
刨根究底字符编码之十三——UTF-16编码方式
UTF-16编码方式

1.
UTF-16编码方式源于UCS-2(Universal Character Set coded in 2 octets、2-byte Universal Character Set)。而UCS-2,是早期遗留下来的历史产物。
UCS-2将字符编号直接映射为字符编码(CEF,而非CES,详见前文中对现代字符编码模型的解释),亦即字符编号就是字符编码,中间没有经过特别的编码算法转换。因此,从现代字符编码模型的角度来看的话,此时并没有将编号字符集CCS与字符编码方式CEF作严格区分,既可以将UCS-2看作是编号字符集CCS中的字符编号,也可以看作是字符编码方式CEF中的字符编码。
后来,随着Unicode联盟与ISO/IEC就创建全球统一的单一通用字符集进行合作,Unicode字符集与UCS字符集逐渐相互融合,两者最终基本保持了一致(详见前文《刨根究底字符编码之八——Unicode编码方案概述》中的介绍)。
(笨笨阿林原创文章,转载请注明出处)
2.
这之后,Unicode逐渐占据了主导地位,并引入了UTF-16编码方式。为什么要引入UTF-16编码方式呢?
前文已经介绍过了,Unicode字符集(CCS)到目前为止定义了包括1个基本平面BMP和16个增补平面SP在内的共17个平面。
每个平面的码点数量为2^16=65536个,因此17个平面的码点总数为共65536*17=1114112个。其中,基本平面码点为65536个(码点编号范围为0x0000~0xFFFF),增补平面码点为1114112-65536=65536*16=1048576个(码点编号范围为0x10000~0x10FFFF)。
很明显,简单地用一个16位码元肯定无法表示所有17个平面的这么多码点(因为2^16=65536,而码点总数为65536*17=1114112)。而UCS-2,正是用两个字节共16位来表示一个字符的。为支持字符编号超过U+FFFF的增补字符,扩展势在必行。
3.
UCS因而又提出了UCS-4,即用四个字节共32位来表示一个字符(此时UCS-4同样既可认为是编号字符集CCS中的字符编号,也可认为是字符编码方式CEF中的字符编码)。但码元也因此从16位扩展到了32位。
而Unicode却提出了不同的扩展方式——代理机制。具体而言,就是为了能以一个统一的16位码元同时编码基本平面以及增补平面中的字符码点编号,Unicode设计引入了UTF-16编码方式,并且通过代理机制实现了扩展。
UTF-16编码方式的引入,从现代字符编码模型的角度来看的话,彻底将编号字符集CCS与字符编码方式CEF作了严格区分。也就是说,在UTF-16编码方式中,编号字符集CCS中的字符编号与字符编码方式CEF中的字符编码不再仅仅是简单的直接映射关系。
具体来说,就是Unicode字符集基本平面BMP中的字符(大致相当于UCS字符集中的UCS-2字符,但必须除开U+D800~U+DFFF这一在Unicode字符集BMP中称之为代理码点的部分),仍然是直接映射关系,亦即这部分字符的字符编号与字符编码是等同的。
但Unicode字符集增补平面中的字符(大致相当于UCS字符集UCS-4字符中除开UCS-2字符的部分,因为广义上的UCS-4字符实际上包含了UCS-2字符,当然狭义上的UCS-4字符不包括UCS-2字符),却不是直接映射关系,而是必须通过代理机制这一编码算法的转换,亦即这部分字符的字符编号与字符编码不是等同的。
因此,在Unicode引入了UTF-16编码方式之后,站在现代字符编码模型的角度上来看的话,再将UCS-2和UCS-4直接称之为字符编码方式CEF已不是很合适,更多的应该是编号字符集CCS中的概念(当然,在了解其历史原因之后,将UCS-2和UCS-4同时理解为编号字符集CCS和字符编码方式CEF也未尝不可);而若将UCS-2等同于UTF-16,将UCS-4等同于UTF-32(后文会有介绍),显然也是不合适的。
(笨笨阿林原创文章,转载请注明出处)
4.
UTF-16中的所谓代理机制,实际上就是用两个对应于基本平面BMP代理区(Surrogate Zone)中的码点编号的16位码元来表示一个增补平面码点,这两个用来表示一个增补平面码点的特殊16位码元被称之为代理对(Surrogate Pair)(解释详见后文《UTF-16究竟是如何编码的——UTF-16的编码算法详解》)
UTF-16编码方式及其代理机制是在Unicode 2.0中为支持字符编号超过U+FFFF的增补字符而引入的,于是从此就由UCS-2的等宽(16位)码元序列编码方式(如前文所述,从现代字符编码模型的角度来看的话,UCS-2更多是的编号字符集CCS中的概念,但考虑到其历史原因,称之为字符编码方式CEF亦未尝不可,下同,不再赘述),变成了UTF-16的变宽(16位或32位)码元序列编码方式。不过,码元依然保持了16位不变。
5.
UCS-2所编码的字符集中的U+D800~U+DFFF这部分代理码点除外的话,UTF-16所编码的字符集可看成是UCS-2所编码的字符集的父集。
在没有引入增补平面字符之前,UTF-16与UCS-2(U+D800~U+DFFF这部分代理码点除外)的编码完全相同。但当引入增补平面字符后,UTF-16与UCS-2的编码就不完全相同了(事实上,由于UCS-2只有两个字节,根本无法编码增补平面字符)。
现在若有软件声称自己支持UCS-2编码,那相当于是在暗示其仅支持UCS字符集或Unicode字符集中的基本平面字符,而不能支持增补平面字符。
6.
所以说,UTF-16是变长编码方式,每个字符编码为2字节或4字节;而UCS-2是定长编码方式,每个字符编码固定为2字节。
另外,UTF-16中,大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。
Windows 2000及之后的版本是支持UTF-16的,之前的Windows NT/95/98/ME是只支持UCS-2的。
(笨笨阿林原创文章,转载请注明出处)
7.
作为逻辑意义上的UTF-16编码(码元序列),由于历史的原因,在映射为物理意义上的字节序列时,分为UTF-16BE(Big Endian)、UTF-16LE(Little Endian)两种情况。比如,“ABC”这三个字符的UTF-16编码(码元序列)为:00 41 00 42 00 43;其对应的各种字节序列如下:
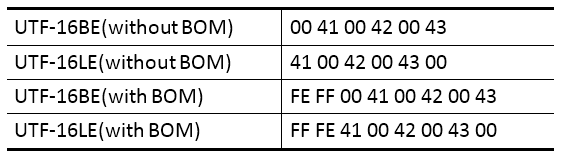
Windows平台下的UTF-16编码(即上述的FF FE 41 00 42 00 43 00) 默认为带有BOM的小端序(即Little Endian with BOM)。你可以打开记事本,写上ABC,保存时选择Unicode(这里的Unicode实际上指的是UTF-16 Little Endian with BOM,即带BOM的UTF-16小端序CES编码,详见后文解释)

然后保存,再用UltraEdit编辑器看看它的编码结果:
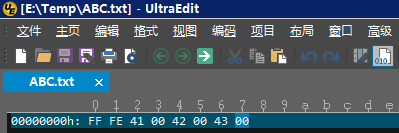
Windows从NT时代开始就采用了UTF-16编码方式,很多流行的编程平台,例如.Net、Java、Qt还有Mac下的Cocoa等都是使用UTF-16作为基础的字符编码。例如代码中的字符串,在内存中相应的字节流就是UTF-16字节序列的。(注意,UTF-16编码在Windows环境中被误用为“widechar”和“Unicode”的同义词)
8.
UTF-16一方面使用变长码元序列的编码方式,相较于定长码元序列的UTF-32算法更复杂(甚至比同样是变长码元序列的UTF-8也更为复杂,因为引入了独特的代理对这样的代理机制);另一方面仍然占用过多字节,比如ASCII字符也同样需要占用两个字节,相较于UTF-8更浪费空间和带宽。
因此,UTF-16在Unicode字符集的三大编码方式(UTF-8、UTF-16、UTF-32)中表现较为糟糕。它的存在是历史原因造成的,引起了很多混乱。不过由于其推出时间最早,已被应用于大量环境中,目前虽然不被推荐使用,但长期来看,作为程序人员都不得不与之打交道。因而,对于其具体的编码算法的了解是十分必要的,本系列文章的下一篇将详细介绍其复杂的编码算法(主要是代理编码算法)。
(笨笨阿林原创文章,转载请注明出处)
(未完待续)
【预告:本《刨根究底字符编码》系列的下一篇将详细介绍UTF-16复杂的编码算法;而《刨根究底正则表达式》系列的下一篇将正式开始逐个正则表达式语法元素的详解,敬请关注!】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号