
作业要求


第一题
代码以及结果如下:
import time
import sqlite3
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
class myspider:
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"
}
def execute(self, url):
self.start(url)
self.process()
self.closeUp()
print("Completed......")
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def start(self, url):
chrome_options = Options()
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(options=chrome_options)
self.count = 0
self.num = 0
#连接数据库,如果存在就删除并建立
try:
self.con = sqlite3.connect("stock.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table stock")
except:
pass
try:
#数据库表的样式
sql = "create table stock(count varchar(256) ,num varchar(256),stockname varchar(256),lastest_price varchar(64),ddf varchar(64),dde varchar(64),cjl varchar(64),cje varchar(32),zhenfu varchar(32),top varchar(32),low varchar(32),today varchar(32),yestd varchar(32))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
self.driver.get(url)#浏览器得到地址
def insertDB(self, count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd):
#将从浏览器爬取得到的数据插入数据库
try:
sql = "insert into stock (count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd) values (?,?,?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("stock.db")
cursor = con.cursor()
print("count","num","stockname","lastest_price","ddf","dde","cjl","cje","zhenfu","top","low","today","yestd")
cursor.execute("select count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd from stock order by count")#sql语句获取数据
rows = cursor.fetchall()
for row in rows:
print(row[0], row[1], row[2], row[3], row[4],row[5], row[6], row[7], row[8], row[9],row[10], row[11], row[12])
con.close()#读取完数据,关闭数据库
except Exception as err:
print(err)
def process(self):#爬取数据
time.sleep(1)
try:
lis = self.driver.find_elements(By.XPATH,"//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
time.sleep(1)
for li in lis:
time.sleep(1)
num = li.find_element(By.XPATH,".//td[position()=2]/a[@href]").text
stockname = li.find_element(By.XPATH,".//td[@class='mywidth']/a[@href]").text #在网页审查元素找到对应的右键Copy 可以查看具体位置
lastest_price = li.find_element(By.XPATH,".//td[position()=5]/span").text
ddf = li.find_element(By.XPATH,".//td[position()=6]/span").text #//tr[1]/td[6]/span
dde = li.find_element(By.XPATH,".//td[position()=7]/span").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[7]/span
cjl = li.find_element(By.XPATH,".//td[position()=8]").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[8]
time.sleep(2)
cje = li.find_element(By.XPATH,".//td[position()=9]").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[9]
zhenfu = li.find_element(By.XPATH,".//td[position()=10]").text #//*[@id="table_wrapper-table"]/tbody/tr[1]/td[10]
top = li.find_element(By.XPATH,".//td[position()=11]/span").text #//./td[11]/span
low = li.find_element(By.XPATH,".//td[position()=12]/span").text #//tr[1]/td[12]/span
today = li.find_element(By.XPATH,".//td[position()=13]/span").text #//td[13]/span
yestd = li.find_element(By.XPATH,".//td[position()=14]").text #
time.sleep(2)
self.count = self.count + 1
count=self.count
self.insertDB(count,num,stockname,lastest_price,ddf,dde,cjl,cje,zhenfu,top,low,today,yestd )
nextPage = self.driver.find_element(By.XPATH,
"//div[@class='dataTables_wrapper']//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button']")
time.sleep(10)
self.num += 1
if (self.num < 4):
nextPage.click()
self.process()
except Exception as err:
print(err)
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = myspider()
myspider().execute(url)
myspider().showDB()
运行结果
可以看到存储在当前文件夹:
运行时间有点长:
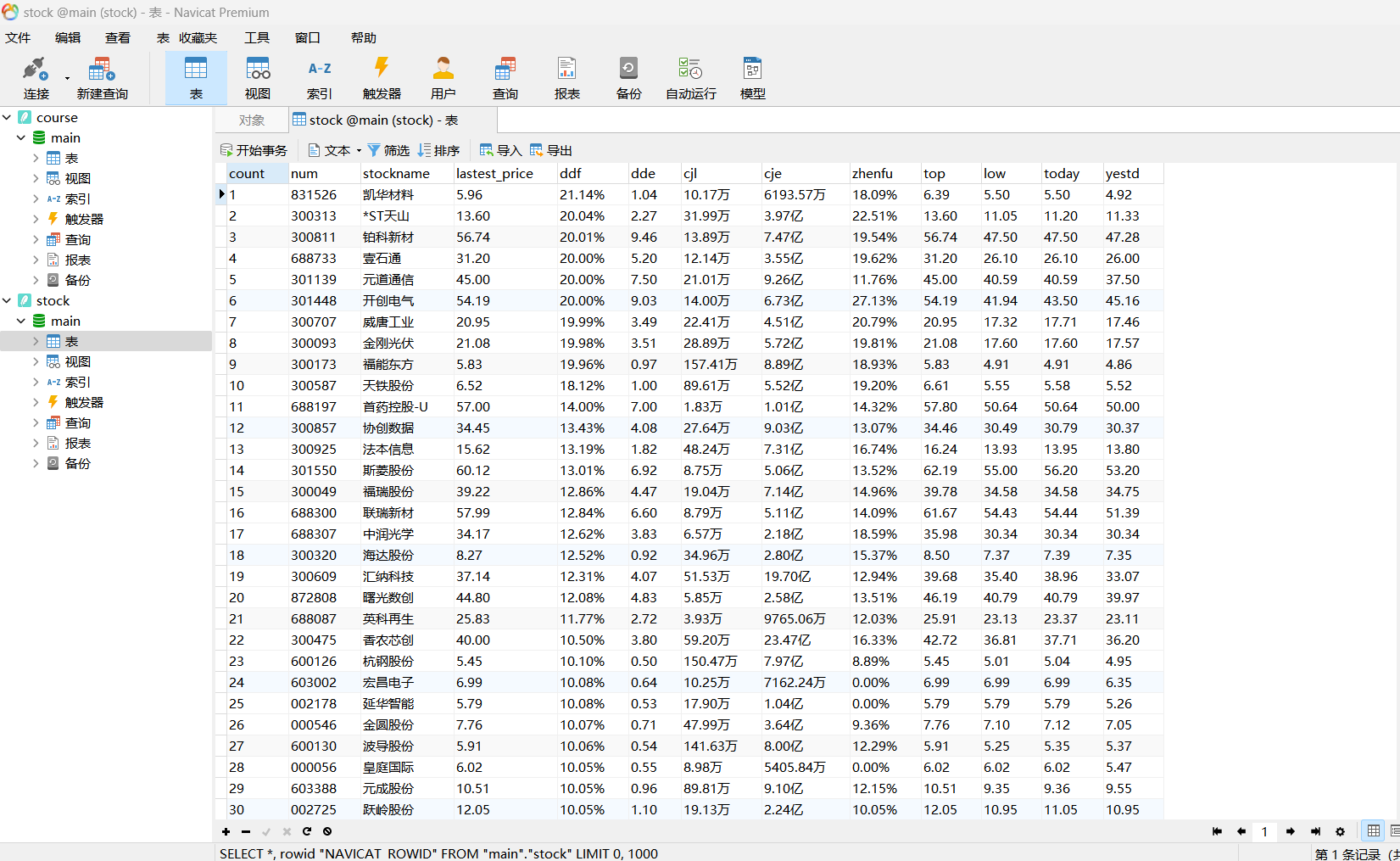
结果用Navicat查看:
心得
熟悉了一下selenium的相关操作
第二题:
代码以及运行结果如下:
import time
import sqlite3
from selenium import webdriver
from scrapy.selector import Selector
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def store_course_info(i, name, school, teacher, team, number, process, production):
conn = sqlite3.connect('course.db')
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS mooc
(Id INT, cCourse TEXT, cCollege TEXT, cTeacher TEXT, cTeam TEXT, cCount INT, cProcess TEXT, cBrief TEXT)''')
cursor.execute("INSERT INTO mooc (Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (?, ?, ?, ?, ?, ?, ?, ?)",
(i, name, school, teacher, team, number, process, production))
conn.commit()
conn.close()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
driver = webdriver.Chrome(options=chrome_options)
def login(driver, username, password):
driver.get("https://www.icourse163.org/")
driver.maximize_window()
button = driver.find_element(By.XPATH,'//div[@class="_1Y4Ni"]/div')
button.click()
frame = driver.find_element(By.XPATH,
'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(frame)
account = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input')
account.send_keys(username)
code = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')
code.send_keys(password)
login_button = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
login_button.click()
driver.switch_to.default_content()
time.sleep(10)
def search_courses(driver, keyword):
select_course = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[1]/div/div/div/div/div/div/input')
select_course.send_keys(keyword)
search_button = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/div/div/div/div[7]/div[1]/div/div/div[2]/span')
search_button.click()
time.sleep(5)
wait = WebDriverWait(driver, 10)
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".th-bk-main-gh")))
html = driver.page_source
selector = Selector(text=html)
datas = selector.xpath("//div[@class='m-course-list']/div/div")
for i, data in enumerate(datas, start=1):
name = data.xpath(".//span[@class=' u-course-name f-thide']//text()").extract()
name = "".join(name)
schoolname = data.xpath(".//a[@class='t21 f-fc9']/text()").extract_first()
teacher = data.xpath(".//a[@class='f-fc9']//text()").extract_first()
team = data.xpath(".//a[@class='f-fc9']//text()").extract()
team = ",".join(team)
number = data.xpath(".//span[@class='hot']/text()").extract_first()
process = data.xpath(".//span[@class='txt']/text()").extract_first()
production = data.xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']//text()").extract()
production = ",".join(production)
store_course_info(i, name, schoolname, teacher, team, number, process, production)
login(driver, '15160783997', '1a2345678')
search_courses(driver, '大数据')
# 关闭浏览器
driver.quit()
运行结果

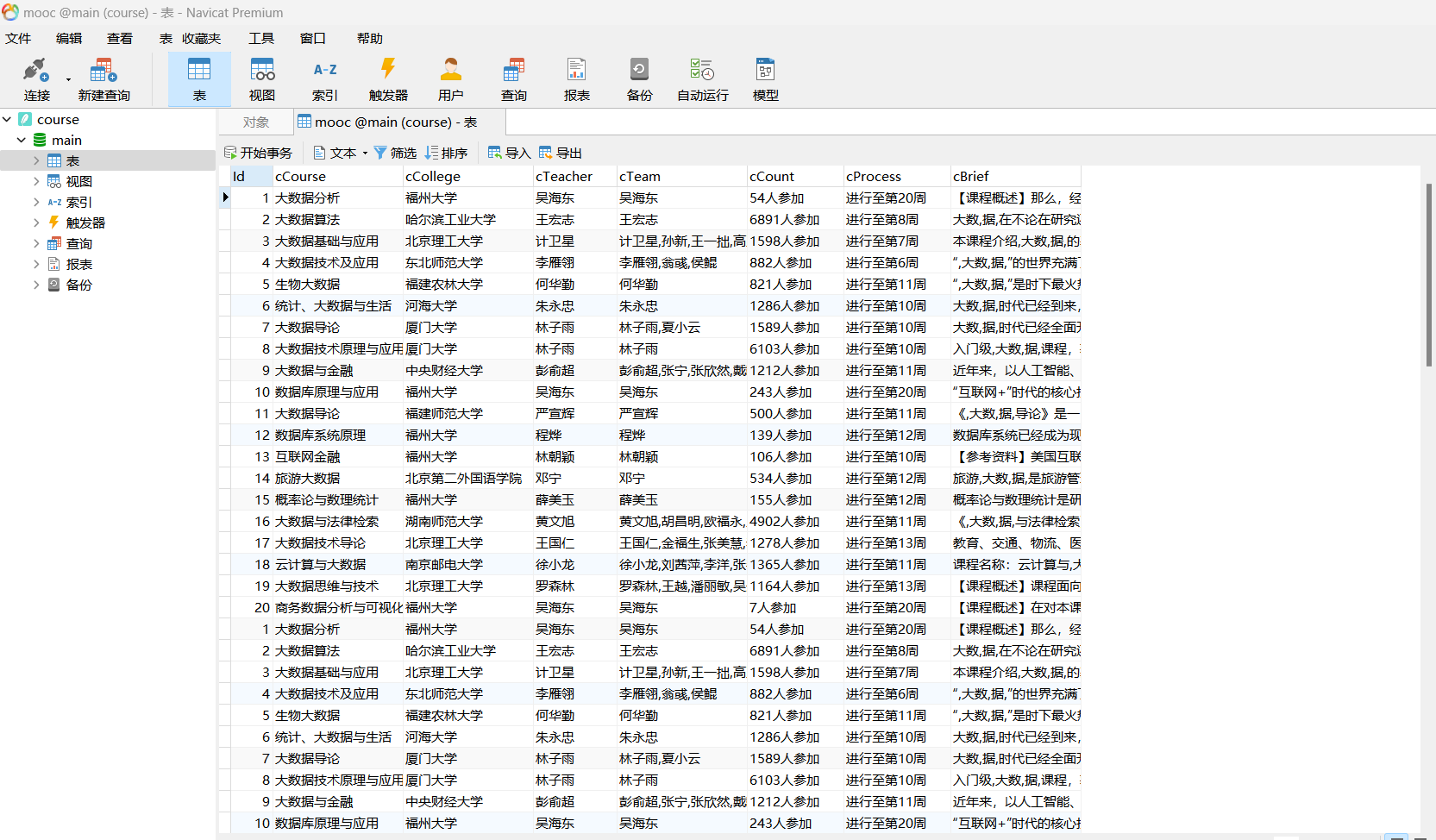
心得
利用selenium实现模拟登录是个难点
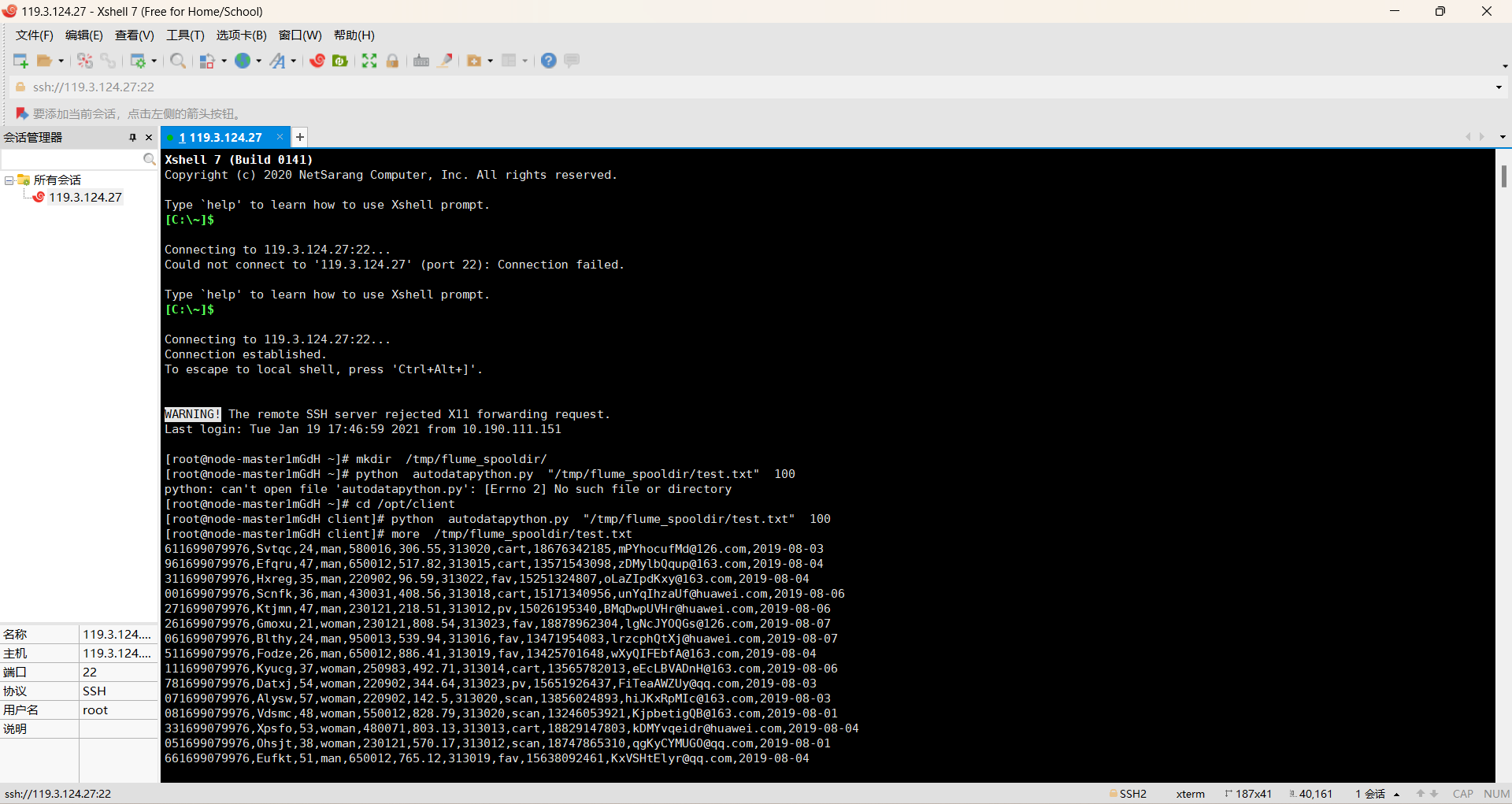
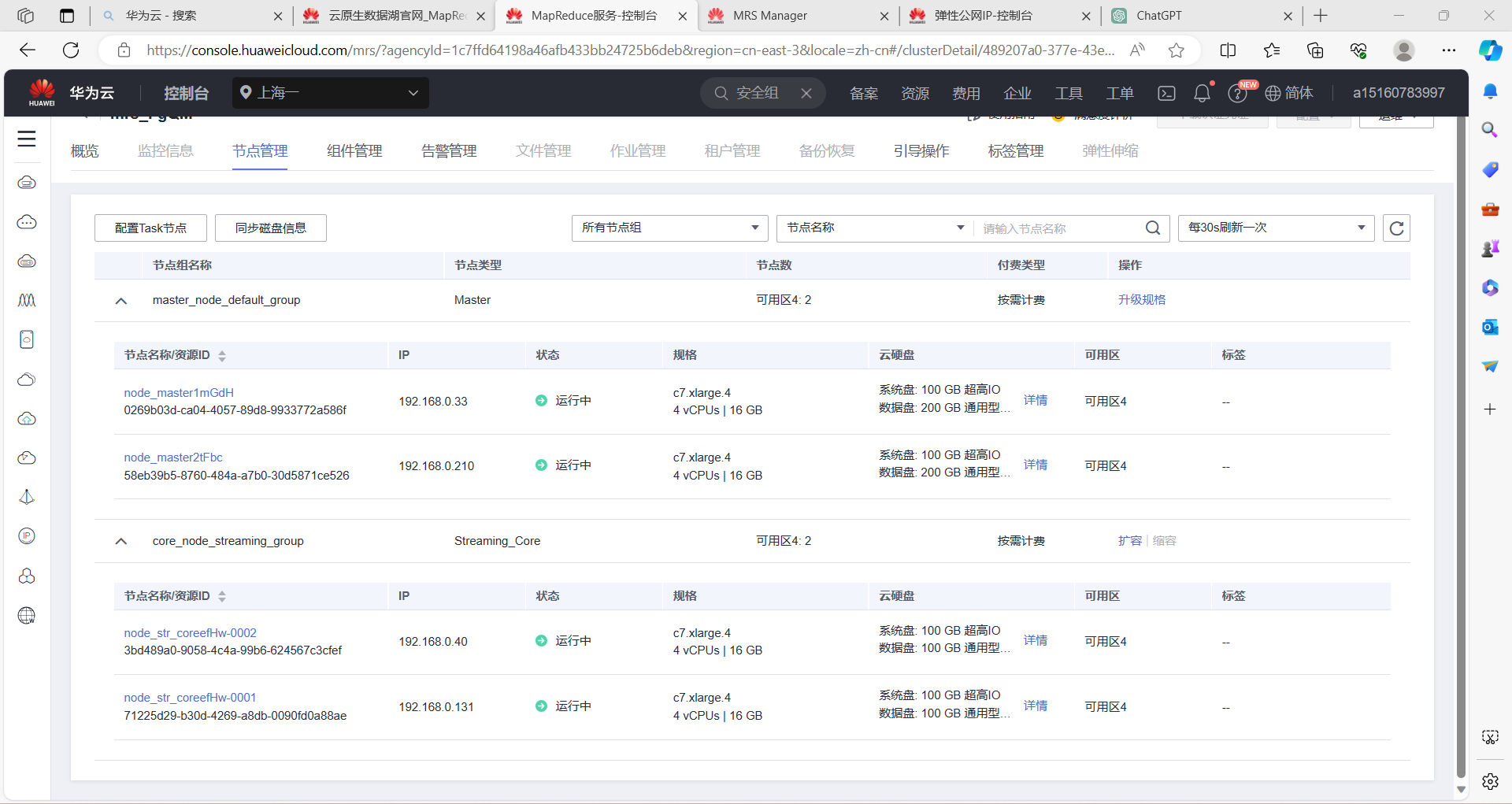
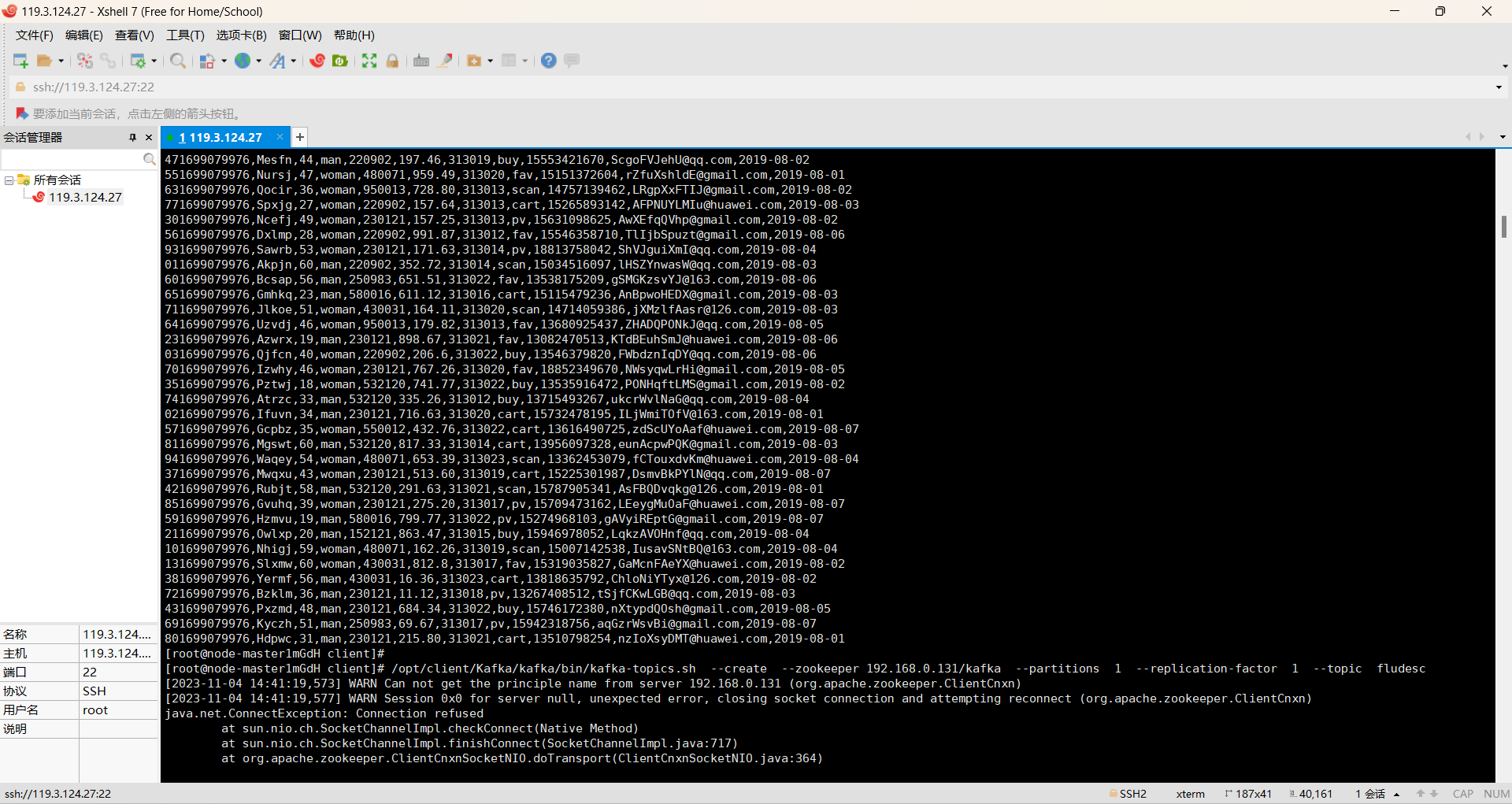
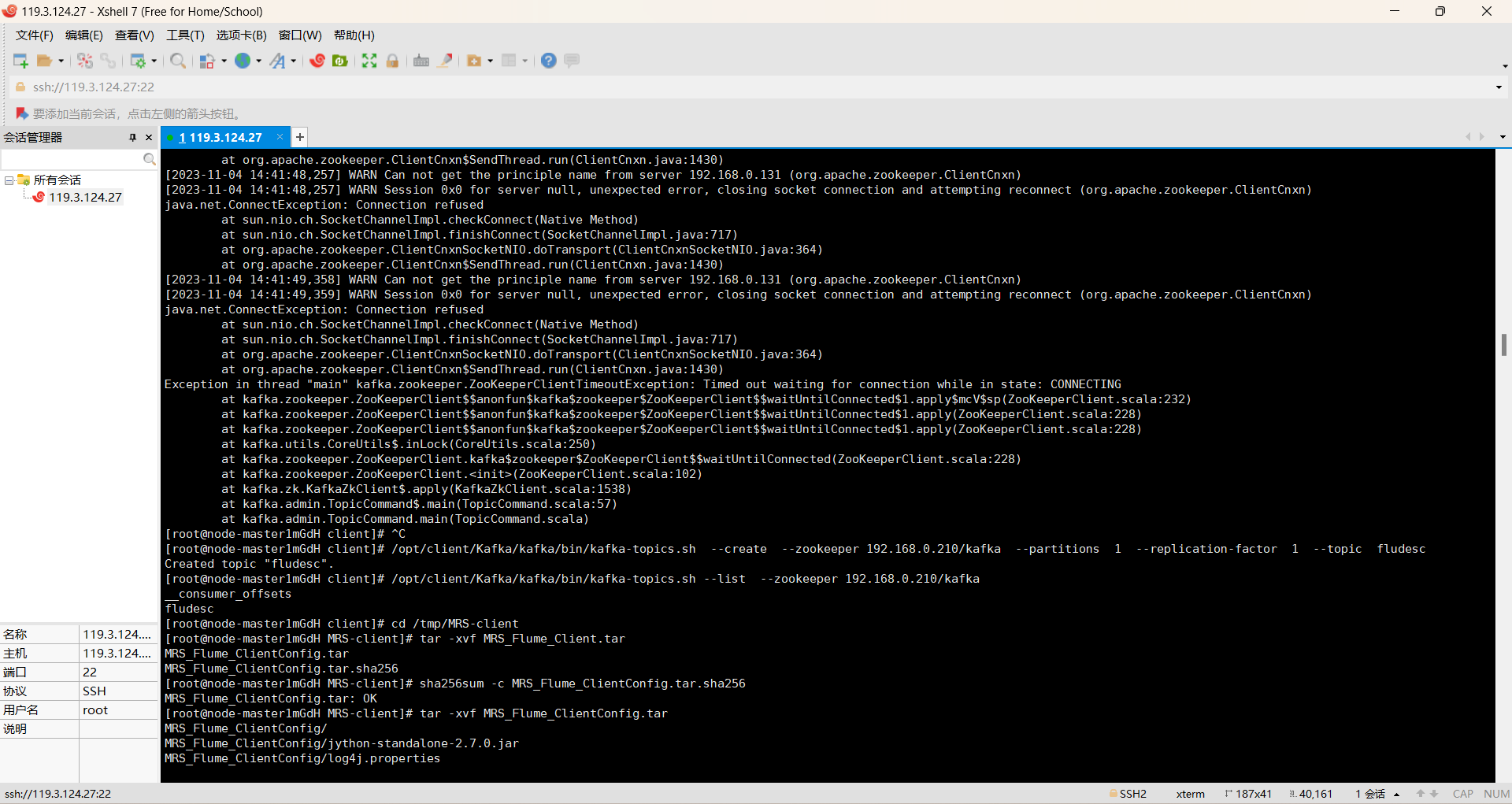
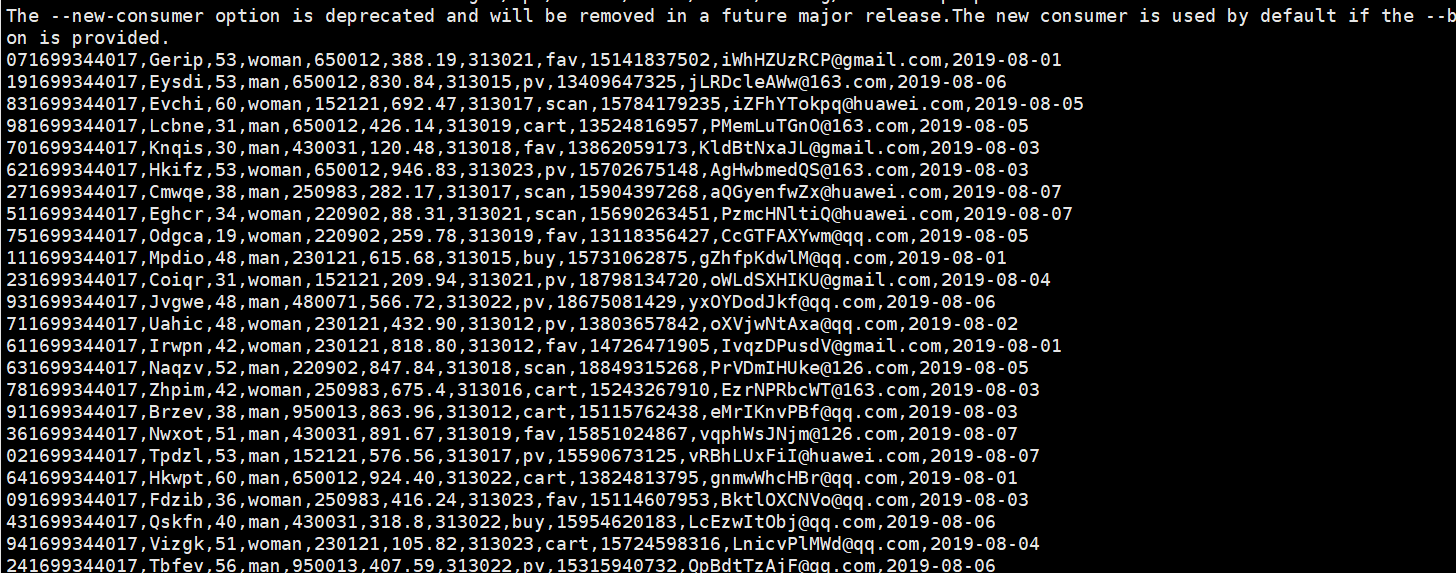
第三题:
过程如下:
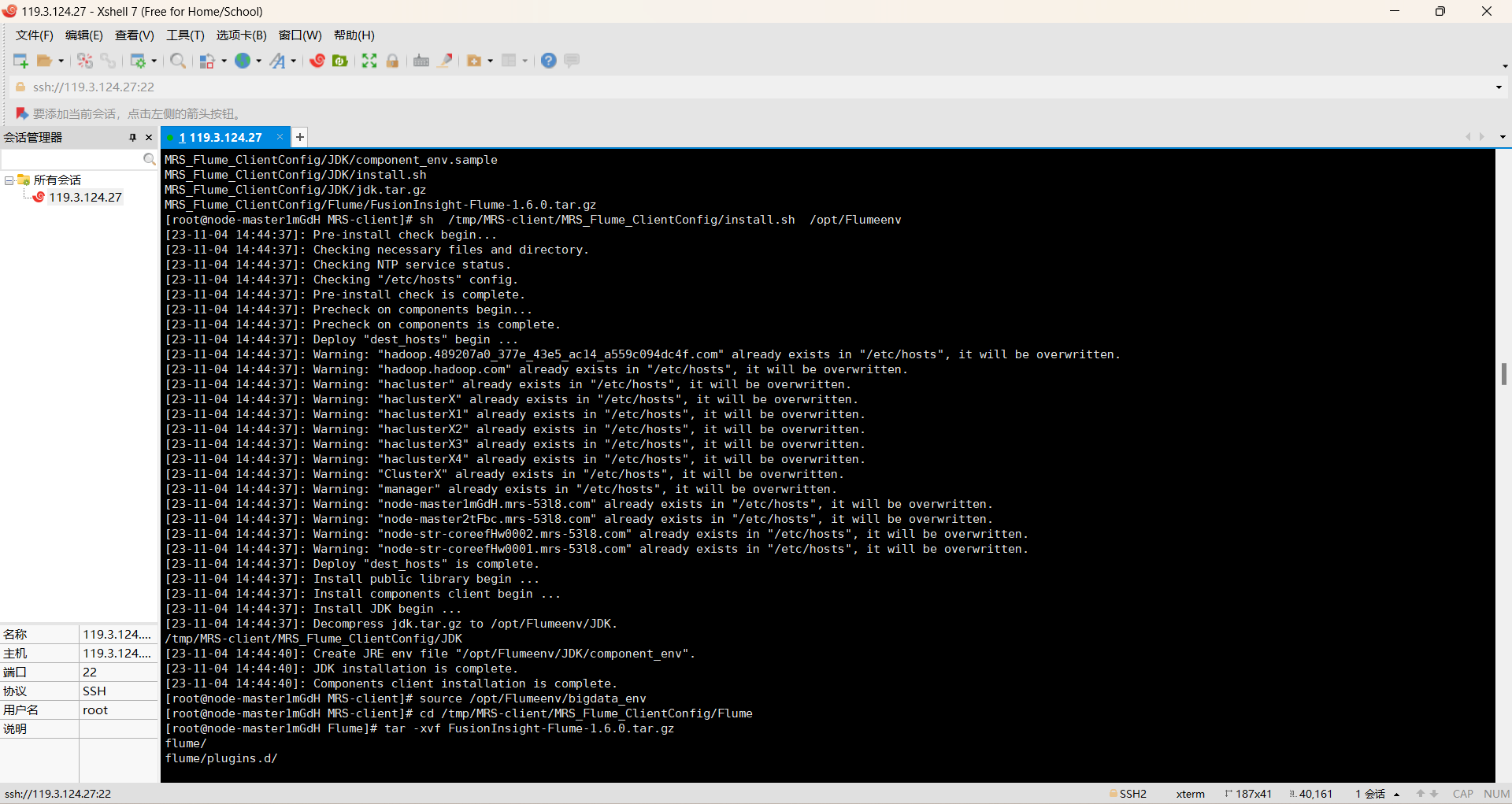
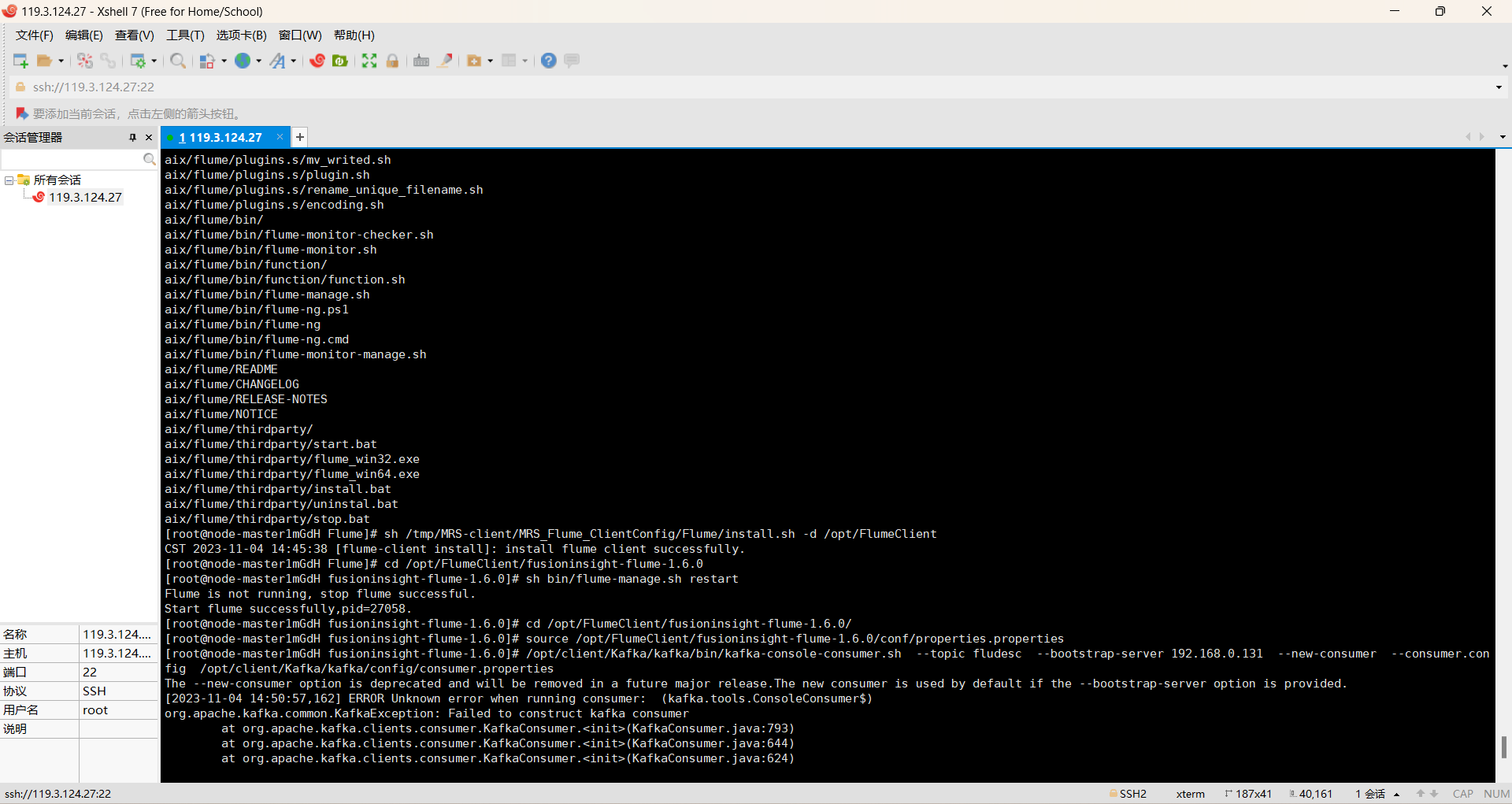
心得
掌握了大数据相关服务,熟悉Xshell的使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号