
学习@RequestBody注解解析请求参数流程
一、背景
研究对象是Springboot的一个后台Web系统。
想了解,在SpringMVC对@RequestBody的参数进行注入之前,执行了request.getInputStream()/request.getReader()或者request.getParameter()方法,会不会对参数的获取造成影响。也就是@RequestBody是如何获取到Http请求体中的参数的。
二、Controller中Handler的注册
留意到每次系统启动的时候,Spring会打印这类日志
Mapped "{[/xxx/yyyy/aaa],methods=[POST]}" onto ......
因此,对于Controller中对RequestMapping的解析,就从此处的日志开始。看看在解析RequestMapping的时候,有没有对@RequestBody注解的参数进行处理。
- 找到打印这行日志的类以及行数, RequestMappingHandlerMapping:547.
发现这个类中总共都没有547行,那么就去它继承的父类中去找,结果在AbstractHandlerMethodMapping这个类中找到了对应的行和方法。
public void register(T mapping, Object handler, Method method) {
// 省略
}
从方法名以及参数上来看,肯定是将Controller中每个RequestMapping对应的Method注册起对应关系。但是入参到底是啥也不清楚,那么就看哪些地方调用了这个方法。
发现了如下的调用链路:
AbstractHandlerMethodMapping#initHandlerMethods
AbstractHandlerMethodMapping#detectHandlerMethods
AbstractHandlerMethodMapping#registerHandlerMethod
AbstractHandlerMethodMapping#register
- 那么从initHandlerMethods开始看
protected void initHandlerMethods() {
// 省略,获取所有beanNames
for (String beanName : beanNames) {
if (!beanName.startsWith(SCOPED_TARGET_NAME_PREFIX)) {
Class<?> beanType = null;
try {
beanType = obtainApplicationContext().getType(beanName);
}
catch (Throwable ex) {
// An unresolvable bean type, probably from a lazy bean - let's ignore it.
if (logger.isDebugEnabled()) {
logger.debug("Could not resolve target class for bean with name '" + beanName + "'", ex);
}
}
// 关键代码处
if (beanType != null && isHandler(beanType)) {
detectHandlerMethods(beanName);
}
}
}
handlerMethodsInitialized(getHandlerMethods());
}
在这个方法中的关键代码处可以看到,会对bean进行判断isHandler, 如果是Handler,那么就去解析里面的Methods
@Override
protected boolean isHandler(Class<?> beanType) {
return (AnnotatedElementUtils.hasAnnotation(beanType, Controller.class) ||
AnnotatedElementUtils.hasAnnotation(beanType, RequestMapping.class));
}
可以看到,只要是有@Controller或者@RequestMapping的Bean,都是Handler。
也可以看到所谓的Handler就是我们日常说的身为Controller的Bean。
3. 继续进入detectHandlerMethods方法中
Class<?> handlerType = (handler instanceof String ?
obtainApplicationContext().getType((String) handler) : handler.getClass());
if (handlerType != null) {
final Class<?> userType = ClassUtils.getUserClass(handlerType);
Map<Method, T> methods = MethodIntrospector.selectMethods(userType,
(MethodIntrospector.MetadataLookup<T>) method -> {
try {
return getMappingForMethod(method, userType); //关键处1
}
catch (Throwable ex) {
throw new IllegalStateException("Invalid mapping on handler class [" +
userType.getName() + "]: " + method, ex);
}
});
if (logger.isDebugEnabled()) {
logger.debug(methods.size() + " request handler methods found on " + userType + ": " + methods);
}
methods.forEach((method, mapping) -> {
Method invocableMethod = AopUtils.selectInvocableMethod(method, userType);
registerHandlerMethod(handler, invocableMethod, mapping); //关键处2
});
}
这个方法就是获取Controller中的所有方法,并一个个去解析
在关键处1,里面所做的事情就是先判断这个方法是否有@RequestMapping注解,其次获取注解里面的信息(请求头、请求方法,请求参数等)并记录到RequestMappingInfo对象中。 并且假如Controller上也有RequestMapping注解,那就还要进行一些合并操作。都做完了就返回一个整体的RequestMappingInfo对象
在关键处2,就是建立Mapping与Method的映射关系,等到实际调用的时候,根据请求的地址解析得到Mapping,取出相应的Method进行调用。
当然这里面是有代理的,具体细节就没有去详细看。因为我的目的是先了解流程。
在这个解析过程中,好像并没有对@RequestBody的处理,那么就看看在实际调用的时候,是怎么处理@RequestBody的
二、@RequestBody参数解析
一个Http请求,必然从Servlet的doService开始的(抛开拦截器与过滤器),那么就从SpringMVC的DispatcherServlet开始入手。顺着doService看到doDispatch,然后doDispatch中可以看到一行:
// Actually invoke the handler.
mv = ha.handle(processedRequest, response, mappedHandler.getHandler());
那么实际的接口处理流程就应该是在这里面了,跟进可以看到RequestMappingHandlerAdapter#handleInternal方法中,
mav = invokeHandlerMethod(request, response, handlerMethod);
从方法名就可以看出是进行Controller中的Method调用的,继续跟进去,会发现RequestMappingHandlerAdapter有一个成员变量是argumentResolvers,那么从名称来看,很大概率就是我想要找到的参数解析器。
这个argumentResolvers是个HandlerMethodArgumentResolverComposite类的实例,进入这个类中,就有一个HandlerMethodArgumentResolver数组,里面就是所有的参数解析器了。
继续在这个类中往下看看,会发现这么两个方法:
@Override
@Nullable
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
HandlerMethodArgumentResolver resolver = getArgumentResolver(parameter);
if (resolver == null) {
throw new IllegalArgumentException("Unknown parameter type [" + parameter.getParameterType().getName() + "]");
}
return resolver.resolveArgument(parameter, mavContainer, webRequest, binderFactory);
}
/**
* Find a registered {@link HandlerMethodArgumentResolver} that supports the given method parameter.
*/
@Nullable
private HandlerMethodArgumentResolver getArgumentResolver(MethodParameter parameter) {
HandlerMethodArgumentResolver result = this.argumentResolverCache.get(parameter);
if (result == null) {
for (HandlerMethodArgumentResolver methodArgumentResolver : this.argumentResolvers) {
if (logger.isTraceEnabled()) {
logger.trace("Testing if argument resolver [" + methodArgumentResolver + "] supports [" +
parameter.getGenericParameterType() + "]");
}
if (methodArgumentResolver.supportsParameter(parameter)) {
result = methodArgumentResolver;
this.argumentResolverCache.put(parameter, result);
break;
}
}
}
return result;
}
先不去追究细节,这两个方法所表达出来的意思很明了。先根据Controller中的Method中的参数,来获取到对应的解析器,也就是HandlerMethodArgumentResolver的一个实例。然后用这个解析器来解析参数。
其中,获取解析器的时候,会先从缓存中获取,如果缓存中没有,那么就遍历所有的解析器,找到一款能够解析这个参数的解析器,并存入缓存中。
对于@RequestBody的解析器,可以先看看HandlerMethodArgumentResolver有哪些实现类,发现有很多种解析器,包括我们常用的一些@RequestParam,@RequestHeader等等
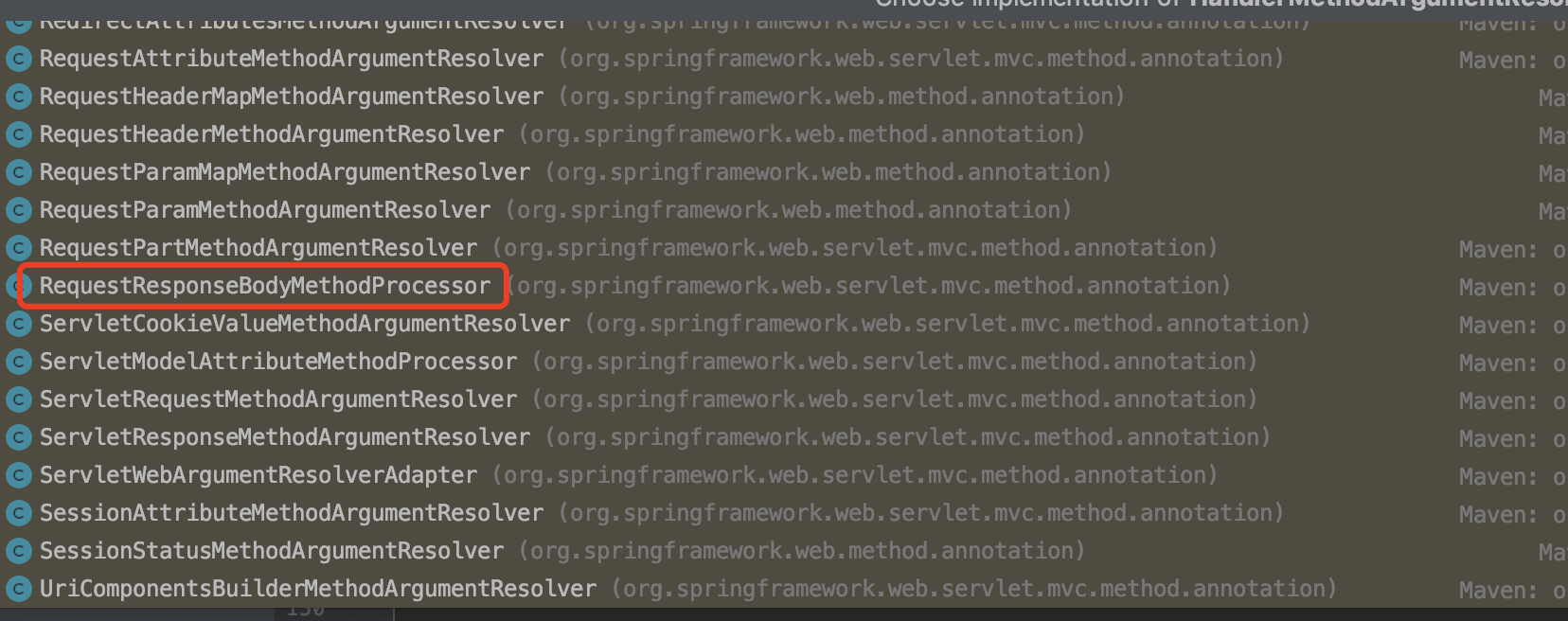
其中想要去看到就是框红的那个。进入这个类中,找到resolveArgument方法:
/**
* Throws MethodArgumentNotValidException if validation fails.
* @throws HttpMessageNotReadableException if {@link RequestBody#required()}
* is {@code true} and there is no body content or if there is no suitable
* converter to read the content with.
*/
@Override
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
parameter = parameter.nestedIfOptional();
Object arg = readWithMessageConverters(webRequest, parameter, parameter.getNestedGenericParameterType());
String name = Conventions.getVariableNameForParameter(parameter);
if (binderFactory != null) {
WebDataBinder binder = binderFactory.createBinder(webRequest, arg, name);
if (arg != null) {
validateIfApplicable(binder, parameter);
if (binder.getBindingResult().hasErrors() && isBindExceptionRequired(binder, parameter)) {
throw new MethodArgumentNotValidException(parameter, binder.getBindingResult());
}
}
if (mavContainer != null) {
mavContainer.addAttribute(BindingResult.MODEL_KEY_PREFIX + name, binder.getBindingResult());
}
}
return adaptArgumentIfNecessary(arg, parameter);
这个方法也是有两步,先readWithMessageConverters解析参数,后面就是对这个参数进行校验,比如你使用了require=true,或者@Valid/@Validate。
接着readWithMessageConverters往里走,来到了AbstractMessageConverterMethodArgumentResolver#readWithMessageConverters中,其中对于我想要了解的东西,最关键的一行代码就是
message = new EmptyBodyCheckingHttpInputMessage(inputMessage);
在这个构造函数里面可以看到
public EmptyBodyCheckingHttpInputMessage(HttpInputMessage inputMessage) throws IOException {
this.headers = inputMessage.getHeaders();
InputStream inputStream = inputMessage.getBody();
if (inputStream.markSupported()) {
inputStream.mark(1);
this.body = (inputStream.read() != -1 ? inputStream : null);
inputStream.reset();
}
else {
PushbackInputStream pushbackInputStream = new PushbackInputStream(inputStream);
int b = pushbackInputStream.read();
if (b == -1) {
this.body = null;
}
else {
this.body = pushbackInputStream;
pushbackInputStream.unread(b);
}
}
}
这里面就对输入流进行了包装处理,流程图:
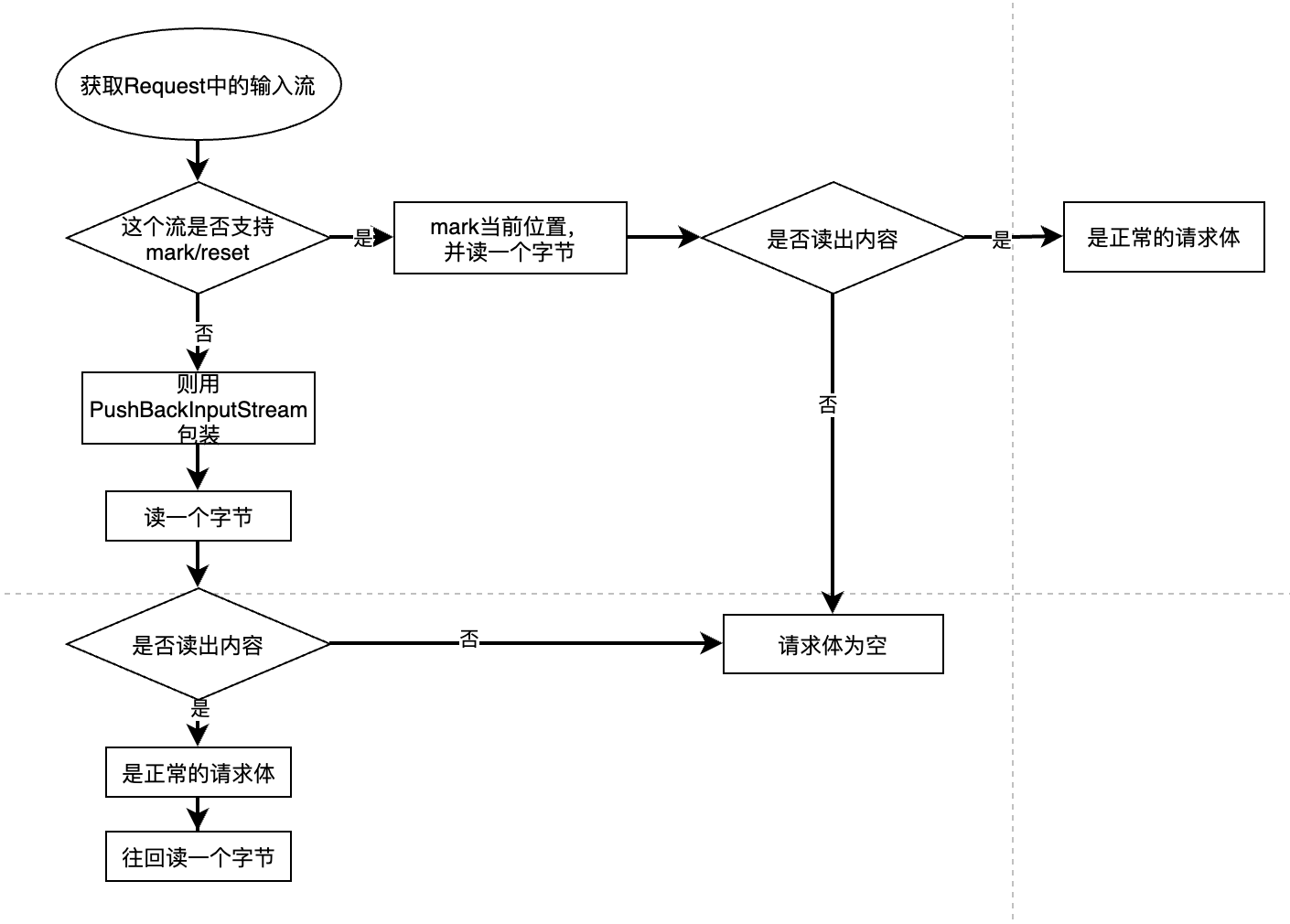
其中PushbackInputStream,就是增加了一个unread功能。read是往前读一个字节,而unread就是往后读一个自己。
三、结论
-
request.getParameter()不会对@RequestBody的解析造成影响,因为这完全是两种获取参数的方式,两个赛道。对于POST请求而言,getParameter是解析application/x-www-form-urlencoded类型的参数,而@RequestBody是解析application/json类型的参数
-
一般情况下,假如你在过滤器或任何@RequestBody解析之前的地方,读完了请求流,那么@RequestBody是获取不到参数内容的。
-
因此对于需要可重复读的请求流,一般网上也给了方案,对Request进行一层包装,且要覆写其中的getInputStream方法,这样才能随便通过getInputStream来读请求流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号