软件工程实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(1/2)作业要求 |
| 这个作业的目标 | 完成项目,武汉加油 |
| 作业正文 | 软工实践寒假作业(2/2) |
| 其他参考文献 | 知乎、博客园、CSDN |
Github仓库地址
github地址:https://github.com/BeJame/InfectStatistic-main
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 45 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 500 | 600 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 15 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 35 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 60 | 45 |
| Coding | 具体编码 | 400 | 350 |
| Code Review | 代码复审 | 30 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 100 |
| Reporting | 报告 | 60 | 80 |
| Test Repor | 测试报告 | 30 | 20 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 25 |
| 合计 | 1300 | 1430 |
解题思路
1.解析命令行参数
2.解析日志文件
解析txt文件:
该日志中出现以下几种情况:
1、<省> 新增 感染患者 n人
2、<省> 新增 疑似患者 n人
3、<省1> 感染患者 流入 <省2> n人
4、<省1> 疑似患者 流入 <省2> n人
5、<省> 死亡 n人
6、<省> 治愈 n人
7、<省> 疑似患者 确诊感染 n人
8、<省> 排除 疑似患者 n人
计算并输出结果
将上一部分的解析结果存储起来,按照要求输出出去
设计实现过程
设计思路
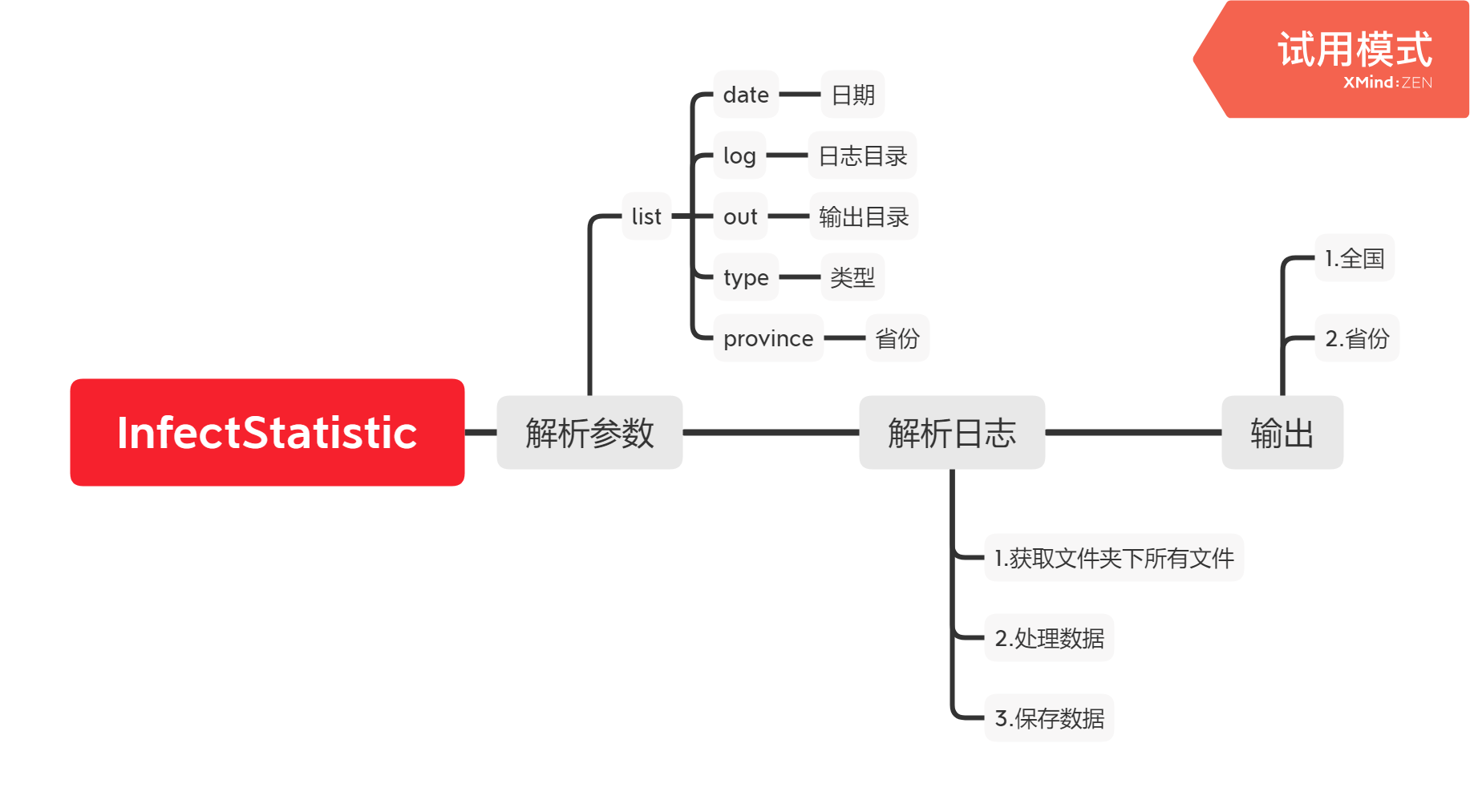
代码规范
参考《Python PEP8》编写了代码规范
代码说明
初始化函数:
def init(): # 初始化
provinces = ["河南", "河北", "北京", "天津", "山东", "广东",
"山西", "黑龙江", "吉林", "辽宁", "浙江", "香港",
"江苏", "上海", "安徽", "江西", "湖南", "福建", "澳门",
"湖北", "新疆", "云南", "贵州", "台湾", "宁夏", "西藏",
"四川", "重庆", "内蒙古", "广西", "海南", "青海", "甘肃", "陕西"]
output_data = {}
output_data["全国"] = {
"死亡": 0,
"治愈": 0,
"疑似": 0,
"感染": 0,
}
for province in provinces:
output_data[province] = {
"死亡": 0,
"治愈": 0,
"疑似": 0,
"感染": 0,
}
return output_data
处理,汇总数据:
def processFiles(file, output_data, dir):
f = open(os.path.join(dir, file), "r", encoding="utf-8")
raw_data = f.readlines()
for d in raw_data:
ld = str(d).replace("人", "").replace("\n", "").split(" ")
print(ld)
if ld[1] == "新增":
if ld[2] == "感染患者":
output_data[ld[0]]["感染"] += int(ld[-1])
output_data["全国"]["感染"] += int(ld[-1])
elif ld[2] == "疑似患者":
output_data[ld[0]]["疑似"] += int(ld[-1])
output_data["全国"]["疑似"] += int(ld[-1])
elif ld[1] == "感染患者":
output_data[ld[0]]["感染"] -= int(ld[-1])
output_data[ld[3]]["感染"] += int(ld[-1])
elif ld[1] == "疑似患者":
if ld[2] == "确诊感染":
output_data[ld[0]]["疑似"] -= int(ld[-1])
output_data[ld[0]]["感染"] += int(ld[-1])
output_data["全国"]["感染"] += int(ld[-1])
elif ld[2] == "流入":
output_data[ld[0]]["疑似"] -= int(ld[-1])
output_data[ld[3]]["疑似"] += int(ld[-1])
elif ld[1] == "死亡":
output_data[ld[0]]["死亡"] += int(ld[-1])
output_data["全国"]["死亡"] += int(ld[-1])
elif ld[1] == "治愈":
output_data[ld[0]]["治愈"] += int(ld[-1])
output_data["全国"]["治愈"] += int(ld[-1])
elif ld[1] == "排除":
output_data[ld[0]]["疑似"] -= int(ld[-1])
output_data["全国"]["疑似"] -= int(ld[-1])
解析命令行:
parser = argparse.ArgumentParser(usage="缺乏必要参数", description="help info.")
parser.add_argument("-date", type=str, required=True)
parser.add_argument("-log", type=str, required=True)
parser.add_argument("-out", type=str, default="Today")
parser.add_argument("-type", type=str, default=["ip", "sp", "cure", "dead"], nargs="*")
parser.add_argument("-province", type=str, default="All", nargs="*")
单元测试
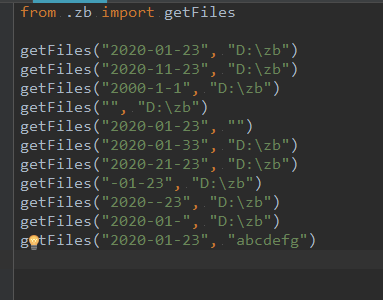
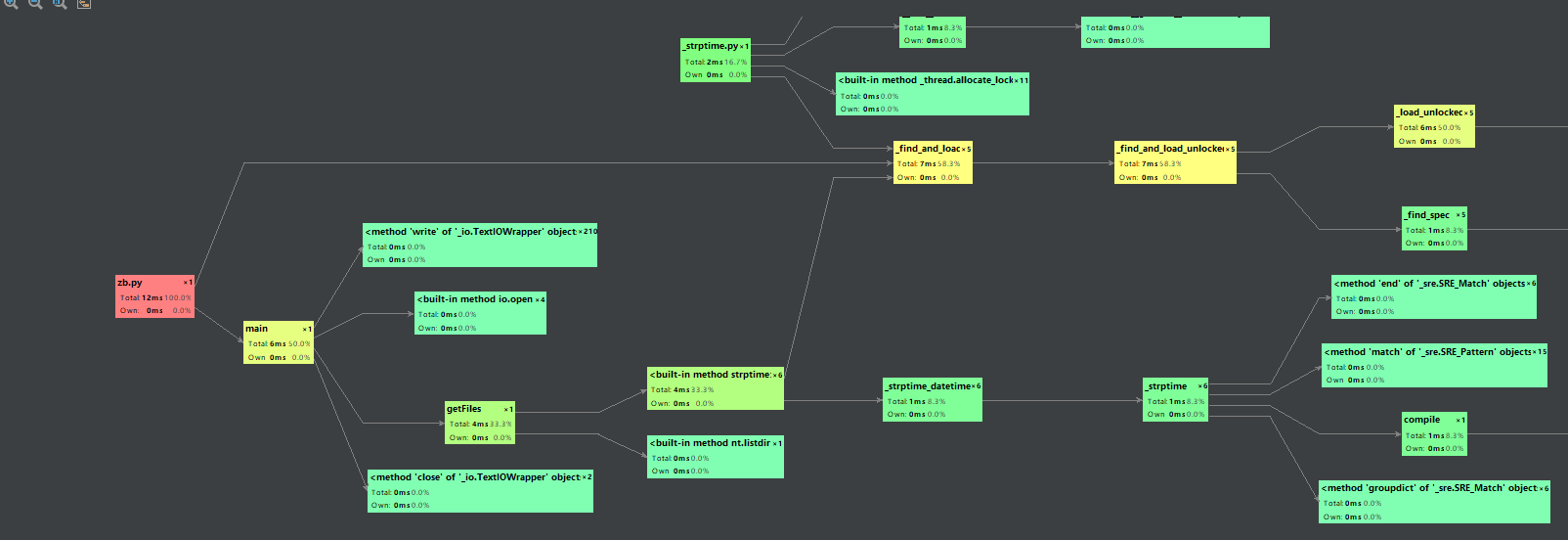
性能测试、覆盖率
心路历程和收获
完成了一次作业吧
自己处于找工作的时间,说实话挺影响准备春招的,而且作业内容跟自己找的工作关系不大。
5个仓库
1.Archery
Python项目,定位于SQL审核查询平台,旨在提升DBA的工作效率,支持主流数据库的SQL上线和查询,同时支持丰富的MySQL运维功能,所有功能都兼容手机端操作
2.git-webhook
一个使用 Python Flask + SQLAchemy + Celery + Redis + React 开发的用于迅速搭建并使用 WebHook 进行自动化部署和运维系统
3.pallets
用于构建Web应用程序的Python微框架。
4.Web2py
免费和开源的全栈企业框架,用于敏捷开发安全的数据库驱动的基于Web的应用程序
5.Buildbot
用于buildbot和github的 集成机器人

 浙公网安备 33010602011771号
浙公网安备 33010602011771号