PaddlePaddle 飞桨实现GAN生成对抗网络生成MINIST手写数字图像
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear, BatchNorm,Upsample
import numpy as np
import matplotlib.pyplot as plt
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
train_reader = paddle.vision.datasets.MNIST(mode='train')
print("训练集样本数:", len(train_reader))
print("样本形状:", np.array(train_reader[0][0]).shape)
print("标签形状:", np.array(train_reader[0][1]).shape)
训练集样本数: 60000
样本形状: (28, 28)
标签形状: (1,)
# 噪声维度
Z_DIM = 100
BATCH_SIZE = 128
paddle.vision.set_image_backend('cv2')
mnist_generator = paddle.io.DataLoader(paddle.vision.datasets.MNIST(mode='train'),
batch_size=BATCH_SIZE, shuffle=True)
# 生成假图片的reader, 噪声生成,通过由噪声来生成假的图片数据输入
class ZReader(paddle.io.Dataset):
def __init__(self, z_dim):
super(ZReader, self).__init__()
self.z_dim = z_dim
def __getitem__(self, index):
return np.random.normal(0.0, 1.0, (self.z_dim,1,1)).astype('float32')#正态分布,正态分布的均值、标准差、参数
def __len__(self):
return int(1e8) # a large number
z_dataset = ZReader(Z_DIM)
z_generator = paddle.io.DataLoader(z_dataset, batch_size=BATCH_SIZE)
image,label =next(mnist_generator())
print("图像数据形状和对应数据为:", image.shape)
print("图像标签形状和对应数据为:", label.shape)
plt.imshow(image[0].numpy().astype(np.uint8)) # (28,28)
plt.show
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)):
图像数据形状和对应数据为: [128, 28, 28]
图像标签形状和对应数据为: [128, 1]
W0511 14:09:22.929143 892 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0511 14:09:22.933797 892 device_context.cc:372] device: 0, cuDNN Version: 7.6.
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
if isinstance(obj, collections.Iterator):
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
return list(data) if isinstance(data, collections.MappingView) else data
<function matplotlib.pyplot.show(*args, **kw)>
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_min = np.asscalar(a_min.astype(scaled_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_max = np.asscalar(a_max.astype(scaled_dtype))

##测试一下噪声
z_tmp = next(z_generator())
print('一个batch噪声z的形状:', z_tmp[0].shape)
一个batch噪声z的形状: [128, 100, 1, 1]
GAN 网络#
GAN 性能的提升从生成器 G 和判别器 D 进行左右互搏、交替完善的过程得到的。所以其 G 网络和 D 网络的能力应该设计得相近,复杂度也差不多。这个项目中的生成器,采用了两个全链接层接两组上采样和转置卷积层,将输入的噪声 Z 逐渐转化为 1×28×28 的单通道图片输出。
生成器结构:
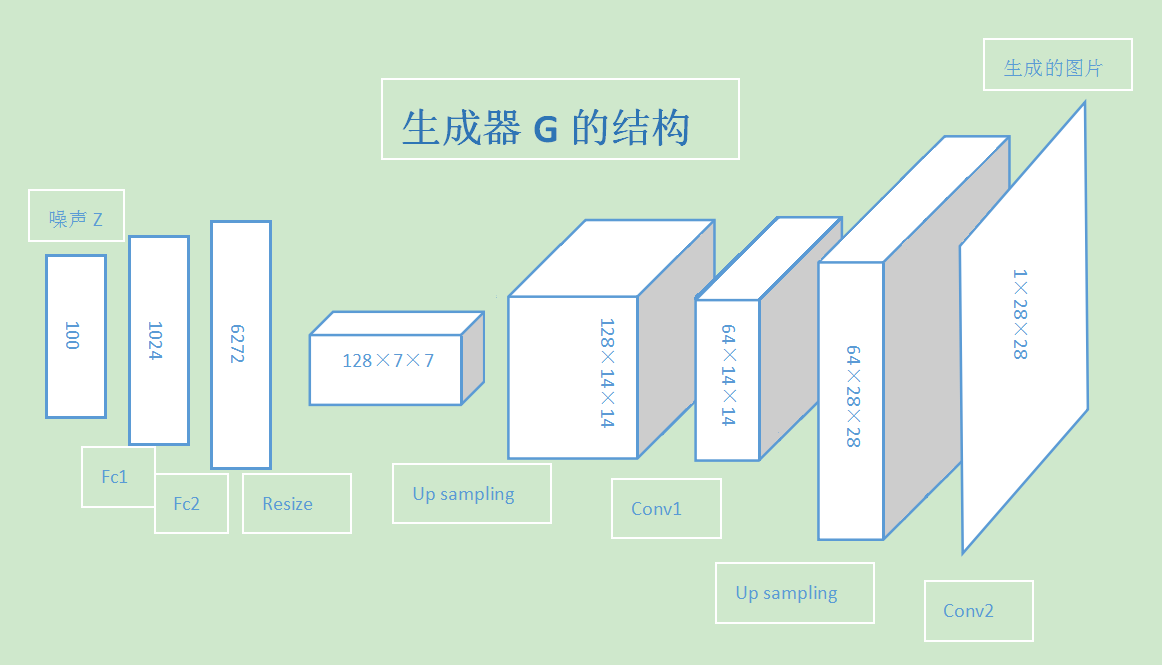
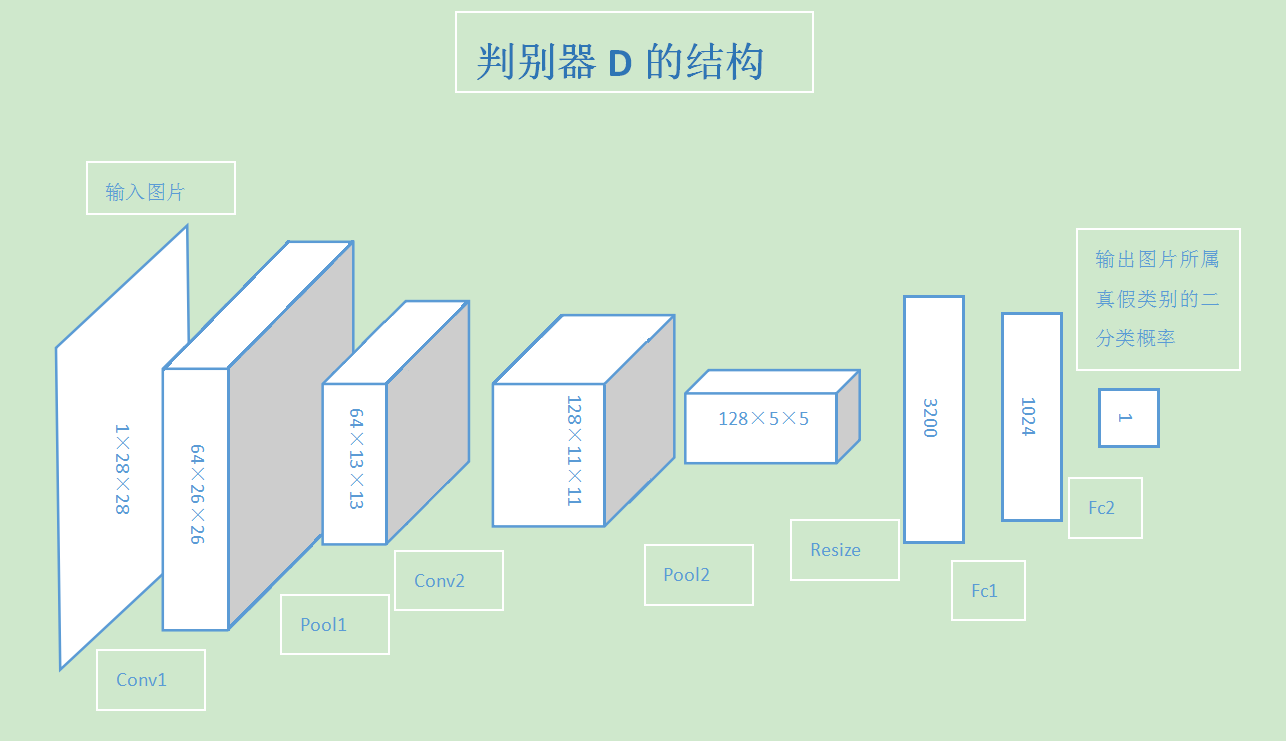
判别器的结构正好相反,先通过两组卷积和池化层将输入的图片转化为越来越小的特征图,再经过两层全链接层,输出图片是真是假的二分类结果。
判别器结构:
import paddle
# 判别器 D
class D(paddle.nn.Layer):
def __init__(self, name_scope):
super(D, self).__init__(name_scope)
name_scope = self.full_name()
#
# My_D的代码
self.conv1 = paddle.fluid.Conv2D(num_channels=1, num_filters=64, filter_size=3)
self.bn1 = paddle.nn.BatchNorm(num_channels=64, act='leaky_relu')
self.pool1 = paddle.fluid.Pool2D(pool_size=2, pool_stride=2)
self.conv2 = paddle.fluid.Conv2D(num_channels=64, num_filters=128, filter_size=3)
self.bn2 = paddle.nn.BatchNorm(num_channels=128, act='leaky_relu')
self.pool2 = paddle.fluid.Pool2D(pool_size=2, pool_stride=2)
self.fc1 = paddle.fluid.Linear(input_dim=128 * 5 * 5, output_dim=1024)
self.bnfc1 = paddle.nn.BatchNorm(num_channels=1024, act='leaky_relu')
self.fc2 = paddle.fluid.Linear(input_dim=1024, output_dim=1)
def forward(self, img):
#
# My_G forward的代码
y = self.conv1(img)
y = self.bn1(y)
y = self.pool1(y)
y = self.conv2(y)
y = self.bn2(y)
y = self.pool2(y)
y = paddle.reshape(x=y, shape=[-1, 128 * 5 * 5])
y = self.fc1(y)
y = self.bnfc1(y)
y = self.fc2(y)
return y
# 生成网络G
class G(paddle.nn.Layer):
def __init__(self, name_scope):
super(G, self).__init__(name_scope)
name_scope = self.full_name()
# 第一组全连接和BN层
self.fc1 = paddle.fluid.Linear(input_dim=100, output_dim=1024)
self.bn1 = paddle.nn.BatchNorm(num_channels=1024, act='tanh')
# 第二组全连接和BN层
self.fc2 = paddle.fluid.Linear(input_dim=1024, output_dim=128 * 7 * 7)
self.bn2 = paddle.nn.BatchNorm(num_channels=128 * 7 * 7, act='tanh')
# 第一组卷积运算(卷积前进行上采样,以扩大特征图)
# 注:此处使用转置卷积的效果似乎不如上采样后直接用卷积,转置卷积生成的图片噪点较多
self.conv1 = paddle.fluid.Conv2D(num_channels=128, num_filters=64, filter_size=5, padding=2)
self.bn3 = paddle.nn.BatchNorm(num_channels=64, act='tanh')
# 第二组卷积运算(卷积前进行上采样,以扩大特征图)
self.conv2 = paddle.fluid.Conv2D(num_channels=64, num_filters=1, filter_size=5, padding=2, act='tanh')
def forward(self, z):
z = paddle.reshape(x=z, shape=[-1, 100])
y = self.fc1(z)
y = self.bn1(y)
y = self.fc2(y)
y = self.bn2(y)
y = paddle.reshape(x=y, shape=[-1, 128, 7, 7])
# 第一组卷积前进行上采样以扩大特征图
y = paddle.fluid.layers.image_resize(y, scale=2)
y = self.conv1(y)
y = self.bn3(y)
# 第二组卷积前进行上采样以扩大特征图
y = paddle.fluid.layers.image_resize(y, scale=2)
y = self.conv2(y)
return y
paddle.Model(G('G')).summary((-1,100))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Linear-1 [[1, 100]] [1, 1024] 103,424
BatchNorm-1 [[1, 1024]] [1, 1024] 4,096
Linear-2 [[1, 1024]] [1, 6272] 6,428,800
BatchNorm-2 [[1, 6272]] [1, 6272] 25,088
Conv2D-1 [[1, 128, 14, 14]] [1, 64, 14, 14] 204,864
BatchNorm-3 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
Conv2D-2 [[1, 64, 28, 28]] [1, 1, 28, 28] 1,601
===========================================================================
Total params: 6,768,129
Trainable params: 6,738,689
Non-trainable params: 29,440
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.31
Params size (MB): 25.82
Estimated Total Size (MB): 26.13
---------------------------------------------------------------------------
{'total_params': 6768129, 'trainable_params': 6738689}
paddle.Model(D('D')).summary((-1,1,28,28))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-3 [[1, 1, 28, 28]] [1, 64, 26, 26] 640
BatchNorm-4 [[1, 64, 26, 26]] [1, 64, 26, 26] 256
Pool2D-1 [[1, 64, 26, 26]] [1, 64, 13, 13] 0
Conv2D-4 [[1, 64, 13, 13]] [1, 128, 11, 11] 73,856
BatchNorm-5 [[1, 128, 11, 11]] [1, 128, 11, 11] 512
Pool2D-2 [[1, 128, 11, 11]] [1, 128, 5, 5] 0
Linear-3 [[1, 3200]] [1, 1024] 3,277,824
BatchNorm-6 [[1, 1024]] [1, 1024] 4,096
Linear-4 [[1, 1024]] [1, 1] 1,025
===========================================================================
Total params: 3,358,209
Trainable params: 3,353,345
Non-trainable params: 4,864
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 1.02
Params size (MB): 12.81
Estimated Total Size (MB): 13.83
---------------------------------------------------------------------------
{'total_params': 3358209, 'trainable_params': 3353345}
z_tmp = next(z_generator())
g_tmp = G('G')
tmp_g = g_tmp(z_tmp[0]).numpy()
print('生成器G生成图片数据的形状:', tmp_g.shape)
plt.imshow(tmp_g[0][0])
plt.show()
d_tmp = D('D')
tmp_d = d_tmp(paddle.to_tensor(tmp_g)).numpy()
print('判别器D判别生成的图片的概率数据形状:', tmp_d.shape)
print(max(tmp_d))
生成器G生成图片数据的形状: (128, 1, 28, 28)
判别器D判别生成的图片的概率数据形状: (128, 1)
[3.0552034]

import matplotlib.pyplot as plt
%matplotlib inline
def show_image_grid(images, batch_size=128, pass_id=None):
fig = plt.figure(figsize=(8, batch_size/32))
gs = plt.GridSpec(int(batch_size/16), 16)
gs.update(wspace=0.05, hspace=0.05)
for i, image in enumerate(images):
ax = plt.subplot(gs[i])
plt.axis('off')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_aspect('equal')
plt.imshow(image[0], cmap='Greys_r')
plt.show()
show_image_grid(tmp_g, BATCH_SIZE)

网络训练#
网络的训练优化目标就是如下公式:
公式出自 Goodfellow 在 2014 年发表的论文Generative Adversarial Nets。
这里简单介绍下公式的含义和如何应用到代码中。上式中等号左边的部分:
等式的右边其实就是将等式左边的交叉商损失公式展开,并写成概率分布的期望形式。详细的推导请参见原论文《Generative Adversarial Nets》。
下面是训练模型的代码,有详细的注释。大致过程是:先用真图片训练一次判别器 d 的参数,再用生成器 g 生成的假图片训练一次判别器 d 的参数,最后用判别器 d 判断生成器 g 生成的假图片的概率值更新一次生成器 g 的参数,即每轮训练先训练两次判别器 d,再训练一次生成器 g,使得判别器 d 的能力始终稍稍高于生成器 g 一些。
for i, real_image in enumerate(mnist_generator()):
print(real_image[0].shape, len(real_image[0]))
break
[128, 28, 28] 128
训练代码#
import paddle.nn.functional as F
d = D('D')
d.train()
g = G('G')
g.train()
# 创建优化方法
real_d_optimizer = paddle.optimizer.Adam(learning_rate=1e-4, parameters=d.parameters())
fake_d_optimizer = paddle.optimizer.Adam(learning_rate=1e-4, parameters=d.parameters())
g_optimizer = paddle.optimizer.Adam(learning_rate=5e-4, parameters=g.parameters())
iteration_num = 0
epoch_num = 5
for epoch in range(epoch_num):
for i, (real_image, label) in enumerate(mnist_generator()):
# 丢弃不满整个batch_size的数据
if(len(real_image) != BATCH_SIZE):
continue
iteration_num += 1
'''
判别器d通过最小化输入真实图片时判别器d的输出与真值标签ones的交叉熵损失,来优化判别器的参数,
以增加判别器d识别真实图片real_image为真值标签ones的概率。
'''
# 将MNIST数据集里的图片读入real_image,将真值标签ones用数字1初始化
real_image = real_image.unsqueeze(1)
real_image = paddle.to_tensor(real_image)
ones = paddle.to_tensor(np.ones([len(real_image), 1]).astype('float32'))
# 计算判别器d判断真实图片的概率
p_real = d(real_image)
# 计算判别真图片为真的损失
real_cost = F.binary_cross_entropy_with_logits(p_real, ones)
real_avg_cost = paddle.mean(real_cost)
# 反向传播更新判别器d的参数
real_avg_cost.backward()
real_d_optimizer.minimize(real_avg_cost)
d.clear_gradients()
'''
判别器d通过最小化输入生成器g生成的假图片g(z)时判别器的输出与假值标签zeros的交叉熵损失,
来优化判别器d的参数,以增加判别器d识别生成器g生成的假图片g(z)为假值标签zeros的概率。
'''
# 创建高斯分布的噪声z,将假值标签zeros初始化为0
z = next(z_generator())
zeros = paddle.to_tensor(np.zeros([len(real_image), 1]).astype('float32'))
# 判别器d判断生成器g生成的假图片的概率
p_fake = d(g(z[0]))
# 计算判别生成器g生成的假图片为假的损失
fake_cost = F.binary_cross_entropy_with_logits(p_fake, zeros)
fake_avg_cost = paddle.mean(fake_cost)
# 反向传播更新判别器d的参数
fake_avg_cost.backward()
fake_d_optimizer.minimize(fake_avg_cost)
d.clear_gradients()
'''
生成器g通过最小化判别器d判别生成器生成的假图片g(z)为真的概率d(fake)与真值标签ones的交叉熵损失,
来优化生成器g的参数,以增加生成器g使判别器d判别其生成的假图片g(z)为真值标签ones的概率。
'''
# 生成器用输入的高斯噪声z生成假图片
fake = g(z[0])
# 计算判别器d判断生成器g生成的假图片的概率
p_confused = d(fake)
# 使用判别器d判断生成器g生成的假图片的概率与真值ones的交叉熵计算损失
g_cost = paddle.fluid.layers.sigmoid_cross_entropy_with_logits(p_confused, ones)
g_avg_cost = paddle.mean(x=g_cost)
# 反向传播更新生成器g的参数
g_avg_cost.backward()
g_optimizer.minimize(g_avg_cost)
g.clear_gradients()
# 打印输出
if(iteration_num % 100 == 0):
print('epoch =', epoch, ', batch =', i, ', real_d_loss =', real_avg_cost.numpy(),
', fake_d_loss =', fake_avg_cost.numpy(), 'g_loss =', g_avg_cost.numpy())
show_image_grid(fake.numpy(), BATCH_SIZE, epoch)
# 存储模型
paddle.save(g.state_dict(), './output/'+'g')
paddle.save(d.state_dict(), './output/'+'d_o_r')
paddle.save(d.state_dict(), './output/'+'d_o_f')
epoch = 0 , batch = 99 , real_d_loss = [0.63881606] , fake_d_loss = [0.43077955] g_loss = [1.1314435]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_min = np.asscalar(a_min.astype(scaled_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_max = np.asscalar(a_max.astype(scaled_dtype))

epoch = 0 , batch = 199 , real_d_loss = [0.4727745] , fake_d_loss = [0.40940467] g_loss = [1.1723493]

epoch = 0 , batch = 299 , real_d_loss = [0.3923043] , fake_d_loss = [0.38755333] g_loss = [1.2083172]

epoch = 0 , batch = 399 , real_d_loss = [0.3553782] , fake_d_loss = [0.3865837] g_loss = [1.2023909]

epoch = 1 , batch = 31 , real_d_loss = [0.30362654] , fake_d_loss = [0.3808377] g_loss = [1.22538]

epoch = 1 , batch = 131 , real_d_loss = [0.3126711] , fake_d_loss = [0.38687515] g_loss = [1.2130171]

epoch = 1 , batch = 231 , real_d_loss = [0.273176] , fake_d_loss = [0.37318167] g_loss = [1.2494049]

epoch = 1 , batch = 331 , real_d_loss = [0.40979803] , fake_d_loss = [0.4624972] g_loss = [1.1285127]

epoch = 1 , batch = 431 , real_d_loss = [0.5482184] , fake_d_loss = [0.4858724] g_loss = [1.1077986]

epoch = 2 , batch = 63 , real_d_loss = [0.5916477] , fake_d_loss = [0.5695666] g_loss = [0.9861771]

epoch = 2 , batch = 163 , real_d_loss = [0.6595901] , fake_d_loss = [0.54358363] g_loss = [1.0098863]

epoch = 2 , batch = 263 , real_d_loss = [0.7349342] , fake_d_loss = [0.5123524] g_loss = [1.0610704]

epoch = 2 , batch = 363 , real_d_loss = [0.88330436] , fake_d_loss = [0.51227736] g_loss = [1.0595765]

epoch = 2 , batch = 463 , real_d_loss = [0.83836365] , fake_d_loss = [0.53332305] g_loss = [0.99540174]

epoch = 3 , batch = 95 , real_d_loss = [0.86019707] , fake_d_loss = [0.53724575] g_loss = [0.9913846]

epoch = 3 , batch = 195 , real_d_loss = [0.8524647] , fake_d_loss = [0.5335064] g_loss = [1.0278957]

epoch = 3 , batch = 295 , real_d_loss = [0.90599334] , fake_d_loss = [0.5457525] g_loss = [0.9990233]

epoch = 3 , batch = 395 , real_d_loss = [0.7981782] , fake_d_loss = [0.539215] g_loss = [0.98800594]

epoch = 4 , batch = 27 , real_d_loss = [0.8963315] , fake_d_loss = [0.5651827] g_loss = [0.94507515]

epoch = 4 , batch = 127 , real_d_loss = [0.8121051] , fake_d_loss = [0.61096513] g_loss = [0.8886054]

epoch = 4 , batch = 227 , real_d_loss = [0.7931969] , fake_d_loss = [0.5683154] g_loss = [0.9184775]

epoch = 4 , batch = 327 , real_d_loss = [0.8052078] , fake_d_loss = [0.55665344] g_loss = [0.947585]

epoch = 4 , batch = 427 , real_d_loss = [0.9077438] , fake_d_loss = [0.52213967] g_loss = [0.9807905]

生成测试#
z = next(z_generator())
fake = g(z[0])
show_image_grid(fake.numpy(), 128, 0)

作者:龙琰
出处:https://www.cnblogs.com/bellongyan/p/gan_generate_pics.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战