影像分类(一):用Arcgis进行影像分类
一、简介
影像分类的方法总体上可以分为两大类:监督分类和非监督分类。
Arcgis中这两大类方法都有提供。
分类流程一般包括两步:1.影像分类 2.评价分类结果
二、Arcgis影像分类示例
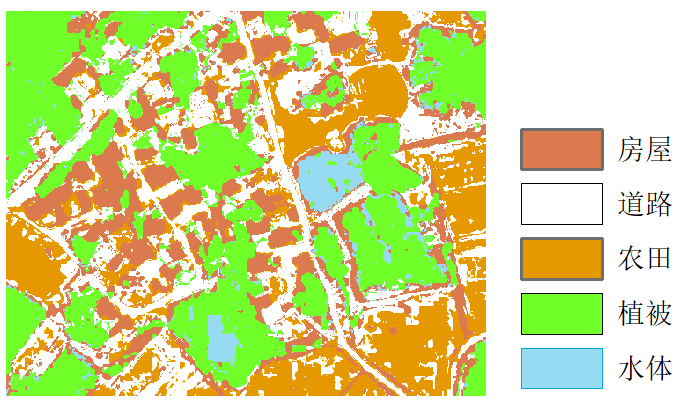
这里,用最大似然法(监督分类)将下图影像中的地物分为五类:房屋、道路、农田、水体、植被。

用Arcgis进行影像分类,主要用到“影像分类”工具,如下图所示(在Arcgis软件界面上方空白处右键,即可打开工具栏)。
1.创建训练样本
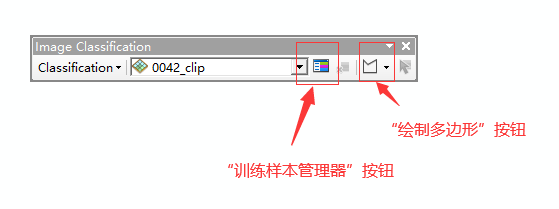
在“影像分类“工具中,利用“训练样本管理器工具”和“绘制多边形工具”创建样本。
创建好的样本如下图所示。
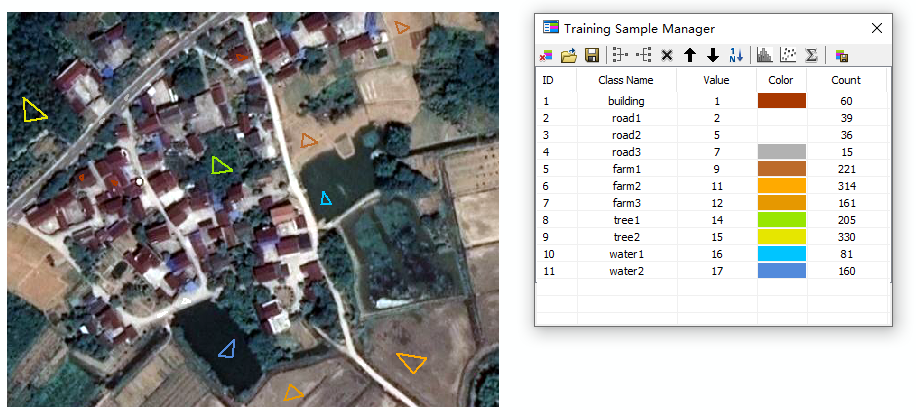
创建样本时,需要注意:
(1)同一类地物的样本不宜选择过多,选择过多的样本反而会导致分类精度下降;
(2)尽量选择特征明显的区域作为样本,样本区域内像元的光谱特征尽量单一;
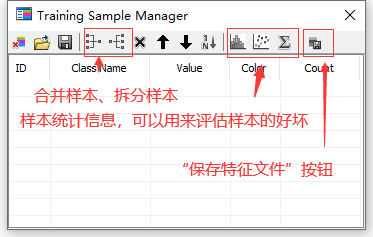
创建样本的过程中,可以根据样本统计信息评估所选样本的好坏。
样本创建好后,点击“保存特征文件按钮”保存为特征文件。
2.分类
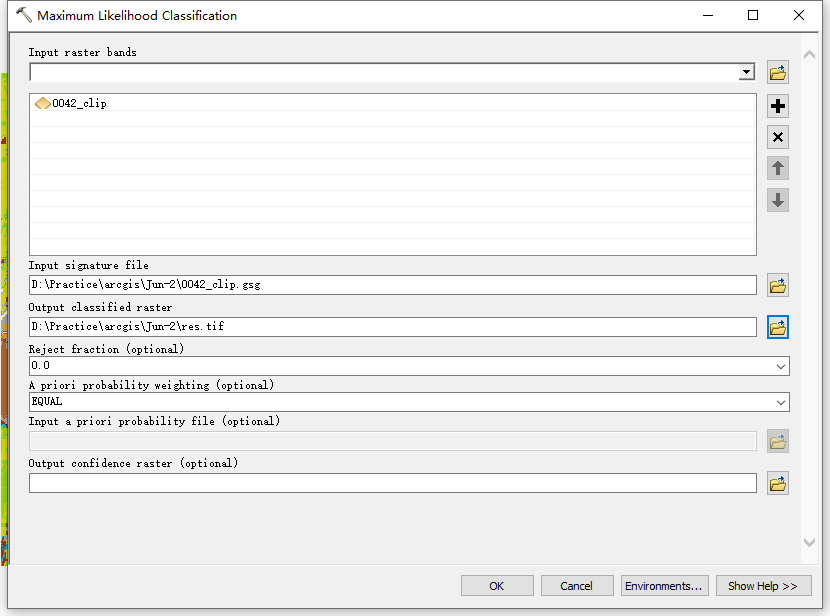
分类结果如下图所示。

3.重分类
由于存在“同物异谱”现象,不同区域的同一类地物之间的光谱差异依然较大,因此在创建分类样本的时候,使用了“子类型”。
如上图中,道路类型下又细分为road1、road2、road3三种子类型。因为高速公路与村级公路的光谱差异较大,所以将高速公路分为一类(road3),村级公路分为又一类(road1、road2)。
因此,在上述分类结果的基础上,通过重分类,将“子类型”合并为一类。如:road1、road2、road3合并为road。

根据“训练样本管理器”中的类型,为同一类地物赋予相同的“新值”(New values)。
重分类结果如下图所示。

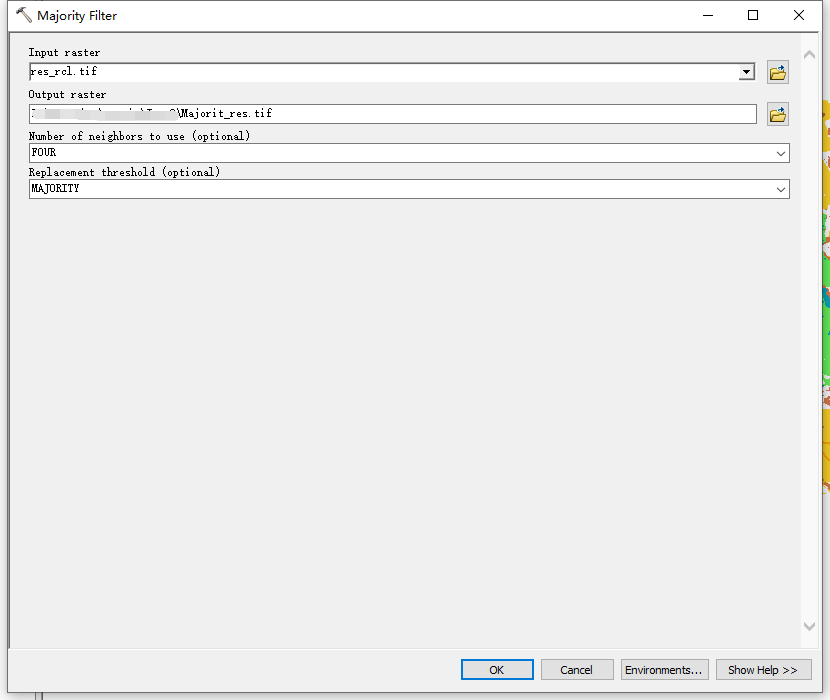
4.众数滤波
重分类结果中存在许多孤立像素点(噪点)。可以通过众数滤波工具来减少孤立像素点。
众数滤波的功能可以简单概括为:用一个像元周围四邻域或八邻域中像元值的众数来替换这个像元的值。
经过众数滤波处理后的分类结果如下。可以看到,零碎分布的像素点依然存在,但相比处理之前有所减少。
至此,分类完毕。
三、评价分类结果
分类完成后,需要评价分类结果。
Arcgis为我们提供的评价方法是:在影像范围内创建一定数量的随机点,设置每一个点在分类后的影像中所属的类型,以及在原始的影像中真实属于的类型。然后,统计每一类中正确分类的点的数量和错误分类的点的数量,建立混淆矩阵,对分类结果进行评价。
评价分类结果的流程为:创建精度评估点 -> 更新精度评估点 -> 生成混淆矩阵。
1.创建精度评估点

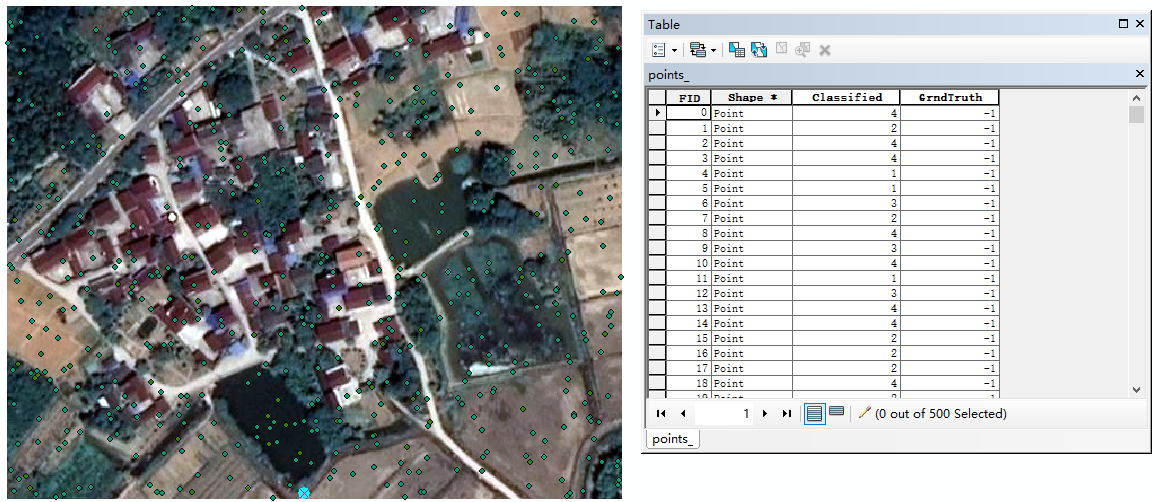
创建精度评估点是指在影像范围内随机生成一点数量(Number of Random Points)的点。这些点有两个特殊的属性(Classified、GrndTruth)。其中,Classified属性表示点在分类后的影响中所属的类型;GrndTruth属性表示点在原始影像中所属的类型。
创建评估点时,需要注意:如果输入(Input Raster or Feature Class)的是分类后的影像,则目标字段(Target Field)应选择“Classified”;如果输入的是代表原始影像的文件,则目标字段应选择“GrndTruth”。
用“创建精度平度点工具”生成评估点时,Arcgis会自动为目标字段赋值。
这里我们选择分类后的影像和"Classified"字段。评估点创建好后,打开其属性表,可以看到Classified字段已经有值了。
另外,也可以手动创建点要素数据集,并为这两个字段赋值。但自己手动创建点,随机性肯定比较差,一般会使评价结果偏高。
生成的精度评估点如下图。
2.更新精度评估点
Arcgis中提供了“更新精度评估点”工具。
但这里用不到,因为我们的原始影像中并不存在"类型"。
因此,只能通过“目视解译”的方法,手动为上一步生成的点文件中的每一个点的“GrndTruth”属性赋值。怎么赋值呢?这里举一个例子,如:查看原始影像,发现一个点落在房屋范围内,而房屋类型在分类结果中的编号为1,所以给这个点的GrndTruth属性赋值为1。
3.生成混淆矩阵
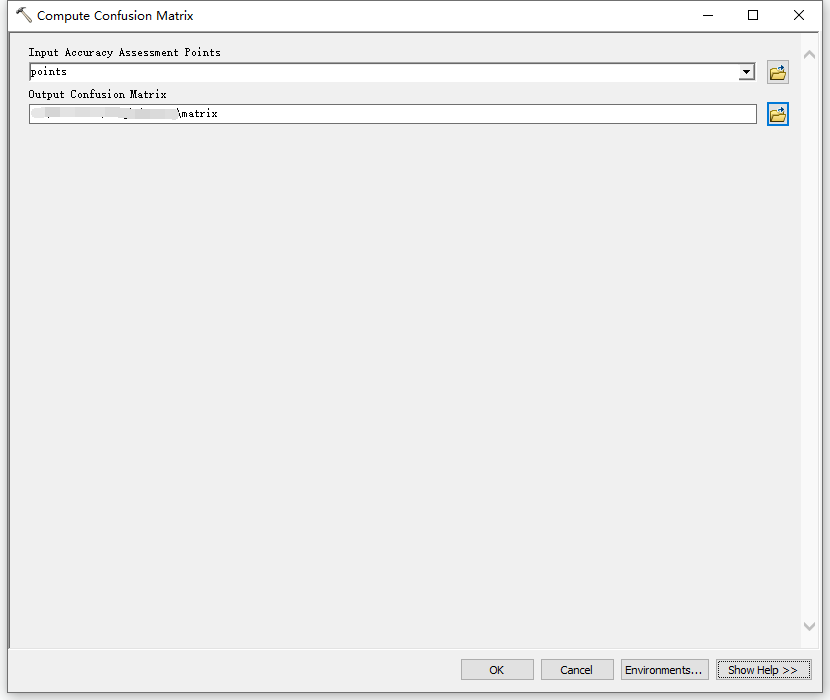
生成的混淆矩阵如下图所示。
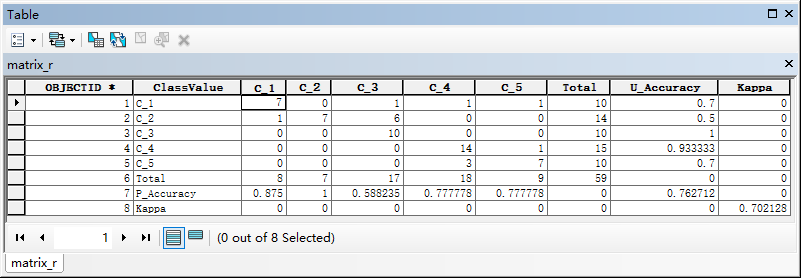
kappa系数、整体分类精度,每一类的制图者精度、使用者精度都已经计算出来了。
通过上图可知,这次分类的整体精度为0.762712,kappa系数为0.702128。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号