


数据采集与融合作业一
作业1-大学排名
*实验内容
对大学排名进行爬取,完整代码如下:
`
import requests
from bs4 import BeautifulSoup
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
def getHTMLText(url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as err:
print(err)
return None
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
tbody = soup.find('tbody')
for tr in tbody.find_all('tr'):
if tr.name == 'tr':
a = tr.find('a')
tds = tr.find_all('td')
ulist.append([tds[0].text.strip(), a.text.strip() if a else '', tds[2].text.strip(),tds[3].text.strip(), tds[4].text.strip()])
def printUnivList(ulist, num):
tplt = "{0:10}\t{1:10}\t{2:12}\t{3:12}\t{4:^10}"
print(tplt.format("排名", "学校名称", "省份", "学校类型", "总分"))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], u[4]))
def main():
uinfo = []
html = getHTMLText(url)
if html:
fillUnivList(uinfo, html)
printUnivList(uinfo, 44)
if name == 'main':
main()
`
这段代码主要实现了从一个网页抓取大学排名信息并打印的功能。
-
导入所需的库:
import requests
from bs4 import BeautifulSoup
requests库用于发送HTTP请求,BeautifulSoup`库用于解析HTML。 -
定义获取HTML文本的函数:
getHTMLText(url)函数,该函数发送一个HTTP请求到指定的URL,如果请求成功,返回响应的文本内容;如果请求失败,打印错误信息并返回None。 -
定义填充大学列表的函数:
fillUnivList(ulist, html):该函数解析HTML文本,找到包含大学排名信息的表格,遍历表格的每一行,将大学排名、名称、省份、类型和总分等信息提取出来,添加到ulist列表中。 -
定义打印大学列表的函数:
printUnivList(ulist, num),该函数定义了一个打印大学信息的格式,然后遍历ulist列表,按照格式打印每个大学的信息,一共44条
如下图:


*心得
实验一考验了用requests和BeautifulSoup库方法定向爬取给定网址,在熟悉方法的同时还让我熟悉查找网页信息标签的方法,由于没有翻页能力只能爬取30个,有待提高
作业2-爬取商品书包信息
*实验内容:
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格
这里由于淘宝等网页反爬机制,选择当当网进行爬取,代码如下:
`
import requests
from bs4 import BeautifulSoup
url = 'http://search.dangdang.com/?key=����&act=input'
response = requests.get(url)
data = response.text
soup = BeautifulSoup(data, 'lxml')
tags = soup.find_all('p', attrs={'name': 'title'})
count = 1
for tag in tags:
if tag.a and count <= 44:
print(str(count) + '. ' + tag.a.attrs['title'])
print("\t" + tag.previous_sibling.span.text if tag.previous_sibling else '')
count += 1
`
这段代码主要是用于从网页中提取并打印书包商品的价格名称信息
-
导入所需的库:
import requests
from bs4 import BeautifulSoup
requests库用于发送HTTP请求,BeautifulSoup`库用于解析HTML
这里由于我个人技术力不足,不会使用re库 -
发送HTTP请求并获取HTML文本:
response = requests.get(url)
data = response.text
这段代码发送一个HTTP请求到指定的URL,并将响应的文本内容存储在data变量中。 -
使用
BeautifulSoup解析HTML:
soup = BeautifulSoup(data, 'lxml')
这段代码将HTML文本解析为BeautifulSoup对象,以便于提取其中的信息。 -
查找并提取所需的标签:
tags = soup.find_all('p', attrs={'name': 'title'})
这段代码查找所有<p>标签,只要它们的name属性为'title'。结果存储在tags变量中。 -
遍历找到的标签并打印信息:
count = 1 for tag in tags: if tag.a and count <= 44: print(str(count) + '. ' + tag.a.attrs['title']) print("\t" + tag.previous_sibling.span.text if tag.previous_sibling else '') count += 1
这段代码遍历找到的所有<p>标签。对于每个标签,如果它有一个<a>子标签,并且计数器小于等于44,就打印出标签的标题(<a>的title属性)以及可能在其之前的一个<span>标签的文本内容。最后,计数器增加1。
其运行结果如下:
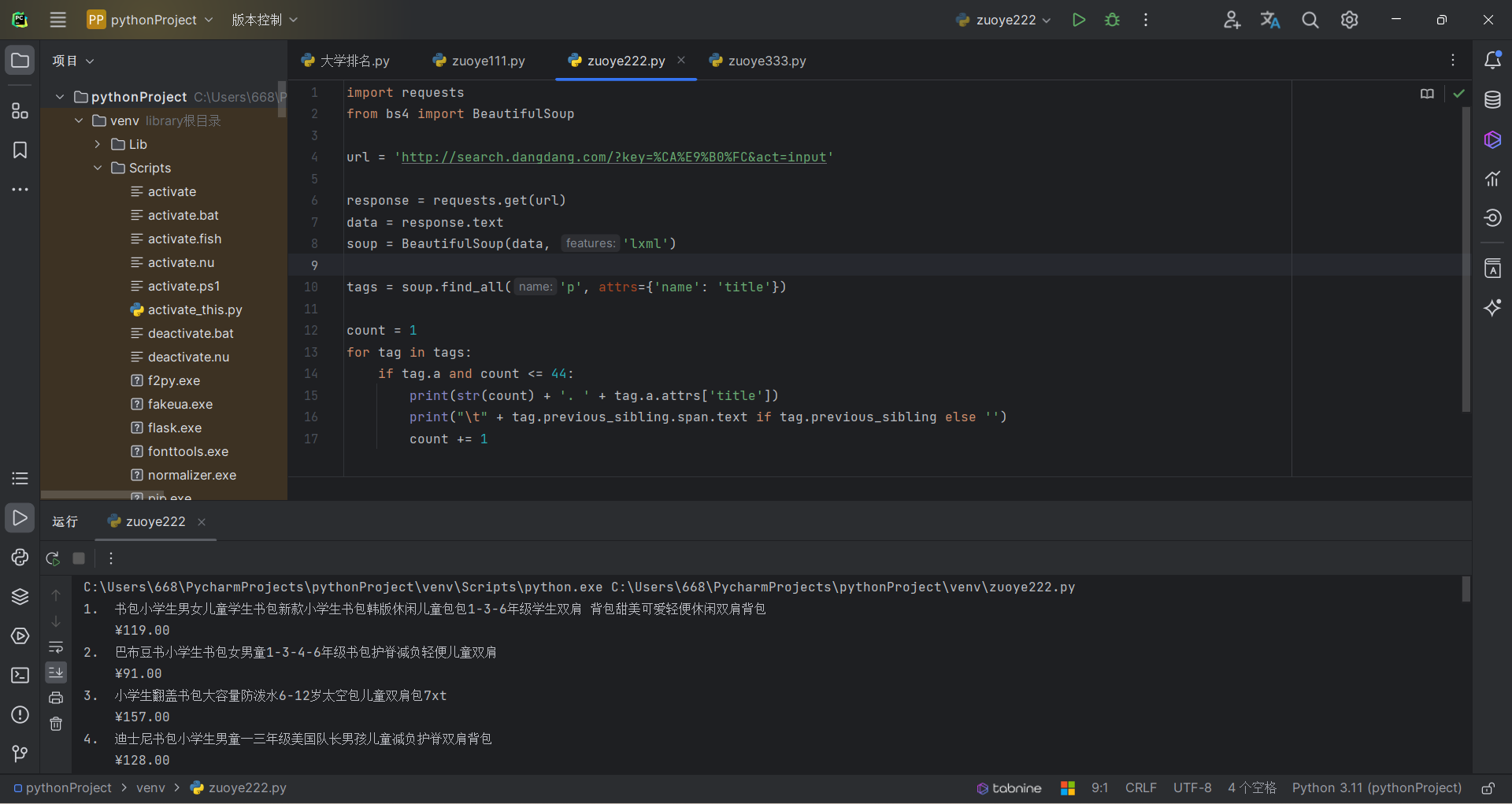

*心得
这里由于我个人技术力不足,不会使用re库,也不善于使用正则表达式,所以用别的方法代替了,以后一定多加学习,以及对商品信息标签的查找熟悉
作业3-下载图片文件
*实验内容
爬取一个给定网页的所有JPEG和JPG格式文件,将自选网页内的所有JPEG和JPG文件保存在一个文件夹中,完整代码如下:
`
import os
import requests
from bs4 import BeautifulSoup
url = 'https://xcb.fzu.edu.cn/info/1071/4481.htm'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
img_list = soup.select("p[class='vsbcontent_img'] img")
for img in img_list:
img_url = img.attrs['src']
img_url = 'https://xcb.fzu.edu.cn{}'.format(img_url)
response = requests.get(img_url, headers=headers)
img_content = response.content
filename = os.path.basename(img_url).split('?')[0]
imgPath = './' + filename
with open(imgPath, 'wb') as fp:
fp.write(img_content)
print(filename, '下载成功!!!')
`
这段代码的主要功能是下载一个网页上的所有图片。以下是详细的分析:
-
导入所需的库:
import os
import requests
from bs4 import BeautifulSoup
os库用于与文件系统进行交互,requests库用于发送HTTP请求,BeautifulSoup库用于解析HTML。 -
定义URL和 headers:
url变量存储了要下载图片的网页的URL。headers字典定义了一个User-Agent头,用于伪装成浏览器发送HTTP请求。 -
获取HTML文本并解析:
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
这段代码发送一个HTTP请求到指定的URL,获取响应的文本内容,并将其解析为BeautifulSoup对象。 -
找到所有图片标签:
img_list on= soup.select("p[class='vsbcontent_img'] img")
这段代码使用BeautifulSoup的select方法找到所有具有vsbcontent_img类的<p>标签内的<img>标签。结果存储在img_list变量中。 -
下载并保存图片:
`
for img in img_list:
img_url = img.attrs['src']
img_url = '***{}'.format(img_url)response = requests.get(img_url, headers=headers)
img_content = response.contentfilename = os.path.basename(img_url).split('?')[0]
imgPath = './' + filenamewith open(imgPath, 'wb') as fp:
fp.write(img_content)
print(filename, '下载成功!!!')
这段代码遍历找到的所有标签,获取它们的src属性(图片的URL),然后下载图片并保存到本地文件。注意,图片URL可能相对,所以代码中将其转换为绝对URL。下载完成后,使用print`函数输出下载成功的消息,结果保存在当前文件夹下,结果如下:


*心得
对图片类文件的下载处理有了基本方法
总结
经过了第一次作业后,对爬虫已经有了一个初步的认识,对网页的html信息有一定的了解,尝试去使用爬虫以及相关的库,但是需要学习的东西还有很多,本次作业有很多做不出来的地方需要加深学习

