HashSet类
Set接口的特点是无序和不重复
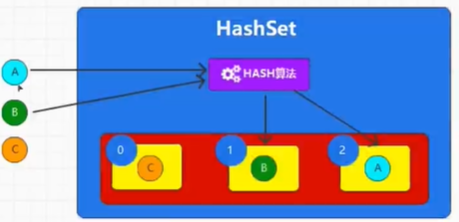
上图就是无序的体现,HashSet底层数据结构是数组+链表,虽然数组有索引,但是数据并不是按索引来存放
而是先通过Hash算法来给出各个数据存放的位置
如图,数据A通过Hash算法得到存放的位置是索引2,B是索引1,C是索引0
所以HashSe里的数据是无序的
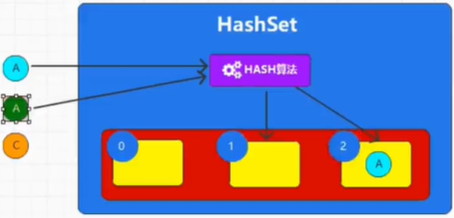
上图是不重复的体现,Hash算法对相同的数据得出的结果是相同的
假设Hash算法得到A的位置是索引2,那么第二个数据还是A时,算法得到的结果还是索引2。HashSet会丢弃到重复的A
添加
package Set;
import java.util.HashSet;
public class hashset {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");
System.out.println(set);//[lisi, zhangsan, wangwu]
/*Hash算法是根据数据的值来得到存放位置的,且不会发生改变
set.add("wangwu");
set.add("zhangsan");
set.add("lisi");
System.out.println(set);//[lisi, zhangsan, wangwu]
*/
}
}
addAll
package Set;
import java.util.ArrayList;
import java.util.HashSet;
public class hashset {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");
ArrayList list = new ArrayList();
list.add("a");
list.add("b");
list.add("c");
set.addAll(list);
System.out.println(set);//[lisi, a, b, c, zhangsan, wangwu]
}
}
删除
HashSet不能直接修改,只能先删除再添加来间接修改
package Set;
import java.util.HashSet;
public class hashset {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");
System.out.println(set);//[lisi, zhangsan, wangwu]
set.remove("zhangsan");
System.out.println(set);//[lisi, wangwu]
}
}
查询
HashSet也不能单个查询,因为查不到索引。只能遍历
package Set;
import java.util.HashSet;
public class hashset {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");
System.out.println(set);//[lisi, zhangsan, wangwu]
for (Object obj:set) {
System.out.println(obj);
}
}
}
常用方法
toArray
package Set;
import java.util.Arrays;
import java.util.HashSet;
public class hashset {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("zhangsan");
set.add("lisi");
set.add("wangwu");
System.out.println(set);//[lisi, zhangsan, wangwu]
Object[] objects = set.toArray();
System.out.println(Arrays.toString(objects));//[lisi, zhangsan, wangwu]
}
}
其他
//还有一些之前List里也常用的方法
set.isEmpty();
set.contains("lisi");
set.clear();
set.size();
set.clone();//...等等一些方法
数据重复问题
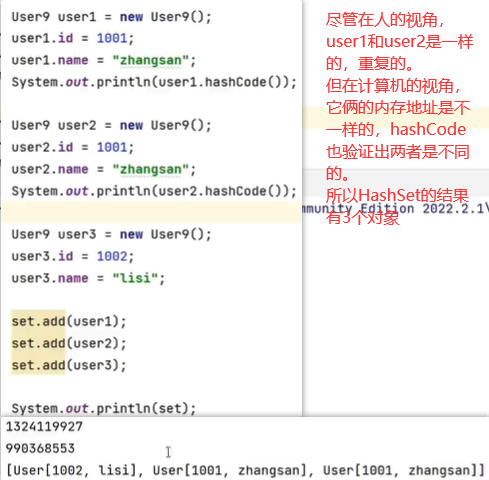

首先再讲下Hash算法,它是通过数据的hashCode来算出存放位置的。
C通过Hash算法根据C的HashCode得出它的位置是索引1,且索引1里没有数据,所以C被存放到索引1
D通过算法是有可能也得到索引1的位置的,假设D的位置也是索引1,此时已经有C了。再判断数据C、D是否相同,相同则抛弃D,不同则用链表把C、D链接起来
要想HashSet和我们的认知一致(id和name都相同就认为两个数据是一样的),就要重写hashCode和equals方法
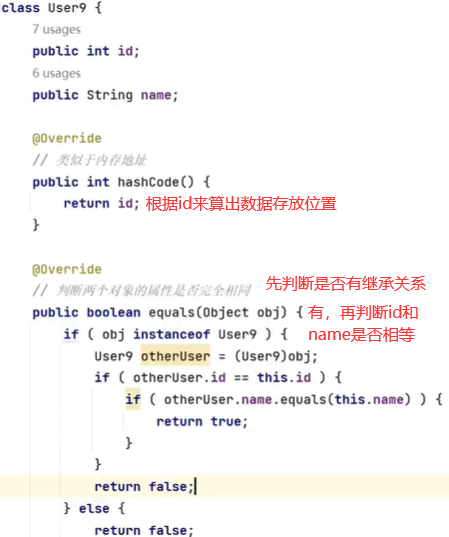
此时再运行,结果就只有两个对象了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号