python-之基本语法
模块一些函数和类的集合文件,并实现一定的功能,当我们需要使用这些功能的时候,可以直接把相应的模块导入到我们的程序中
import
import mode #导入mode模块
即导入mode模块后,使用mode.***即可使用mode模块中的***方法,函数等。
from...import...
from mode import argv,path #从mode中导入特定的成员
即使用from mode import argv即可直接调用mode模块中argv函数,方法等
简单的说,使用第二种方法导入模块,那么调用模块中的函数的时候就不需要输入模块名称即可直接调用了。


http://jingyan.baidu.com/article/642c9d34e837d4644a46f7a2.html
序列有两种:tuple(定值表; 也有翻译为元组) 和 list (表)
tuple的各个元素不可再变更,而list的各个元素可以再变更。
1、元素的引用
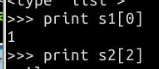
范围引用: 基本样式 [下限:上限:步长]——上限不包括


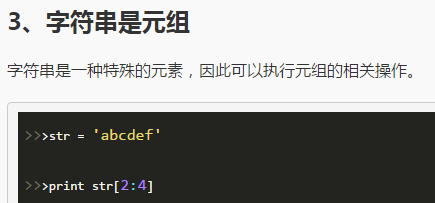
1、for循环


2、while循环

3、中断循环
-
continue 在循环的某一次执行中,如果遇到continue, 那么跳过这一次执行,进行下一次的操作
-
break 停止执行整个循环
一、词典
1、常用的词典方法
二、文本文件的输入输出
对象名 = open(文件名,模式)
最常用的模式有:
- r 打开只读文件,该文件必须存在。
- r+ 打开可读写的文件,该文件必须存在。
- w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
- w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
- a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留。
- a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
- 上述的形态字符串都可以再加一个b字符,如rb、w+b或ab+等组合,加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
,Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f:
print f.read()2、文件对象的方法
content = f.read(N) # 读取N bytes的数据
content = f.readline() # 读取一行
content = f.readlines() # 读取所有行,储存在列表中,每个元素是一行。
f.write('I like apple!\n') # 将'I like apple'写入文件并换行
f.close() # 不要忘记关闭文件
三、模块
我们先写一个first.py文件,内容如下:
def laugh():
print 'HaHaHaHa'
再写一个second.py,并引入first中的程序:
import first #将first文件引入
for i in range(10):
first.laugh()
Python中还有其它的引入方式:
import a as b # 引入模块a,并将模块a重命名为b
from a import function1 # 从模块a中引入function1对象。调用a中对象时,我们不用再说明模块,即直接使用function1,而不是a.function1。
from a import * # 从模块a中引入所有对象。调用a中对象时,我们不用再说明模块,即直接使用对象,而不是a.对象。2、模块包
可以将功能相似的模块放在同一个文件夹(比如说this_dir)中,构成一个模块包。通过
import this_dir.module
引入this_dir文件夹中的module模块。
该文件夹中必须包含一个 __init__.py 的文件,提醒Python,该文件夹为一个模块包。__init__.py 可以是一个空文件。
四、函数的参数传递
1、关键字传递
有些情况下,用位置传递会感觉比较死板。关键字(keyword)传递是根据每个参数的名字传递参数。关键字并不用遵守位置的对应关系。依然沿用上面f的定义,更改调用方式:
print(f(c=3,b=2,a=1))
关键字传递可以和位置传递混用。但位置参数要出现在关键字参数之前:
print(f(1,c=3,b=2))2、参数默认值
在定义函数的时候,使用形如a=19的方式,可以给参数赋予默认值(default)。如果该参数最终没有被传递值,将使用该默认值。
def f(a,b,c=10):
return a+b+c
print(f(3,2))
print(f(3,2,1))
3、包裹传递
在定义函数时,我们有时候并不知道调用的时候会传递多少个参数。这时候,包裹(packing)位置参数,或者包裹关键字参数,来进行参数传递,会非常有用。
下面是包裹位置传递的例子:(元组)
def func(*name):
print type(name)
print name
func(1,4,6)
func(5,6,7,1,2,3)下面是包裹关键字传递的例子:(字典)
def func(**dict):
print type(dict)
print dict
func(a=1,b=9)
func(m=2,n=1,c=11)
包裹传递的关键在于定义函数时,在相应元组或字典前加 * 或 * * 。
4、解包裹
* 和 **,也可以在调用的时候使用,即解包裹(unpacking), 下面为例:
1 def func(a,b,c): 2 print a,b,c 3 args = (1,3,4) 4 func(*args)
在这个例子中,所谓的解包裹,就是在传递tuple时,让tuple的每一个元素对应一个位置参数。在调用func时使用 * ,是为了提醒Python:我想要把args拆成分散的三个元素,分别传递给a,b,c。(设想一下在调用func时,args前面没有 * 会是什么后果?)
相应的,也存在对词典的解包裹,使用相同的func定义,然后:
1 dict = {'a':1,'b':2,'c':3} 2 func(**dict)
在传递词典dict时,让词典的每个键值对作为一个关键字传递给func。
5、混合
在定义或者调用参数时,参数的几种传递方式可以混合。但在过程中要小心前后顺序。
基本原则是:先位置,再关键字,再包裹位置,再包裹关键字,并且根据上面所说的原理细细分辨。
五、循环设计
1、range()
实现下标对循环的控制


2、enumerate()
每次循环中同时得到下标和元素

![]()
3、zip()
如果你多个等长的序列,然后想要每次循环时从各个序列分别取出一个元素,可以利用zip()方便地实现:


zip()函数的功能,就是从多个列表中,依次各取出一个元素。每次取出的(来自不同列表的)元素合成一个元组,合并成的元组放入zip()返回的列表中。zip()函数起到了聚合列表的功能。
六、函数对象
1、lambda函数
func = lambda x,y: x + y
print func(3,4)
ambda生成一个函数对象。该函数参数为x,y,返回值为x+y。函数对象赋给func。func的调用与正常函数无异。
以上定义可以写成以下形式:
def func(x, y):
return x + y
2、函数作为参数传递
函数可以作为一个对象,进行参数传递。函数名(比如func)即该对象。比如说:
def func(x, y):
return x + y
def test(f,a,b):
print 'test'
return f(a,b)
print test(func,3,5)
test函数的第一个参数f就是一个函数对象。将func传递给f,test中的f()就拥有了func()的功能。
我们因此可以提高程序的灵活性。可以使用上面的test函数,带入不同的函数参数。比如:
test((lambda x,y: x**2 + y), 6, 9)
3、map()函数

这里,map()有两个参数,一个是lambda所定义的函数对象,一个是包含有多个元素的表。map()的功能是将函数对象依次作用于表的每一个元素,每次作用的结果储存于返回的表re中。map通过读入的函数(这里是lambda函数)来操作数据(这里“数据”是表中的每一个元素,“操作”是对每个数据加3)。
![]()

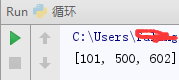
4、filter()函数
filter函数的第一个参数也是一个函数对象。它也是将作为参数的函数对象作用于多个元素。如果函数对象返回的是True,则该次的元素被储存于返回的表中。
filter通过读入的函数来筛选数据。同样,在Python 3.X中,filter返回的不是表,而是循环对象。
def func(a):
if a > 100:
return True
else:
return False
print filter(func,[10,56,101,500,602])
5、reduce()函数
reduce函数的第一个参数也是函数,但有一个要求,就是这个函数自身能接收两个参数。reduce可以累进地将函数作用于各个参数。
print reduce((lambda x,y: x+y),[1,2,5,7,9])上面例子,相当于(((1+2)+5)+7)+9
提醒: reduce()函数在3.0里面不能直接用的,它被定义在了functools包里面,需要引入包。
七、装饰器
装饰器(decorator)是一种高级Python语法。装饰器可以对一个函数、方法或者类进行加工。
def decorator(F):
def new_F(a, b):
print("input", a, b)
return F(a, b)
return new_F
# get square sum
@decorator
def square_sum(a, b):
return a**2 + b**2
# get square diff
@decorator
def square_diff(a, b):
return a**2 - b**2
print(square_sum(3, 4))
print(square_diff(3, 4))
当我们调用square_sum(3, 4)的时候,就相当于:
square_sum = decorator(square_sum) square_sum(3, 4)
七、内存管理

是数字的引用,整数1为一个对象。而a是一个引用。
可见a和c实际上是指向同一个对象的两个引用。
py是源文件,pyc是源文件编译后的文件,pyo是源文件优化编译后的文件,pyd是其他语言写的Python库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号