
掰碎了讲中文编码
电脑用0和1存储数据,而存储的数据主要有两种:数字和字符(还有运算符什么的暂时不讨论),数字存储的方法比较简单,没什么问题,这里要说的是如何存储字符。
1编码方式的大历史
1.1 ASCII
最早对于发明计算机的美国人来说,字符只有大小写的字母,于是他们使用一种简单的编码方式——ASCII,一个字母对应一个8位二进制码(ASCII码),或者说数字0-255,或者说8比特,或者说1个字节。存储的内容其实就是这组8位01码,当使用ASCII编码方式的软件被告知用字符的方式显示这组8位01码时,它便显示成字母的样子,这其实就跟用01码存储的数字一样,当你告诉软件用数字的方式显示这组01码时候,它便显示数字。
1.2 GBK
但是显然对于中国人来说,这个256个空间是放不下所有的中文字符的,于是中国人采用另一个针对中文的编码方式——GBK(最早是GB2312,后来扩展为GBK),用两个字节的01对应1个中文字符,也就是说,当使用GBK编码方式的软件被告知用字符的方式显示这组01码时,它便从GBK的表中读取对应中文字符并显示出来(后文会对这个过程详细讨论)。
1.3 Unicode编码
但是全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。因此,Unicode编码应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode,这里要说一下,windows7中文系统的默认编码方式是GBK(起码txt中的字符是GBK编码,可能系统内核是Unicode,或者说只有输入输出窗口是GBK,暂时不管)。(另外提一下简单的编码转换,用ASCII编码的字符显然是可以转成Unicode编码,反过来则不可以,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001)。也就是说,当使用Unicode编码方式的软件被告知用字符的方式显示这组01码时,它便从Unicode表中读取对应中文字符并显示出来。
1.4 UTF-8编码
但是新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节(其实比GBK占用内存更多),只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符(对吧,英文),用UTF-8编码就能节省空间。UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。也就是说,当使用UTF-8编码方式的软件被告知用字符的方式显示这组01码时,它便从UTF-8表中读取这组01码对应中文字符并显示出来。
这里要强调的是,为了兼容所有语言,并给大部分是英文的程序提供便利,在程序员世界,UTF-8码是通用编码方式,文件一般也用这种形式存储,所以Linux系统使用的就是UTF-8,但是可惜的是,我们现在使用的windows7使用时GBK的编码方式,这就注定编程之路会走得比别人弯。
2编码、解码和转码
2.1 编码解码
上面的用词都是编码,编码就是1建立字符和01码的一一对应关系2把字符存储为这个01码。其中也提到了解码,解码就是把这个01码再变成字符(下文会详解这个在过程中都发生了些什么事)。
所有的编码、解码和转码过程都是通过软件实现的,而编码的对应关系也是软件自己带有的,所以带了哪种,默认又是哪种,是各不一样的,下文会用在win7上写python程序举例。
2.2 不同编码间的转码
对于英文字母和数字的字符来说,他们可以直接用ASCII、GBK、Unicode、UTF-8编码,而这些字符的ASCII编码与UTF-8编码一样,所以对这些字符来说,存在着三种编码之间的转换,哪些转换是可以进行的呢?用图片表示简单方便,左图左边四个双向箭头表示编码和解码,右边两个双向箭头表示Unicode分别可以与GBK和UTF-8双向转码,而GBK和和UTF-8之间不可进行转码。
对于四条转码途径用右图表示,Python代码如图所示,其中也把UTF-8码和GBK码到Unicode的过程叫做解码。
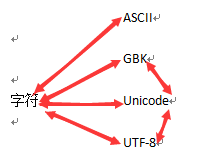

而对于中文字符来说,他们可以直接用GBK、Unicode、UTF-8编码,不能用ASCII编码,过程除了左图第一个双向箭头,其余的跟上图完全一样。
3在Win7上写Python程序
这篇文章的缘起就是写了个用wxpython库的Python程序,所以以下的内容就是详解这个过程中遇到的一些问题。
3.1 Python对编码的支持特性
因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的,直接用 ’…’ 来声明。Python在后来添加了对Unicode的支持,用Unicode编码的字符串用u'...' 声明。(而普通的解码输出直接用print语句)
Python中实际上有两种字符串,分别是str类型和unicode类型,这两者都是basestring的派生类。str类型的编码方式与源码文件完全一致(py文件本身也必须被编码),默认情况下便是标准的ASCII编码,你可以通过在第一行写此语句来更改源码文件编码方式:#coding: UTF-8/GBK(此次两种方式只可写一种,而且不可设置为Unicode,而ASCII不用写,另外值得一提的是这个语句为了尊重其他语言的习惯,被设置成正则表达式识别,所以你可以看到这句话很多其他的写法),而Unicode类型采用的是自然是Unicode编码。于是Python通过这样的方式对四种编码方式提供了支持。
另外因为py源文件默认是用ASCII编码保存的,如果其中加入了中文注释或是让变量存了中文字符,就肯定无法保存,所以一般情况下,你都会在第一行更改源文件编码方式,最好是用UTF-8编码。
3.2 在Win7上写Python程序时编码和解码过程
下面详细介绍不同的编码和解码过程,编码和解码发生在广义的输入和输出情况下。下面输入介绍四种方式,第一种是直接写进代码,第二种是从控制台输入窗口(标准输入),第三种是从win7的TXT文档中读取数据(从存储器中读取),第四种是从现在我用wxpython做的窗口界面的文本框。输出介绍三种方式,第一种是从控制台输出窗口(标准输出),第二种是写入win7的TXT文档(把数据写入存储器),第三种是从现在我用wxpython做的窗口界面的文本框。
3.2.1 代码输入、控制台输入窗口输入(标准输入)、控制台输出(标准输出)
(1)代码输入
直接写进代码的时候是这样的,我们先创建一个变量,然后定义变量的数据类型(方便在内存中划出空间存储变量数据),最后把相应的字符串赋给这个变量(当然在程序中这三步是一次完成的),如S = ‘abc’(Python中是动态类型,所以不事先定义变量类型,全靠这对引号来声明Python S是str类型,这个声明告诉要赋给变量S的是以源码编码方式(前面说了默认是ASCII)编码的字符串)。于是这个语句让Python做了这么几个事(编码过程):
1查询到现在源码的编码方式
2按现在源码的编码方式在内存中开辟对应str类型大小的空间;把字符abc用源码的编码方式编码成01的字符
3把编好的01码放入开辟的空间中
4把变量S的指针指向这个空间的地址
(2)控制台输入窗口输入(标准输入)
这里用最常见的raw_Input()内建函数来实现标准输入,这个函数读取你在控制台输入的所有字符,并当做str类型赋给指定的变量,也就是说以源码编码方式编码。代码如下:
S = raw_input(‘The words what will show to you’)
在执行这行代码时,控制台输入窗口便会提示你输入字符,在你输入完字符abc并回车之后,你输入的字符便赋给了变量S,之后发生的事情如同在执行 S=’abc’ 一样。
(3)控制台输出(标准输出)
当从控制台输出窗口输出的时候,也就是接到指示print S的时候它做这么几个事(解码过程):
1定位S指向的地址;查询到S是str类型
2查询到现在源码的编码方式
3取出内存中开辟对应str类型大小的空间中的01码
4按照现在源码的编码方式对01码进行解码,也就是从编码表中找出对应的字符
5把这个字符显示在输出窗口即:abc
(4)
在上面这三个过程容易出现这么几个错误:
1用ASCII编码方式对中文字符编码,这显然会失败,ASCII做不到
2用UTF-8解码方式对用GBK编码了的01码进行解码,显然会显示出乱码(由于对应的类型空间都会取错,这可能就会读取到不该读取的内容,有些游戏BUG就是类似情况产生的)
而在平时我们经常会在没有声明源码文件用UTF-8编码时进行中文注释,在编译的时候就会发生第1个错误,编译之前要对整个程序编码保存,于是便出错了,同样这个时候给变量赋予中文字符串时也会出错。
而当在第一行声明源码文件用UTF-8编码之后,用中文写注释便没有问题了,另外如果给变量赋予中文字符串也没有问题(UTF-8编码),同时打印该变量也没有问题(UTF-8解码),但是这个时候如果你从外部文件中读取了用GBK编码的字符进入变量后,再打印,虽然不会报错,但是输出会直接出现乱码,如果你想要显示正确,就需要进行转码。
3.2.2 从win7的TXT文档中读取数据(从存储器中读取)、写入win7的TXT文档(把数据写入存储器)
(1)从win7的TXT文档中读取数据(从存储器中读取)
在说明编码过程之前先介绍一下在Python中简单的文件IO操作,我们知道,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符,一般给地址和名字),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象(写文件)。对应代码如下(为了放在一行显示,用中文分号隔开):
test1hand = open('test1.txt',’r’);test1 = test1hand.read();test1hand.close()
第一句先用open()函数打开同一目录下的test1.txt文件并且返回这个文件对象的接口或者叫句柄(就是使用权限,这里用了参数r便是获得了读的权限)赋给变量test1hand。
第二句通过这个句柄的.read()方法,一次读取文件的全部内容,注意,读取的文件内容为01码(这里多说一句,本来对于读取01码使用的打开方式是’rb’,但是对于类UNIX系统来说,文本文件本身就是二进制文件,这个b是可有可无的,但是windows并不是类unix系统,奇怪的是这里也并不需要加上b),这个01码是用什么编码方式产生的是由文件系统本身决定的,读取的只是01码,然后把所有的01码返回,在这里是赋给变量test1,再注意,此时也是str类型赋给它的,也就是说test1的变量类型是str,也就是说系统认为这些01码是以源码编码方式编码而成的,而假如文件本身是有GBK编码的,但是源码编码方式是UTF-8,这就出现了一个错误,当然这个并不会报错,继续注意,在解码的时候,仍旧不会报错,但是你会看到出现了错误,也就是如果你直接print解码,它便会按照系统认为的编码方式来解码,于是它输出的字符便会出现乱码,如果要正确显示,就需要进行转码。(注意:一个.read()方法会把文件内容独占,如果在一次打开和关闭文件之间多次使用这个方法,后面的方法读取到的是空文件,返回的字符是 ‘ ‘)
第三句是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的。
所以这个过程没有发生任何编码或者解码,完全是对01码的操作。
而读文件方法除了.read()常用的还有.readline()和.readlines(),甚至还有专用的linecache库,下面再讲一下.readlines()方法,其他的暂时不讲。
.readlines()方法其实跟.read()方法差不多,区别只是它返回的01码是按换行符分成一段段,然后组成一个str列表返回,也就是分行读取,对列表中的每一个字符串来说,情况跟上面一样。
(2)写入win7的TXT文档(把数据写入存储器)
把数据写入txt文档的过程跟读取差不多,代码如下(为了放在一行显示,用中文分号隔开):
test1hand = open('test1.txt',’w’); test1hand.write(‘…’/valuename);test1hand.close()
这个过程是一个编码过程或者不发生任何解码编码完全01码操作过程,如果test1hand.write(‘…’/valuename)中是‘…’,那么会先把‘…’内容按照源码编码方式编码,然后把生成的01码写入文件,如果其中直接是变量名,那么它会直接把变量指向的对应01码写入文件。
这里有个小错误不知道为什么,因为理论上.write()方法是直接把01码写入文件,然后文本文件被打开时是用操作系统的默认解码方式对01码进行解码显示,所以理论上对于我这个win7系统,每次打开文本文件就是它对01码进行GBK解码并显示,如果01码是用GBK编码的话,就可以正确显示字符,如果01码是用UTF-8或者Unicode编码的话,就会直接显示乱码。这个理论对于GBK编码和UTF-8编码都没错,但是对于Unicode编码,在写入的时候就直接报错:UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)。
3.2.3从wxpython生成的简单窗口界面中的文本框
向wxpython生成的简单窗口界面中的文本框输出,和把文本框内容当做输入取得文本框数据,代码示例如下:
文本框名.SetValue(字符串/字符串变量名)
字符串变量名 = 文本框名.GetValue()
第一句是把右边括号中的数据传输到左边文本框中,文本框解码显示,第二句是把右边文本框中的数据传输进右边字符串变量中,存储起来。
这个过程其实并不是特别清楚,因为这有好几个过程,一个SetValue过程,一个文本框解码过程,一个GetValue过程,经过测试,已知的情况有这么几种,并对过程进行猜测:
(1)GBK编码的数据经过SetValue过程进入文本框,文本框能解码并正确显示,GetValue过程获取文本框内容返回Unicode编码的数据。
过程猜测:GBK编码的数据经过SetValue过程进入文本框,文本框进行GBK解码并显示,GetValue过程获取文本框字符并进行Unicode编码并返回。
(2)Unicode编码的数据经过SetValue过程进入文本框,文本框能解码并正确显示,GetValue过程获取文本框内容返回Unicode编码的数据。
过程猜测:Unicode编码的数据经过SetValue过程进入文本框,文本框进行Unicode解码并显示,GetValue过程获取文本框字符并进行Unicode编码并返回。
(3)UTF-8编码的数据经过SetValue过程进入文本框,文本框不能解码并直接报错,而不是显示乱码
总结就是,什么编码的数据都能传输过去,但是文本框只能进行GBK和Unicode解码,而传输回来的数据是直接对文本框字符进行Unicode编码。所以假如你传输的GBK码,正确显示之后传回来的就是Unicode码。
PS:本文在写作过程中参看了大量网络资源和书籍,感谢各位程序员无私的分享,在此基础上加上自己的理解分析和实践,以更加详细的方式重新补充整理,希望能解决大家实际问题。在这个过程中其实还遇到了几个知其然不知其所以然的问题在文章中有标明,另外本人学习编程尚无多少时日,才疏学浅,文章定有疏漏,望不吝赐教。另外,本博客将尽量每周一篇原创技术文章,敬请关注,希望多多交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号