正则表达式、re模块
一、正则表达式(用来做字符串匹配)
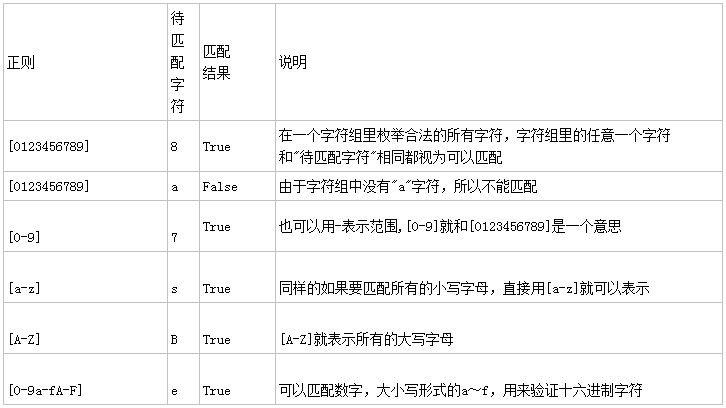
字符组 : [字符组] 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示 字符分为很多类,比如数字、字母、标点等等。 假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
字符组
字符
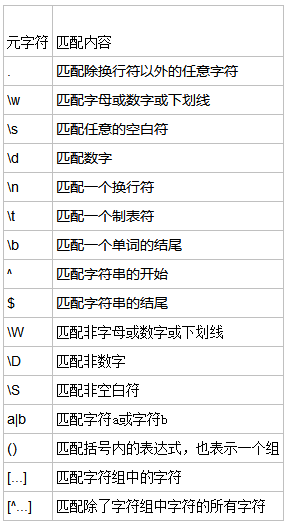
量词
? # 重复匹配 0次 或 1次 * # 重复匹配 0次 或 更多次 + # 重复匹配 1次 或 更多次 {n} # 重复匹配 n次 {n,} # 重复匹配 n次 或 更多次 {n,m} # 重复匹配 n次 到 m次
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配

几个常用的非贪婪匹配 ?? # 重复匹配 0次 或 1次,但尽可能少重复 *? # 重复匹配 任意次,但尽可能少重复 +? # 重复匹配 1次 或 更多次,但尽可能少重复 {n,} # 重复匹配 n次以上,但尽可能少重复 {n,m} # 重复匹配 n次 到 m次,但尽可能少重复
.*? 的用法 . # 任意字符 * # 取 0 至 无限长度 ? # 非贪婪模式 合在一起就是:取尽量少的任意字符; 但一般不会这么单独写,它大多用法为.*?x 表示取前面任意长度的字符,直到一个x出现
二、re模块下的常用方法
findall():返回所有满足匹配条件的结果,放在列表里
ret = re.findall("[a-z]+", "a b c") print(ret) # ['a', 'b', 'c']
search():从前往后找,匹配到一个就返回,返回的变量需要调用group()才能拿到结果;如果没匹配到,那么返回None,调用group会报错。
ret = re.search("b", "a b c") if ret: print(ret.group()) # b
match():从字符串开头开始匹配,如果正则规则从头开始可以匹配上,就返回一个变量;匹配的内容需要用group()才能拿到结果;如果没匹配到,就返回None,调用group会报错。
ret = re.match("a", "a b c") if ret: print(ret.group()) # a
split()
ret = re.split("[ab]", "abcd") # 先按a分割得到""和"bcd",再对""和"bcd"分别按b分割 print(ret) # ['', '', 'cd']
sub()
ret = re.sub("\d", "x", "ab12", 1) # 将数字替换成 x ,参数1表示只替换1个 print(ret) # abx2
subn()
ret = re.subn("\d", "x", "ab12", 1) # 将数字替换成 x ,返回一个元组(替换的结果,替换了多少次) print(ret) # ('abx2', 1)
complie():当正则规则较长且经常被使用的时候,使用complie()
obj = re.compile("\d{2}") # 将正则表达式编译成为一个"正则表达式对象", 匹配的是2个数字 ret = obj.search("a1b23") # 正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) # 23
finditer():返回一个存放匹配结果的迭代器
ret = re.finditer("\d", "a1b23c456") #finditer返回一个存放匹配结果的迭代器 print(next(ret).group()) # 1 查看第一个结果 print(next(ret).group()) # 2 查看第二个结果 # 查看剩余的左右结果 print([i.group() for i in ret]) #或者用for循环取值: for i in ret: print(i.group())
注意:
findall()的优先级查询
ret = re.findall("www.(baidu|cnblogs).com", "www.cnblogs.com") print(ret) # ["cnblogs"] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall("www.(?:baidu|cnblogs).com", "www.cnblogs.com") print(ret) # ["www.cnblogs.com"]
split()的优先级查询
ret=re.split("\d+", "ab1cd2ef") print(ret) # ['ab', 'cd', 'ef'] ret = re.split("(\d+)", "ab1cd2ef") print(ret) # ['ab', '1', 'cd', '2', 'ef'] """ 在匹配部分加上 () 之后所切出的结果是不同的, 没有 () 的,则没有保留所匹配的项,但是有 () 的却能够保留了匹配的项, 这个在某些需要保留匹配部分的使用过程是非常重要的。 """
匹配标签
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<h1>HelloWorld</h1>") # 在分组中利用 ?P<xx> 的形式给分组起名字,xx代表要定义的名字 # 获取的匹配结果可以直接用group("xx")拿到对应的值 print(ret.group("tag_name")) # h1 print(ret.group()) # <h1>HelloWorld</h1>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号