刨根究底字符编码之六——简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系
简体汉字编码中区位码、国标码、内码、外码、字形码的区别及关系

下面以GB2312为例来加以说明(由于GBK、GB18030是以GB2312为基础扩展而来,因此编码实现方式与GB2312一样)。
一、区位码
1.
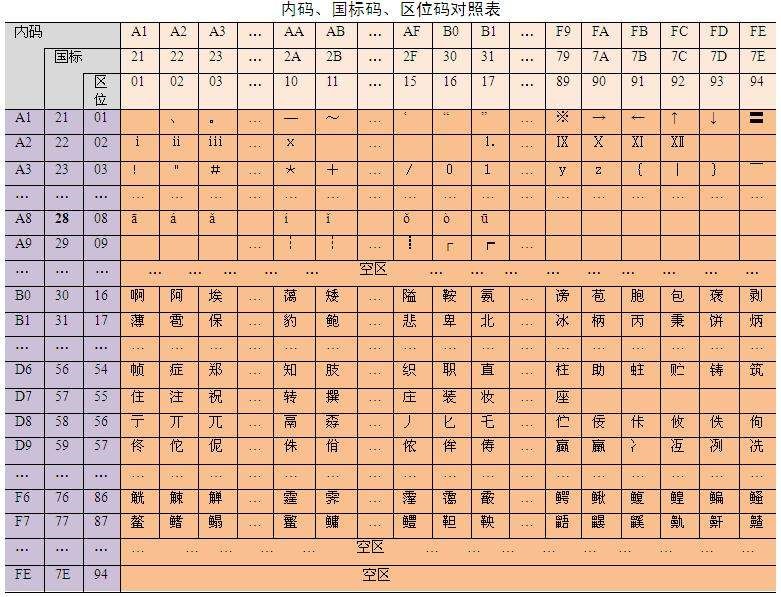
整个GB2312字符集分成94个区,每区有94个位,每个区位上只有一个字符,即每区含有94个汉字或符号,用所在的区和位来对字符进行编码(实际上就是字符编号、码点编号),因此称为区位码(或许叫“区位号”更为恰当)。
换言之,GB2312将包括汉字在内的所有字符编入一个94 * 94的二维表,行就是“区”、列就是“位”,每个字符由区、位唯一定位,其对应的区、位编号合并就是区位码。比如“万”字在45区82位,所以“万”字的区位码是:45 82(注意,GB类汉字编码为双字节编码,因此,45相当于高位字节,82相当于低位字节)。
2.
GB2312字符集中:
1)01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
2)10~15区:空区,留待扩展;
3)16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
4)56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
5)88~94区:空区,留待扩展。
二、国标码(交换码)
1.
为了避开ASCII字符中的不可显示字符0000 0000 ~ 0001 1111(十六进制为0 ~ 1F,十进制为0 ~ 31)及空格字符0010 0000(十六进制为20,十进制为32)(至于为什么要避开、又为什么只避开ASCII中0~32的不可显示字符和空格字符,后文有解释),国标码(又称为交换码)规定表示汉字的范围为(0010 0001,0010 0001) ~ (0111 1110,0111 1110),十六进制为(21,21) ~ (7E,7E),十进制为(33,33) ~ (126,126)(注意,GB类汉字编码为双字节编码)。
因此,必须将“区码”和“位码”分别加上32(十六进制为20H,后缀H表示十六进制),作为国标码。也就是说,国标码相当于将区位码向后偏移了32,以避免与ASCII字符中0~32的不可显示字符和空格字符相冲突。
2.
注意,国标码中是分别将区位码中的“区”和“位”各自加上32(20H)的,因为GB2312是DBCS双字节字符集,国标码属于双字节码,“区”和“位”各作为一个单独的字节。
这样我们可以算出“万”字的国标码十进制为:(45+32,82+32) = (77,114),十六进制为:(4D,72H),二进制为:(0100 1101,0111 0010)。
(笨笨阿林原创文章,转载请注明出处)
三、内码(机内码)
1.
不过国标码还不能直接在计算机上使用,因为这样还是会和早已通用的ASCII码冲突(导致乱码)。
比如,“万”字国标码中的高位字节77与ASCII的“M”冲突,低位字节114与ASCII的“r”冲突。因此,为避免与ASCII码冲突,规定国标码中的每个字节的最高位都从0换成1,即相当于每个字节都再加上128(十六进制为80,即80H;二进制为1000 0000),从而得到国标码的“机内码”表示,简称“内码”。
2.
由于ASCII码只用了一个字节中的低7位,所以,这个首位(最高位)上的“1”就可以作为识别汉字编码的标志,计算机在处理到首位是“1”的编码时就把它理解为汉字,在处理到首位是“0”的编码时就把它理解为ASCII字符。
比如:
77 + 128 = 205(二进制为1100 1101,十六进制为CD)
114+ 128 = 242(二进制为1111 0010,十六进制为F2)
3.
我们可以来检验一下。打开记事本输入“万”字,编码选择为ANSI(Windows记事本中的ANSI编码对于简体汉字而言就是GB类编码,详见后文解释),保存,如下图所示。
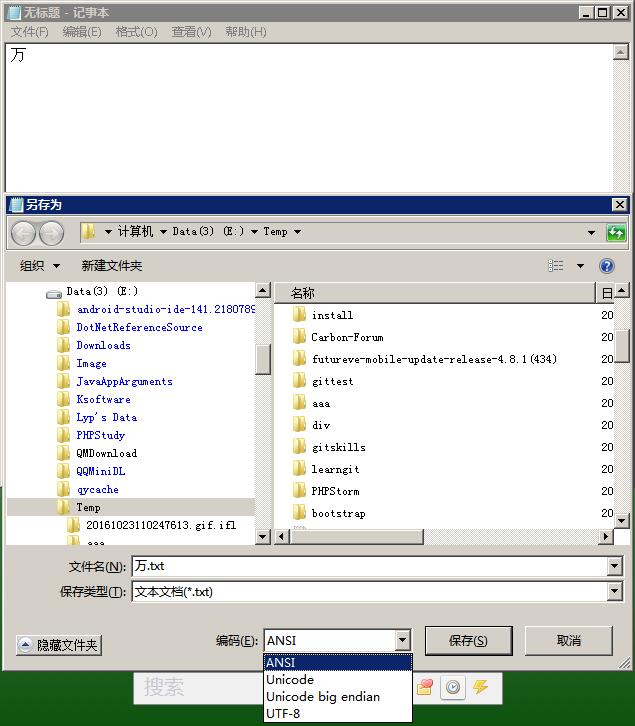
然后用二进制编辑器(比如UltraEdit)打开刚才保存的文件,切换到十六进制模式,会看到:CD F2,这就是“万”字的内码,如下图所示。
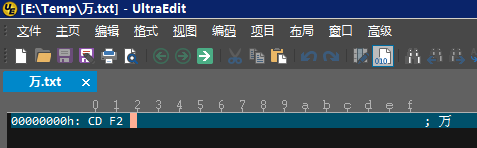
总结一下:
从区位码(国家标准定义) ---> 区码和位码分别+32(即+20H)得到国标码 ---> 再分+128(即+80H)得到机内码(与ACSII码不再冲突)。
因此,区位码的区和位分别+160(即+A0H,32+128=160)可直接得到内码。用十六进制表示就是:
区位码(区码,位码) + (20H,20H) + (80H,80H) =区位码(区码,位码) + (A0H,A0H) = 内码(高字节,低字节)。

四、为什么要加上20H和80H?
1.
区位码、国标码、内码的转换非常简单,但是令人迷惑的是为什么要这么转换?
首先,需要注意到一点,GB2312虽说是对中文编码,但是里面也有对26个英文字母和一些特殊符号的编码,按理说这些和ASCII重合的字符(33~127)应该无需再重新编码,直接沿用ASCII中的不就行了?
2.
原来,当时在制定GB2312时,决定对ASCII中的可打印字符,也就是英文字母、数字和符号部分(33~126,127为不可打印的DEL)重新编入GB2312中,以两个字节表示,称之为全角字符(全角字符在屏幕上的显示宽度为ASCII字符的两倍,后来也因此而将对应的ASCII字符称之为半角字符)。
而对于ASCII中前32个不可显示也不可打印的控制字符(ASCII码为0~31),以及第33个可显示但不可打印的空格字符(ASCII码为32)等共33个不可打印字符的编码则直接沿用,不再重新编码。
3.
因为要保留这33个不可打印字符,就不能直接采用区位码作为计算机直接处理的机内码,需要将区位码向后偏移32以避开冲突(为什么是偏移32,而不是偏移33?因为区位码中的区码和位码都是从1开始计数的,不像ASCII码是从0开始计数的)。
十进制数字32的十六进制表示就是20(为区别于十进制,记作20H),这也就是区位码要加上20H(区码和位码各自加上20H)才能得到国标码的原因。
(笨笨阿林原创文章,转载请注明出处)
3.
很显然,如果直接采用国标码作为计算机直接处理的机内码的话,还将会产生另一个弊端,即用ASCII码编码的英文字符在GB2312编码环境中无法打开,一打开就会乱码。
因为国标码虽然相较于区位码避开了ASCII码中0~32的前33个不可打印字符,但并没有避开ASCII码中的英文字母、数字和符号(33~126,共94个字符,127为不可打印的DEL)等可打印字符。也就是说,国标码并不是完全兼容ASCII码的。
4.
为了解决这个弊端,考虑到ASCII码只使用了一个字节中的低7位,最高位(即首位)为0,于是决定将国标码每个字节的最高位设为1(国标码的两个字节中的最高位都恒为0,即国标码中的每个字节实际上也只用了一个字节中的低7位),这就是GB2312的机内码(即内码),简称GB2312码。
这样一来就彻底区分开了ASCII码和GB2312码。这也是为什么国标码还要加上(80H,80H)才能得到机内码的原因。
5.
看到这里,有人或许又要问了:如果仅仅是为了避免与ASCII编码相冲突,为什么最初不直接将区位码的区码和位码的最高位从0改为1(相当于各自直接加上128),这样不就无需经过国标码多此一举的中间转换了吗?而且还无需后移32,也就不用浪费这部分编码空间。
对此本人也很困惑,在网上搜了很久也没找到答案,因此具体原因不得而知。或许是一开始考虑不周?或许为了未来扩展所需而预留一部分空间?又或许是有其他不得已的原因?有知道的朋友还望能指点迷津。
五、外码(输入码、输入法编码)
1.
外码也叫输入码、输入法编码,是用来将汉字输入到计算机中的一组键盘符号,是作为汉字输入用的编码。
英文字母只有26个,可以把所有的字符都放到键盘上,而使用这种办法把所有的汉字都放到键盘上,是不可能的。所以汉字系统需要有自己的输入码体系,使汉字与键盘能建立对应关系。
2.
目前常用的外码分为以下几类:
1)数字编码,比如区位码;
2)拼音编码,比如全拼、双拼、自然码等;
3)字形编码,比如五笔、表形码、郑码等。
六、字形码(字型码、字模码、输出码)
1.
字形码,又称为字型码、字模码、输出码,属于点阵代码的一种。
为了将汉字在显示器或打印机上输出,把汉字按图形符号设计成点阵图,就得到了相应的点阵代码(字形码)。
也就是用0、1表示汉字的字形,将汉字放入n行*n列的正方形(点阵)内,该正方形共有n^2个小方格,每个小方格用一位二进制表示,凡是笔划经过的方格值为1,未经过的值为0。
2.
显示一个汉字一般采用16×16点阵或24×24点阵或48×48点阵。已知汉字点阵的大小,可以计算出存储一个汉字所需占用的字节空间。
比如,用16×16点阵表示一个汉字,就是将每个汉字用16行,每行16个点表示,一个点需要1位二进制代码,16个点需用16位二进制代码(即2个字节),共16行,所以需要16行×2字节/行=32字节,即16×16点阵表示一个汉字,字形码需用32字节。
因此,字节数=点阵行数×(点阵列数/8)。
3.
显然,字形码所表示的字符,相对于抽象字符表ACR里的“抽象”字符,可称之为“具体”字符,因为具有了“具体”的外形。

为了将汉字的字形显示输出或打印输出,汉字信息处理系统还需要配有汉字字形库,也称字模库,简称字库,它集中了汉字的字形信息。
字库按输出方式可分为显示字库和打印字库。用于显示输出的字库叫显示字库,工作时需调入内存。用于打印输出的字库叫打印字库,工作时无需调入内存。
字库按存储方式也可分为软字库和硬字库。软字库以文件的形式存放在硬盘上,现多用这种方式。硬字库则将字库固化在一个单独的存储芯片中,再和其它必要的器件组成接口卡,插接在计算机上,通常称为汉卡。这种方式现已淘汰。
七、小结

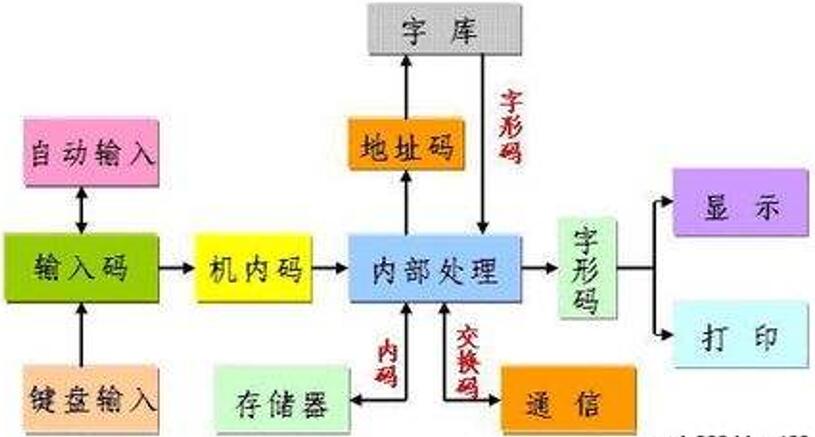
计算机通过键盘输入的外码(重码时还需附加选择编号)对应于汉字内码,将汉字外码转换(即映射)为汉字内码,以实现输入汉字的目的;通过汉字内码在字模库(即字库)中找出汉字的字形码,将汉字内码转换(即映射)为汉字字形码,以实现显示输出和打印输出汉字的目的。
(笨笨阿林原创文章,转载请注明出处)
【预告:下一篇将重点剖析非常容易令人困惑的所谓ANSI编码与代码页(Code Page),敬请关注!】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号