数据结构与算法
一、复杂度分析
1.1 重要性
- 复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本掌握了一半
- “事后统计法”的测试结果非常依赖测试环境,受数据规模的影响很大
- 需要一个不用具体的测试数据来测试,就可以粗略的估计算法的执行效率的方法
1.2 大O复杂度表示法
大O时间复杂度表示法,实际上并不具体代表代码真正的执行时间,而是代表代码执行时间随数据规模增长的变化趋势,简称时间复杂度
- 假设每行代码的执行时间都一样
- 所有代码的执行时间与代码执行的次数成正比
- T(n)表示代码执行时间,n表示数据规模大小,f(n)表示每行代码执行的次数总和
T(n) = O(f(n))
1.3 时间复杂度分析
- 只关注循环执行次数最多的一段代码
- 我们通常会忽略常量、低阶、系数,只记录一个最大阶的量级就可以了
- 加法法则:总复杂度等于量级最大的那段代码的复杂度
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
1.4 几种常见的时间复杂度分析

O(1)
- 表示常量级时间复杂度
- 一般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万行代码,其时间复杂度也是O(1)
O(logn)、O(nlogn)
- 不管是以2为底、以3为底还是以10为底,我们可以把所有对数阶的时间复杂度都记为O(logn)
- 将一段时间复杂度为O(logn)的代码执行n遍,时间复杂度就是O(nlogn)
- 归并排序和快速排序的时间复杂度都是O(nlogn)
- 归并排序
public class MergeSortTest {
public static void main(String[] args) {
//测试数据
int A[] = { 1, 6, 4, 5, 2, 9, 7, 23, 56, 43, 99 };
// 排序前
System.out.println("排序前:");
for (int a : A) {
System.out.print(a + " ");
}
System.out.println();
// 排序
mergeSort(A);
// 排序后
System.out.println("排序后:");
for (int a : A) {
System.out.print(a + " ");
}
System.out.println();
}
// 排序入口
public static void mergeSort(int[] A) {
sort(A, 0, A.length - 1);
}
//递归
public static void sort(int[] A, int start, int end) {
if (start >= end)
return;
// 找出中间索引
int mid = (start + end) / 2;
// 对左边数组进行递归
sort(A, start, mid);
// 对右边数组进行递归
sort(A, mid + 1, end);
// 合并
merge(A, start, mid, end);
}
// 将两个数组进行归并,归并前面2个数组已有序,归并后依然有序
public static void merge(int[] A, int start, int mid, int end) {
int[] temp = new int[A.length];// 临时数组
int k = 0;
int i = start;
int j = mid + 1;
while (i <= mid && j <= end) {
// 从两个数组中取出较小的放入临时数组
if (A[i] <= A[j]) {
temp[k++] = A[i++];
} else {
temp[k++] = A[j++];
}
}
// 剩余部分依次放入临时数组(实际上两个while只会执行其中一个)
while (i <= mid) {
temp[k++] = A[i++];
}
while (j <= end) {
temp[k++] = A[j++];
}
// 将临时数组中的内容拷贝回原数组中 (left-right范围的内容)
for (int m = 0; m < k; m++) {
A[m + start] = temp[m];
}
}
}
- 快速排序
public class QuickSort {
public static void main(String[] args) {
int[] arr = new int[] {9,4,6,8,3,10,4,6};
quickSort(arr,0,arr.length - 1);
System.out.println(Arrays.toString(arr));
}
public static void quickSort(int[] arr,int low,int high) {
int p,i,j,temp;
if(low >= high) {
return;
}
//p就是基准数,这里就是每个数组的第一个
p = arr[low];
i = low;
j = high;
while(i < j) {
//右边当发现小于p的值时停止循环
while(arr[j] >= p && i < j) {
j--;
}
//这里一定是右边开始,上下这两个循环不能调换(下面有解析,可以先想想)
//左边当发现大于p的值时停止循环
while(arr[i] <= p && i < j) {
i++;
}
temp = arr[j];
arr[j] = arr[i];
arr[i] = temp;
}
arr[low] = arr[i];//这里的arr[i]一定是停小于p的,经过i、j交换后i处的值一定是小于p的(j先走)
arr[i] = p;
quickSort(arr,low,j-1); //对左边快排
quickSort(arr,j+1,high); //对右边快排
}
}
- 快速排序2
function quickSort2(arr, start, end) {
if (end <= 1) {
return arr;
}
if (start >= end) {
return [];
}
// 选取基准值
var base = arr[end - 1];
var i = start;
var j = start;
// 将i作为小于基准值的右边界
// 如果arr[j]小于基准值,则将arr[i]和arr[j]交换,i++;j++
// 如果arr[j]大于基准值,则不交换,j++
while(i <= j && i < end && j < end) {
if (arr[j] < base) {
swap(arr, i, j);
i++;
j++;
} else {
j++;
}
}
// 将arr[i]和base交换
swap(arr, i, end - 1);
quickSort2(arr, start, i);
quickSort2(arr, i + 1, end);
return arr;
}
function swap(arr, i, j) {
var a = arr[i];
var b = arr[j];
var c = a ^ b;
arr[i] = c ^ a;
arr[j] = c ^ b;
}
O(m+n)、O(m*n)
- 需要考虑两端代码的数据规模
1.5 空间复杂度
- 表示算法的存储空间和数据规模之间的增长关系
1.6 最好、最坏情况时间复杂度
- 最好情况时间复杂度:在最理想的情况下,执行这段代码的时间复杂度
- 最坏情况时间复杂度:在最糟糕的情况下,执行这段代码的时间复杂度
1.7 平均时间复杂度
- 将n种情况下的时间复杂度进行累加,再除以n,得到的时间复杂度
1.8 小结
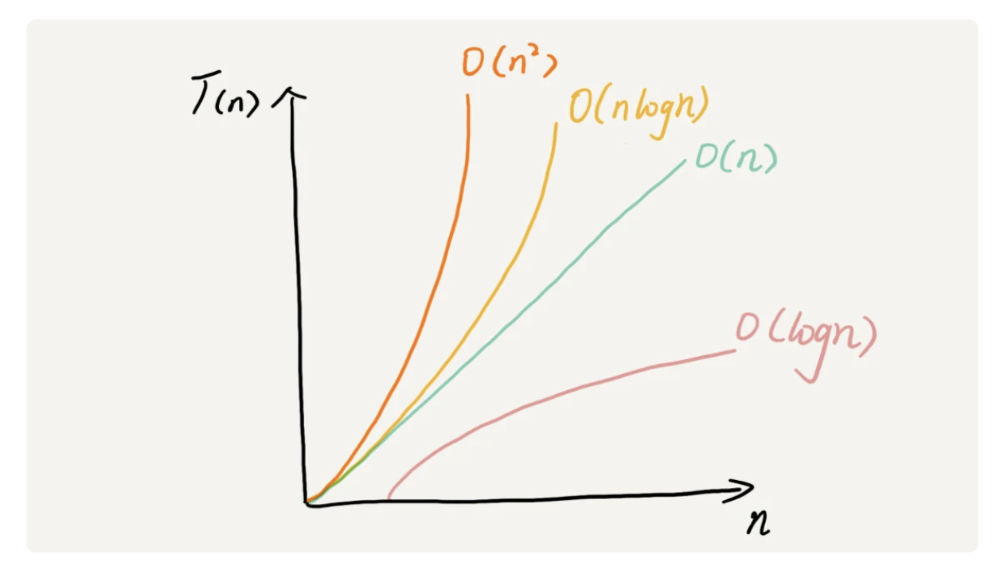
- 越高阶复杂度的算法,执行效率越低
二、数组
2.1 什么是数组?
- 数组(Array)是一种线性表数据结构,它是一组连续的内存空间,来存储一组具有相同类型的数据
线性表
- 线性表就是数据排成像一条线一样的结构,每个线性表上的数据只有前和后两个方向
- 除了数组,链表、栈、队列都是线性表结构
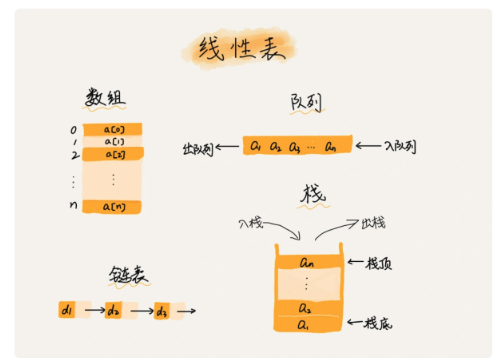
连续的内存空间和相同类型的数据
- 支持“随机访问”,用下标进行随机访问的时间复杂度是O(1)
- 数组的其他操作变得非常低效,如:想要在数组中插入、删除一个数据,为了保证连续性,需要进行大量的数据搬移工作
数组插入操作
- 假设数组长度为n,如果将一个数据插入到数组的第k个位置,我们需要将k~n的数据都向后挪一位,平均时间复杂度是O(n)
数组删除操作
- 如果我们要删除第k个位置的数据,为了保证内存的连续性,我们也需要做数据搬移工作,平均时间复杂度是O(n)
- JVM标记清除垃圾回收算法的核心思想:先标记和记录已删除的数据,但不立即进行删除,当数组没有更多空间存储数据时,再执行一次真正的删除操作
2.2 为什么数组下标是从0开始
- 从数组存储的内存模型上看,“下标”最确切的定义应该是“偏移”,如果用a来表示数组的首地址,a[0]就是表示偏移为0的位置,a[k]就表示偏移k个type_size的位置,a[k]内存地址的公式为:
a[k]_adress = base_adress + k * type_size
三、链表
3.1 概念
- 链表是通过“指针”将一组零散的内存块串联起来使用
- 我们把内存块称为链表的“结点”
- 把记录下个结点地址的指针称为“后继指针”
3.2 单链表
![]()
- 头结点用来记录链表的基地址
- 尾结点指向一个空地址NULL

插入和删除
- 时间复杂度是O(1)
- 对链表进行频繁的插入删除操作,会导致频繁的内存申请和释放,容易产生内存碎片,如果是Java语言,就会导致频繁的GC
![]()
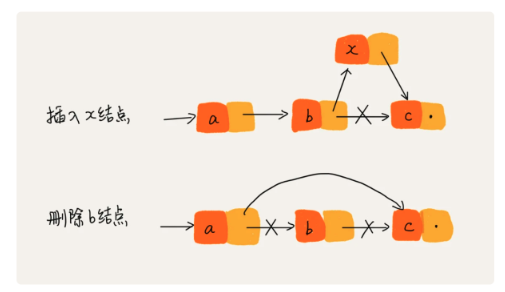
随机访问
- 时间复杂度是O(n),需要根据指针结点一个一个的遍历
3.3 循环链表
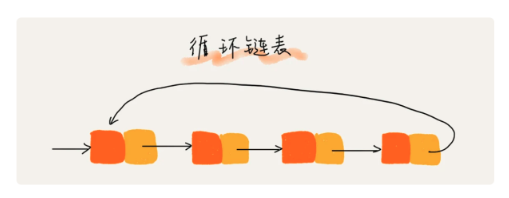
- 尾指针指向头结点
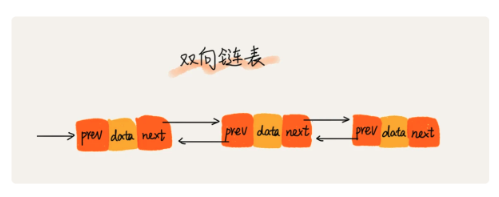
3.4 双向链表
![]()
- 具有前驱指针pre和后继指针next
- 双向链表需要额外的两个空间来存储前驱结点和后继结点的地址,存储空间会比单链表大
- 空间换时间:对于执行比较慢的程序,可以通过消耗更多的内存来进行优化
- 时间换空间:对于消耗内存较多的程序,可以通过消耗更多的时间来降低内存的消耗
3.5 基于链表实现LRU缓存淘汰算法
- 时间复杂度是O(n)
- 当有一个新的数据被访问时,从头开始遍历链表
- 如果此数据已经被缓存到链表中了,则先遍历得到该数据的结点,将其从原来位置删除,再将其插入到链表的头部
- 如果此数据没有在链表中,分以下两种情况
- 如果此时缓存没满,则直接将数据插入到链表的头部
- 如果此时缓存已满,则将链表尾部的结点删除,将该数据插入到链表的头部
3.6 指针
- 将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量
四、栈
4.1 概念
- 后进者先出,先进者后出,这是典型的“栈”结构
- 栈是一种“操作受限”的线性表,只允许在一段插入和删除数据
4.2 用数组实现一个栈
public class ArrayStack {
private String[] items; // 数组
private int count; // 数组元素个数
private int n; // 数组大小
public ArrayStack(int n) {
this.items = new String[n];
this.count = 0;
this.n = n;
}
// 进栈
public boolean push(String item) {
if (count == n) {
return false;
}
items[count] = item;
count++;
return true;
}
// 出栈
public String pop() {
if (count == 0) {
return null;
}
String value = items[count];
count--;
return value;
}
}
- 空间复杂度是O(1)
- 时间复杂度是O(1)
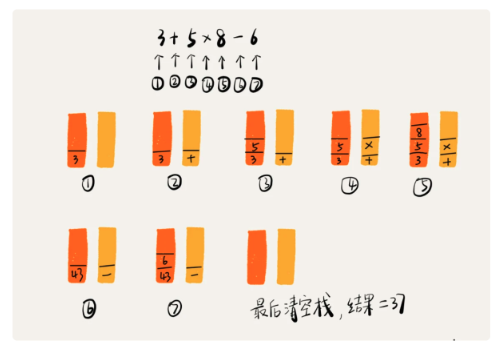
4.3 栈在表达式求值中的应用
- 两个栈,一个栈是保存操作数,一个栈是保存运算符
- 从左向右遍历表达式,如果遇到数字,直接压入操作数栈;如果遇到运算符,就与运算符栈的栈顶操作符比较
- 如果运算符栈的栈顶运算符优先级高,就把当前的运算符压入栈,反之,则取出操作数栈顶的两个数字,与运算符一起进行运算,将计算结果的数字压入操作数栈,继续比较
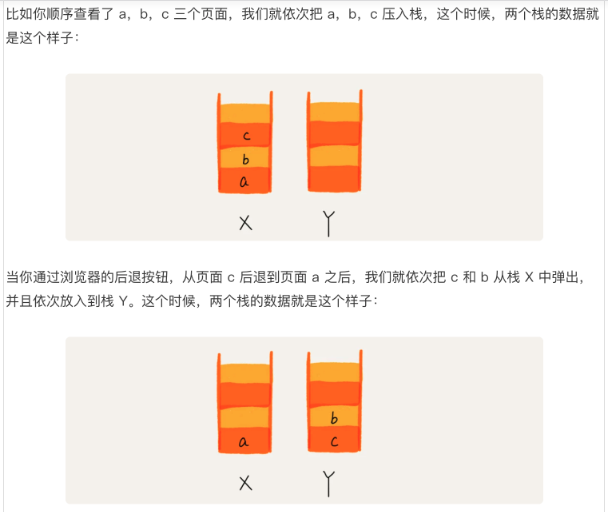
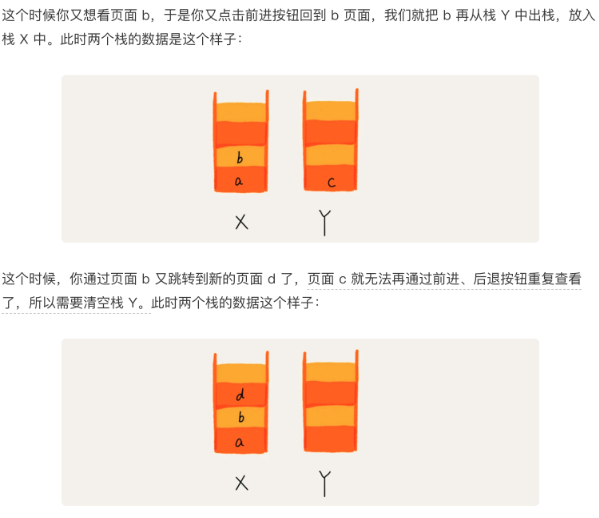
4.4 栈在浏览器前进后退功能的应用
- 使用两个栈,X和Y
- 把浏览的页面一次压入X栈
- 点击后退按钮时,把页面从X栈出栈,压入Y栈
- 点击前进按钮时,把页面从Y栈出栈,压入X栈
- 当X栈没有数据时,说明无法后退
- 当Y栈没有数据时,说明无法前进
五、队列
5.1 概念
- 先进者先出,这是典型的“队列”,是一种操作受限的线性表结构
- 入队:放一个数据到队列尾部
- 出队:从队列头部取出一个数据
![]()
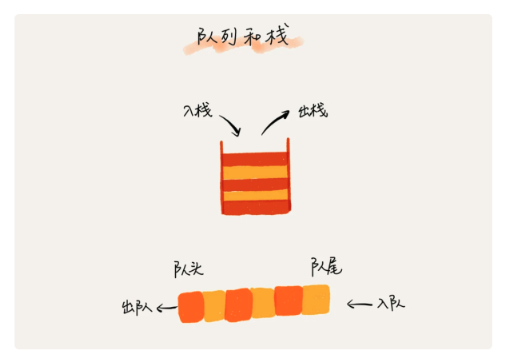
5.2 用数组实现顺序队列
public class ArrayQuene {
private String[] items;
private int n;
private int head; // 头指针
private int tail; // 尾指针
public ArrayQuene(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enquene(String item) {
if (tail == n) {
if (head == 0) {
// 队列满
return false;
}
// 数据搬移
for(int i = head; i < tail; i++) {
items[i-head] = items[i];
}
tail -= head;
head = 0;
}
items[tail] = item;
tail++;
return true;
}
// 出队
public String dequene() {
if (tail == head) {
return null;
}
String ret = items[head];
head++;
return ret;
}
}
5.3 用数组实现循环队列
public class CircularQuene {
private String[] items;
private int n;
private int head; // 头指针
private int tail; // 尾指针
public CircularQuene(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enquene(String item) {
if ((tail + 1) % n == head) {
// 队列满
return false;
}
items[tail] = item;
tail = (tail + 1) % n;
return true;
}
// 出队
public String dequene() {
if (tail == head) {
return null;
}
String ret = items[head];
head = (head + 1) % n;
return ret;
}
}
六、递归
6.1 递归需要满足的三个条件
- 一个问题的解可以分为几个字问题的解
- 这个问题与分解的字问题,除了数据规模之外,求解思路完全一致
- 存在递归终止条件
6.2 编写递归代码
- 写出递推公式,找到终止条件
- 斐波拉契数列
// 终止条件
f(1) = 1;
f(2) = 2;
// 递推公式
f(n) = f(n - 1) + f(n - 2)
6.3 递归代码警惕堆栈溢出和重复计算
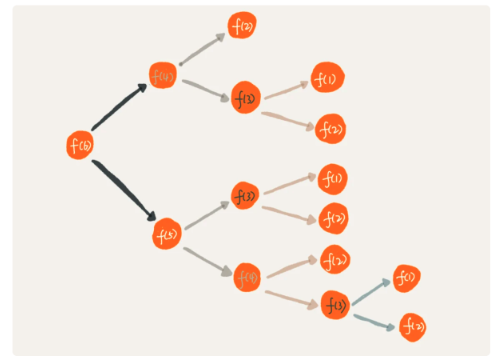
- 注意数据规模大小,小心堆栈溢出
- 用数据结构保存已经求解过的f(k)
6.3 将递归代码改成非递归代码
- 斐波拉契数列
function f(n) {
if (n === 1) {
return 1;
}
if (n === 2) {
return 2;
}
var ret = 0;
var pre = 1;
var prepre = 2;
for (var i = 3; i <=n; i++) {
ret = pre + prepre;
prepre = pre;
pre = ret;
}
return ret;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号