SparkSQL 数据分页及Top N
在SparkSQL实践中,取出满足指定条件的数据并显示,如果因为数据太多,必须要有分页功能,一开始,想到的是select top N的方式,但测试过后,SparkSQL中并不支持这种语法,查了SparkSQL的帮助,spark支持类似mysql的limit语法,如下例所示,limit表示取出满足条件的前N条记录:
val df = spark.sql("select a, b from tb1 where a>100 limit 10")
但limit仅仅实现了非常简单的类似top N的功能,还不能很好的查找某个区间范围的记录,比如分页显示,那还有什么其它方法吗?
当然,还有更好的方法,在SparkSQL中,有一项更好的功能,row_number,这是一个窗口函数(window function),从spark1.5版本引入,语法格式为:
row_number() over (partition by 'xx' order by 'yy' desc) rank
具体含义为:根据表中字段进行分组(partition by),然后根据表中的字段排序(order by),对于每个分组,给每条记录添加一个从1开始的行号
如果不使用partition by语句,则表示对整个dataframe表添加行号
对此行号做分页查询,下面是一个例子:
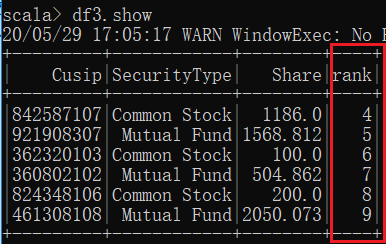
val df3 = spark.sql("select Cusip, SecurityType, Share, rank from (select *,row_number() over (order by Date , AccountNumber desc) as rank from holding where Month = \"2000-06\") temp
where 3 < rank and rank <= 9")
在上面sql中,取出的是满足rank在某个区间的记录,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号