爬虫之Selenium库
官方文档:https://selenium-python.readthedocs.io/
Selenium:自动化测试工具,支持多种浏览器。爬虫中主要用来解决JavaScript渲染的问题。
一、开始
基本使用
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome() try: browser.get("https://www.baidu.com") input = browser.find_element_by_id("kw") # 查找id为kw的元素 input.send_keys("Python") # 相当于在输入框输入Python input.send_keys(Keys.ENTER) # 回车 wait = WebDriverWait(browser, 10) # 等待id为content_left的元素加载出来 wait.until(EC.presence_of_element_located((By.ID, "content_left"))) print(browser.current_url) print(browser.get_cookies()) print(browser.page_source) finally: browser.close()
声明浏览器对象
from selenium import webdriver browser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.Edge() browser = webdriver.PhantomJS() browser = webdriver.Safari()
访问页面
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com") print(browser.page_source) browser.close()
二、查找元素
单个元素
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com") # 查找id为q的元素 input1 = browser.find_element_by_id("q") # CSS选择器选择元素 input2 = browser.find_element_by_css_selector("#q") # xpath选择元素 input3 = browser.find_element_by_xpath("//*[@id='q']") print(input1, input2, input3) """ <selenium.webdriver.remote.webelement.WebElement (session="7b4386265c07c8e860a4e57cf7f15e6a", element="0.2418348835793498-1")> <selenium.webdriver.remote.webelement.WebElement (session="7b4386265c07c8e860a4e57cf7f15e6a", element="0.2418348835793498-1")> <selenium.webdriver.remote.webelement.WebElement (session="7b4386265c07c8e860a4e57cf7f15e6a", element="0.2418348835793498-1")> """ browser.close()
查找方式:


find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
通用查找方式:
from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get("https://www.taobao.com") input = browser.find_element(By.ID, "q") print(input) browser.close()
多个元素
实际上就是复数的区别。
from selenium import webdriver from selenium.webdriver.common.by import By browser = webdriver.Chrome() browser.get("https://www.taobao.com") li = browser.find_elements_by_css_selector(".service-bd li") print(li) browser.close() #################### li = browser.find_elements(By.CSS_SELECTOR, ".service-bd li") print(li) browser.close()
查找方式:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
三、元素交互操作
对获取的元素调用交互方法。
import time from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.taobao.com") input = browser.find_element_by_id("q") input.send_keys("iPhone") time.sleep(1) input.clear() input.send_keys("iPad") button = browser.find_element_by_class_name("btn-search") button.click()
更多操作:https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
四、交互动作
将动作附加到动作链中串行执行。
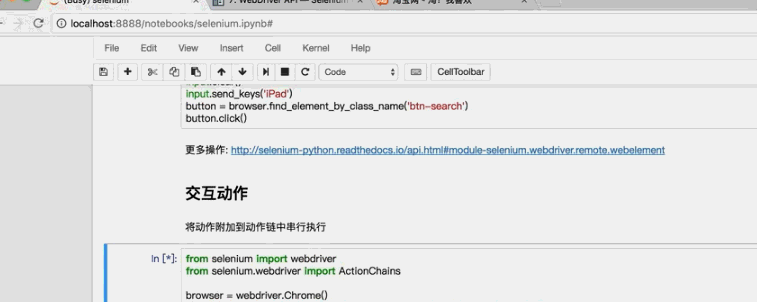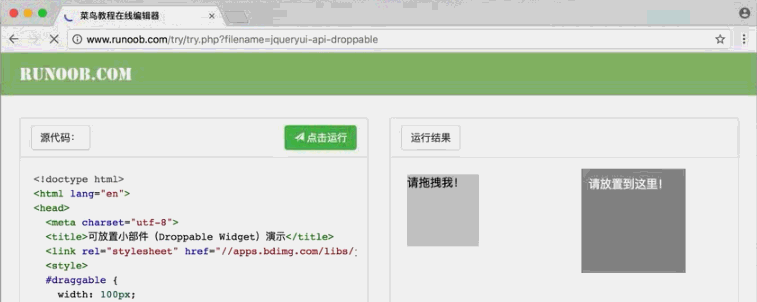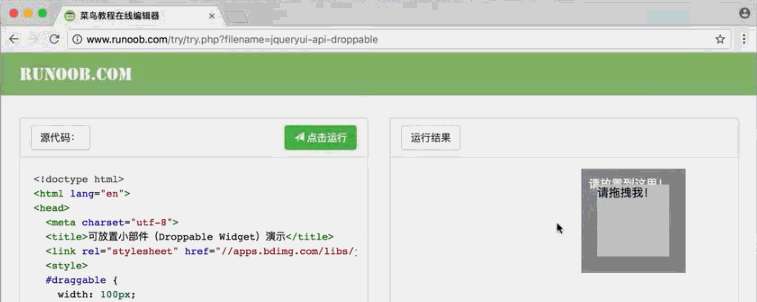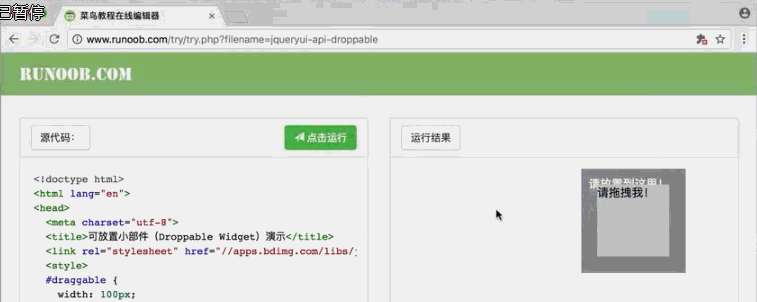
from selenium import webdriver from selenium.webdriver import ActionChains browser = webdriver.Chrome() url = "http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable" browser.get(url) browser.switch_to.frame("iframeResult") source = browser.find_element_by_css_selector("#draggable") target = browser.find_element_by_css_selector("#droppable") actions = ActionChains(browser) actions.drag_and_drop(source, target) actions.perform() # 执行这个动作
效果:
更多操作:https://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.action_chains
五、执行JavaScript
实现滚动条下拉:
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.zhihu.com/explore") browser.execute_script("window.scrollTo(0, document.body.scrollHeight)") browser.execute_script("alert('To Bottom')")
六、获取元素信息
获取属性
from selenium import webdriver browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) logo = browser.find_element_by_id("zh-top-link-logo") print(logo) print(logo.get_attribute("class"))
获取文本值
from selenium import webdriver browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) input = browser.find_element_by_class_name("zu-top-add-question") print(input.text)
获取ID、位置、标签名、大小
from selenium import webdriver browser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) input = browser.find_element_by_class_name("zu-top-add-question") print(input.id) # 0.11034585982176792-1 print(input.location) # {'x': 675, 'y': 7} print(input.tag_name) # button print(input.size) # {'width': 66, 'height': 32}
Frame
在父级frame查找子元素frame,必须要切换到这个frame里面才能实现。
from selenium import webdriver from selenium.common.exceptions import NoSuchElementException browser = webdriver.Chrome() url = "http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable" browser.get(url) browser.switch_to.frame("iframeResult") source = browser.find_element_by_css_selector("#draggable") print(source) # <selenium.webdriver.remote.webelement.WebElement (session="89ada324d9e5476b0fbb4f62392f31df", element="0.4817565418291889-1")> try: # 如果在frame里面查找frame外面的元素,很可能会报错 logo1 = browser.find_element_by_class_name("logo") except NoSuchElementException: # 找不到元素错误 print("No logo") # No logo browser.switch_to.parent_frame() # 切换到父frame logo2 = browser.find_element_by_class_name("logo") print(logo2) print(logo2.text) # RUNOOB.COM
七、等待
如果某些元素没有加载出来/完成,将会导致一些问题。所以应该设置等待,延长时间,确保元素完全都加载出来后,再进行一些操作,这样就可以避免一些异常出现。
隐式等待(如果网速特别慢,则可以使用)
当使用了隐式等待执行测试的时候,如果WebDriver没有在DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常。换句话说,当查找元素或元素并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。
from selenium import webdriver browser = webdriver.Chrome() browser.implicitly_wait(10) browser.get("https://www.zhihu.com/explore") # 如果网速特别慢,导致类属性值为zu-top-add-question这个元素没有加载出来,将会再等待10s input = browser.find_element_by_class_name("zu-top-add-question") print(input)
显式等待(常用)
你指定一个等待条件,再指定一个最长等待时间。显示等待会在最长等待时间内判断这个条件是否成立,如果成立则立即返回;如果不成立则会一直等待,直到等待到最长等待时间,如果还是不满足这个条件,就会抛出异常。
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC browser = webdriver.Chrome() browser.get("https://www.taobao.com/") wait = WebDriverWait(browser, 10) # 10代表最长等待时间 # 使用until传入等待条件 input = wait.until(EC.presence_of_element_located((By.ID, "q"))) # 判断id为q的元素是否出现了 button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search"))) # 判断这个元素是否可点击 print(input, button)
判断条件:
title_is # 标题是某内容 title_contains # 标题包含某内容 presence_of_element_located # 元素加载出,传入定位元组,如(By.ID, 'p') visibility_of_element_located # 元素可见,传入定位元组 visibility_of # 可见,传入元素对象 presence_of_all_elements_located # 所有元素加载出 text_to_be_present_in_element # 某个元素文本包含某文字 text_to_be_present_in_element_value # 某个元素值包含某文字 frame_to_be_available_and_switch_to_it # frame加载并切换 invisibility_of_element_located # 元素不可见 element_to_be_clickable # 元素可点击 staleness_of # 判断一个元素是否仍在DOM,可判断页面是否已经刷新 element_to_be_selected # 元素可选择,传元素对象 element_located_to_be_selected # 元素可选择,传入定位元组 element_selection_state_to_be # 传入元素对象以及状态,相等返回True,否则返回False element_located_selection_state_to_be # 传入定位元组以及状态,相等返回True,否则返回False alert_is_present # 是否出现Alert
七、前进后退
import time from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com/") browser.get("https://www.sogou.com/") browser.get("https://cn.bing.com/") browser.back() time.sleep(1) browser.forward() time.sleep(1) browser.close()
八、Cookies
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.zhihu.com/explore") print(browser.get_cookies()) browser.add_cookie({"domain": "www.zhihu.com", "value": "pd"}) print(browser.get_cookies()) browser.delete_all_cookies() print(browser.get_cookies())
九、标签页(窗口)切换
import time from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com") browser.execute_script("window.open()") print(browser.window_handles) browser.switch_to.window(browser.window_handles[1]) browser.get("https://www.sogou.com/") time.sleep(1) browser.switch_to.window(browser.window_handles[0]) browser.get("https://cn.bing.com/") browser.close()
十、异常处理
from selenium import webdriver browser = webdriver.Chrome() browser.get("https://www.baidu.com") browser.find_element_by_id("hello") browser.close() """ Traceback (most recent call last): File "E:/LearnPython/spider/request.py", line 3, in <module> browser = webdriver.Chrome() File "C:\Python3\lib\site-packages\selenium\webdriver\chrome\webdriver.py", line 81, in __init__ desired_capabilities=desired_capabilities) File "C:\Python3\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 157, in __init__ self.start_session(capabilities, browser_profile) File "C:\Python3\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 252, in start_session response = self.execute(Command.NEW_SESSION, parameters) File "C:\Python3\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 321, in execute self.error_handler.check_response(response) File "C:\Python3\lib\site-packages\selenium\webdriver\remote\errorhandler.py", line 242, in check_response raise exception_class(message, screen, stacktrace) selenium.common.exceptions.SessionNotCreatedException: Message: session not created from disconnected: received Inspector.detached event (Session info: chrome=73.0.3683.86) (Driver info: chromedriver=2.46.628402 (536cd7adbad73a3783fdc2cab92ab2ba7ec361e1),platform=Windows NT 6.1.7601 SP1 x86_64) """
捕获异常:
from selenium import webdriver from selenium.common.exceptions import TimeoutException, NoSuchElementException browser = webdriver.Chrome() try: browser.get("https://www.baidu.com") except TimeoutException: print("Timeout") try: browser.find_element_by_id("hello") except NoSuchElementException: print("NoSuchElement") finally: browser.close()
详细文档:https://selenium-python.readthedocs.io/api.html#module-selenium.common.exceptions

 浙公网安备 33010602011771号
浙公网安备 33010602011771号