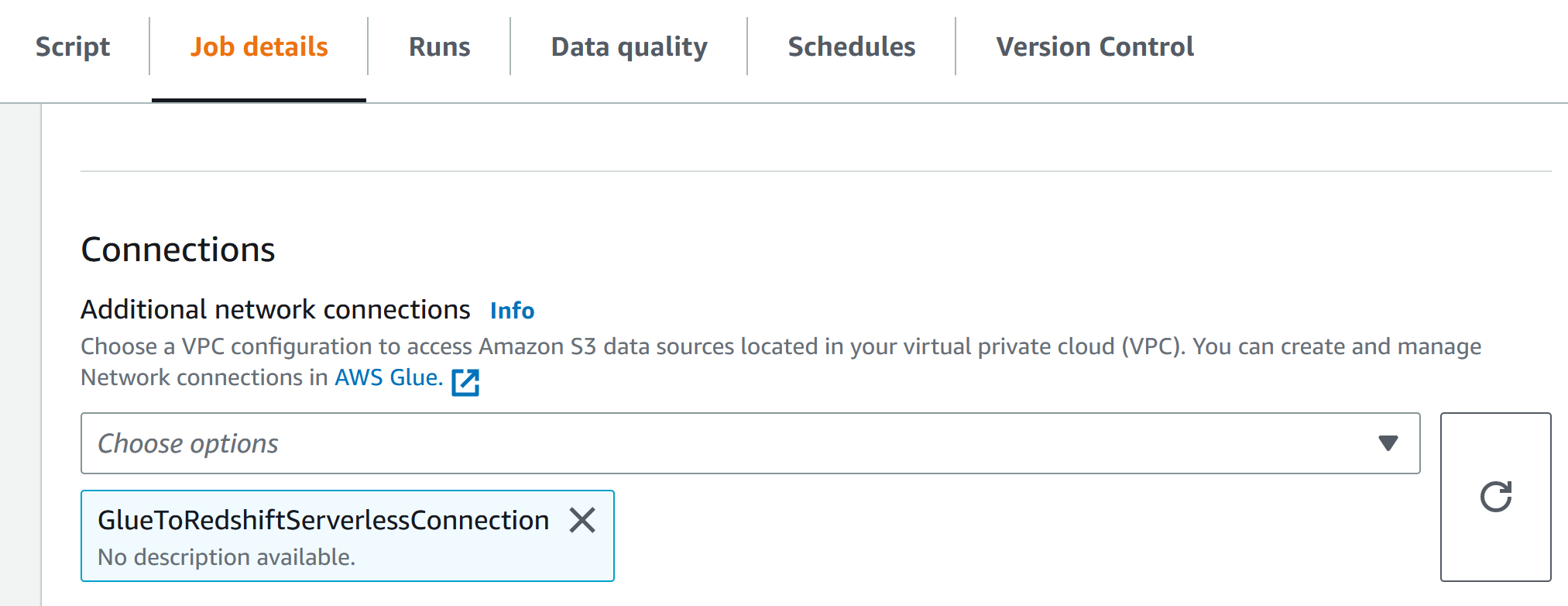
及connection
![]()
- 输入Scripts,Scala 语言,从S3读取文件,并将Spark DataFrame转成Glue DynamicFrame后,写入Redshift serverless,在写入的时候,在connection option中指定redshift serverless的jdbc 地址及redshift serverless的IAM role,以及redshift serverless workgroup 名字
import com.amazonaws.services.glue.GlueContext import com.amazonaws.services.glue.util.GlueArgParser import com.amazonaws.services.glue.util.Job import com.amazonaws.services.glue.util.JsonOptions import com.amazonaws.services.glue.DynamicFrame import java.util.Calendar import java.sql import org.apache.spark.SparkContext import org.apache.spark.sql.Dataset import org.apache.spark.sql.Row import org.apache.spark.sql.SaveMode import org.apache.spark.sql.SparkSession import org.apache.spark.sql.functions.from_json import org.apache.spark.sql.streaming.Trigger import org.apache.commons.lang.StringUtils import org.apache.commons.lang.time.DateUtils import scala.collection.JavaConverters._ import scala.util.Try object GlueApp { def main(sysArgs: Array[String]) { val spark: SparkContext = new SparkContext() val glueContext: GlueContext = new GlueContext(spark) val sparkSession: SparkSession = glueContext.getSparkSession // @params: [JOB_NAME] val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME").toArray) Job.init(args("JOB_NAME"), glueContext, args.asJava) GenerateIncrementalLotFile(sparkSession, glueContext) Job.commit() } private def GenerateIncrementalLotFile(sparkSession: SparkSession, glueContext: GlueContext): Unit = { import sparkSession.implicits._ val format = new java.text.SimpleDateFormat("yyyyMMdd") val folder = "s3://import-glue-taxlotinput-test/input/Pershing/" val date = "111422" var suffix = "POTL" var file = folder + date + "." + suffix var days = 16*8 val rddLot = sparkSession.sparkContext. textFile(file). filter(line => line != "" && !line.contains("PERSHING PES OPEN TAX LOTS")). filter(line => line.substring(0,3)=="TLB"). //get all lines starting with TLB map(line => (line.substring(11,20), line.substring(20,21), line.substring(21,30), Try(new java.sql.Date(DateUtils.addDays(format.parse(line.substring(42, 50)),days).getTime)).getOrElse (null), Try(new java.sql.Date(DateUtils.addDays(format.parse(line.substring(62, 70)),days).getTime)).getOrElse (null), Try(new java.sql.Date(DateUtils.addDays(format.parse(line.substring(70, 78)),days).getTime)).getOrElse (null), line.substring(78,96).toLong, line.substring(97,115).toLong)) //(rowkey, (account number, position type, cusip, as of date, ...)) //rowkey format: accountnumber_asofdate_cusip(9)_index(8) val rddLotX = rddLot.zipWithIndex().map { case (line, i) => (line._1 + "_" + line._4 + "_" + StringUtils.rightPad(line._3.trim, 9, "_") + "_" + StringUtils.leftPad(i.toString, 8, "0"), line._1, line._2, line._3, line._4, line._5, line._6, line._7, line._8 ) } rddLotX.cache() val dfLot = rddLotX.toDF("ROWKEY", "AccountNumber", "PositionType", "Cusip", "AsOfDate", "LotAcquisitionDate", "SettlementDate", "Share", "MarketValue") /* if us dataframe to write to redshift directly, it will be very slow dfLot.write.format("jdbc"). option("url", "jdbc:redshift://importtaxlot.001234567892.us-east-1.redshift-serverless.amazonaws.com:5439/taxlot"). option("dbtable", "lot"). option("user", "admin"). option("password", "Test1234"). option("redshiftTmpDir", "s3://import-glue-taxlotinput/temp"). option("aws_iam_role", "arn:aws:iam::001234567892:role/service-role/AmazonRedshift-CommandsAccessRole-20221201T162404"). mode("overwrite").save() */ val dynamicFrame = DynamicFrame(dfLot,glueContext) val my_conn_options = JsonOptions(Map( "url" -> "jdbc:redshift://importtaxlot.001234567892.us-east-1.redshift-serverless.amazonaws.com:5439/taxlot", "dbtable" -> "lot", "database" -> "taxlot", "user" ->"admin", "password" -> "Test1234", "redshiftTmpDir"->"s3://import-glue-taxlotinput-test/temp", "aws_iam_role" -> "arn:aws:iam::001234567892:role/service-role/AmazonRedshift-CommandsAccessRole-20221201T162404" ))
//下面2中写入方法都可以 glueContext.getSink("redshift", my_conn_options).writeDynamicFrame(dynamicFrame) //glueContext.getJDBCSink(catalogConnection = "GlueToRedshiftServerlessConnection", options = my_conn_options, redshiftTmpDir = "s3://import-glue-taxlotinput/temp").writeDynamicFrame(dynamicFrame) } }
- Redshift serverless 数据查询
我们可以通过多种方式查询在Redshift serverless里的数据
方法1:aws cli 命令,预先获取aws crendential 凭证
aws redshift-data execute-statement --database taxlot --workgroup-name importtaxlot --sql "{sql}"
//此处id 为前面命令返回的id aws redshift-data describe-statement --id {id} aws redshift-data get-statement-result --id {id}
方法2:在Postman中使用 Redshift REST Data API,预先获取aws crendential 凭证,在postman中将相应的header,body填好,如下所示,具体参考 REST for Redshift Data API
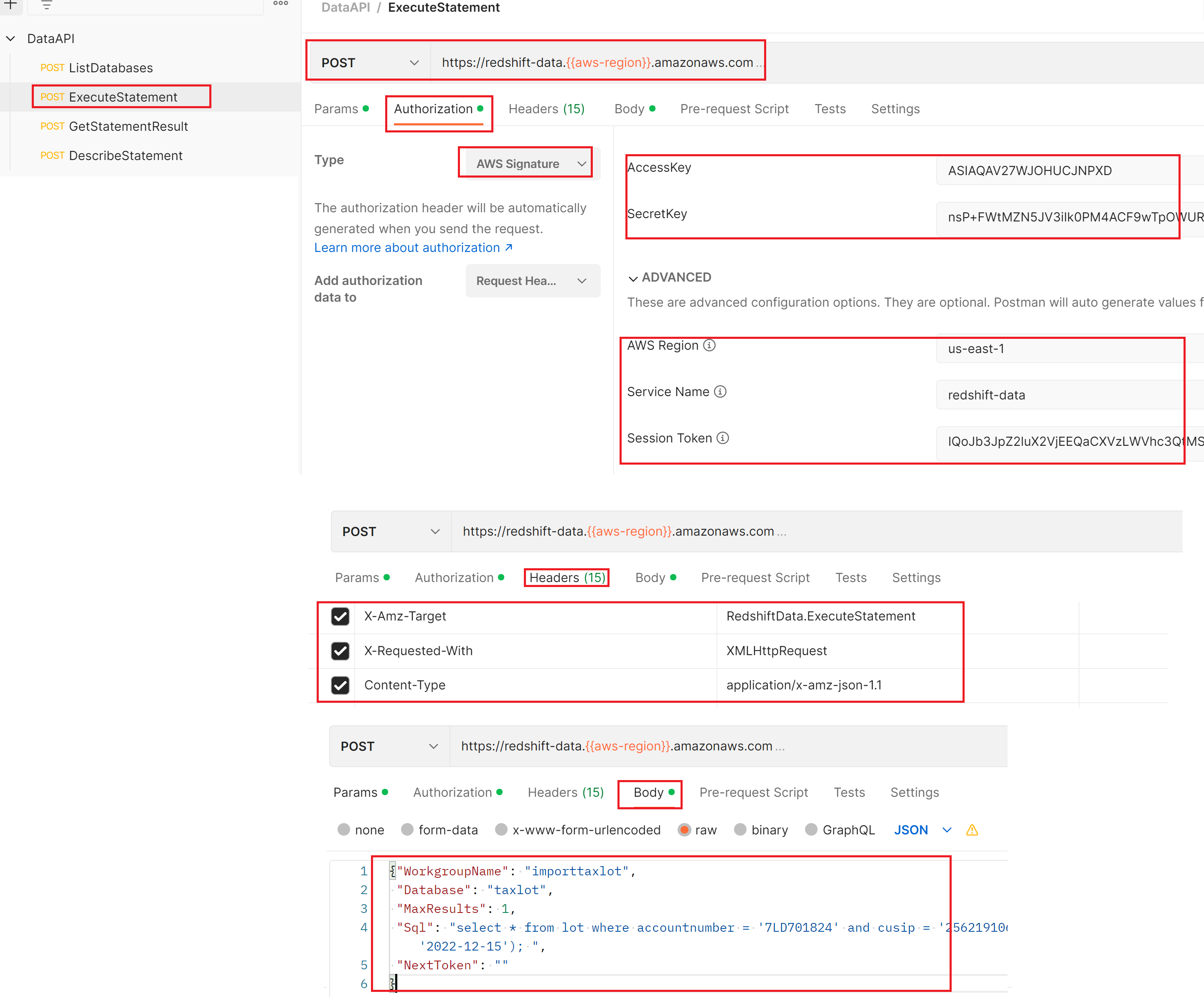
方法3:在JMeter中使用 Redshift REST Data API:
参考:
AWS SigV4 in JMeter | BlazeMeter| Blazemeter by Perforce
GitHub - jinlo02/Jmeter_AWS_Signature ,Jmeter 文件也可以从此处下载
方法4:Lambda 通过redshift data api 访问redshift serverless,请参考另外一篇文章 AWS Lambda 查询 Redshift Serverless
=========================================================================================================================================
遇到的错误及解决:
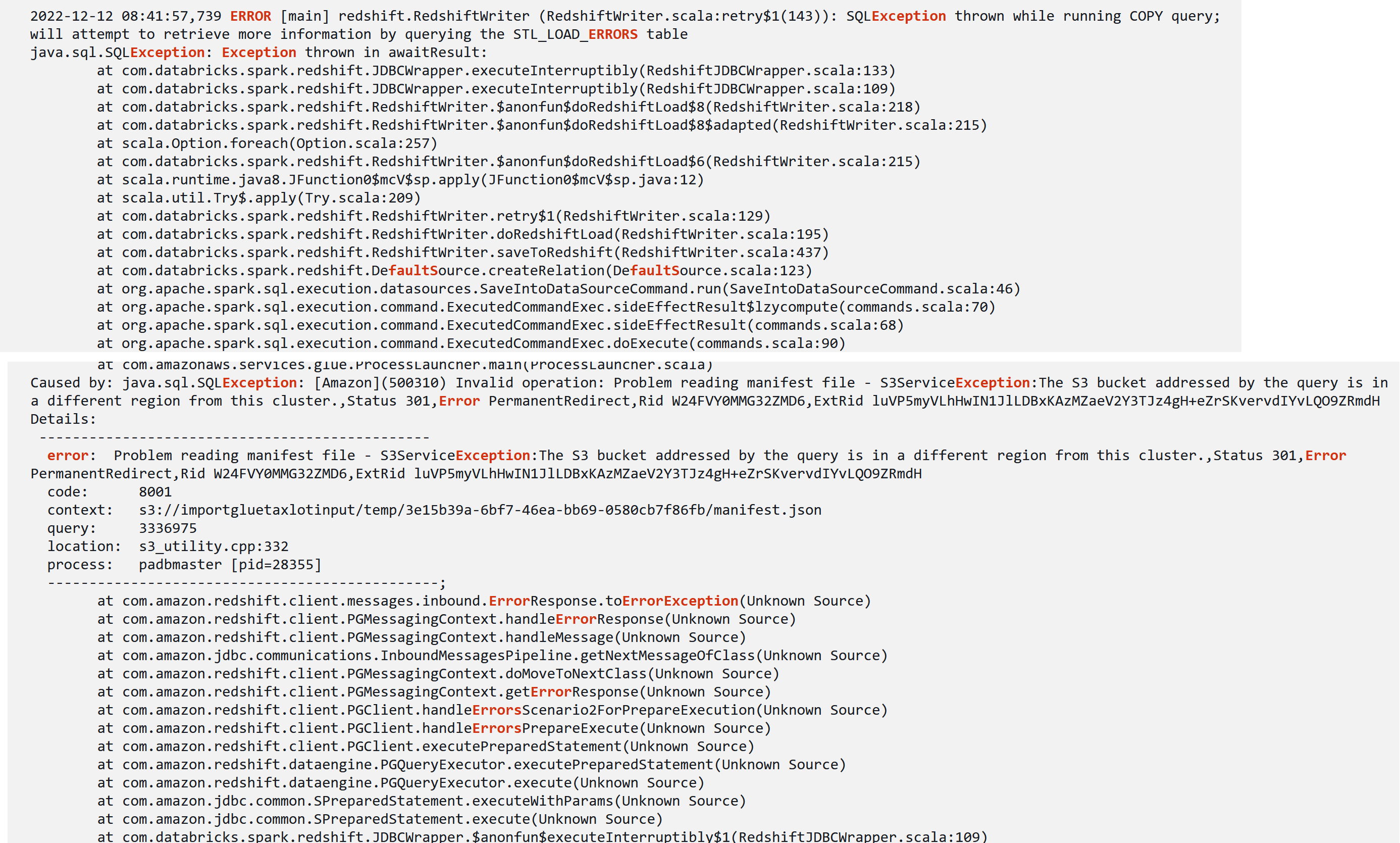
1: Glue job, s3 bucket and Redshift 在同一个region,否则会报如下错误
while running the job, temporary file are created as a folder in S3 bucket. you should have full permission to that bucket because data gets loaded to redshift from there.
2:在写入redshift 的时候,当用dataframe直接写入的时候,会异常慢,但没有报错,所以应当先把dataframe转成dynamicframe后,再写入redshift serverless
//dfLot is DataFrame,非常慢
dfLot.write.format("jdbc").
option("url", "jdbc:redshift://importtaxlot.001234567892.us-east-1.redshift-serverless.amazonaws.com:5439/taxlot").
option("dbtable", "lot").
option("user", "admin").
option("password", "Test1234").
option("redshiftTmpDir", "s3://import-glue-taxlotinput-test/temp").
option("aws_iam_role", "arn:aws:iam::001234567892:role/service-role/AmazonRedshift-CommandsAccessRole-20221201T162404").
mode("overwrite").save()
//将dataframe 转成DynamicFrame再写入redshift
val dynamicFrame = DynamicFrame(dfLot,glueContext)
val my_conn_options = JsonOptions(Map(
"url" -> "jdbc:redshift://importtaxlot.001234567892.us-east-1.redshift-serverless.amazonaws.com:5439/taxlot",
"dbtable" -> "lot",
"database" -> "taxlot",
"user" ->"admin",
"password" -> "Test1234",
"redshiftTmpDir"->"s3://import-glue-taxlotinput-test/temp",
"aws_iam_role" -> "arn:aws:iam::001234567892:role/service-role/AmazonRedshift-CommandsAccessRole-20221201T162404"
))
glueContext.getSink("redshift", my_conn_options).writeDynamicFrame(dynamicFrame)
参考:
Glue – “连接“功能介绍& Glue 通过连接对 Redshift 写入数据
使用 Docker 启动 Spark 历史记录服务器并查看 Spark UI
先获取aws crendential 凭证,在本机安装好docker,在下面的命令中填入凭证后,启动docker,然后在浏览器中打开 http://localhost:18080就可以查看glue 运行的spark运行图
docker run -itd -e SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=s3a://{Spark UI logs path} -Dspark.hadoop.fs.s3a.access.key={aws_access_key_id} -Dspark.hadoop.fs.s3a.secret.key={aws_secret_access_key} -Dspark.hadoop.fs.s3a.session.token=I{aws_session_token} -Dspark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider" -p 18080:18080 glue/sparkui:latest "/opt/spark/bin/spark-class org.apache.spark.deploy.history.HistoryServer"
如果想进入容器的目录,可以执行命令:
docker container exec -it {容器id} /bin/sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号