浅析scrapy与scrapy_redis区别
最近在工作中写了很多 scrapy_redis 分布式爬虫,但是回想 scrapy 与 scrapy_redis 两者区别的时候,竟然,思维只是局限在了应用方面,于是乎,搜索了很多相关文章介绍,这才搞懂内部实现的原理。
首先我们从整体上来讲
scrapy是一个Python爬虫框架,爬取效率极高,具有高度定制性,但是不支持分布式。而scrapy-redis一套基于redis数据库、运行在scrapy框架之上的组件,可以让scrapy支持分布式策略,Slaver端共享Master端redis数据库里的item队列、请求队列和请求指纹集合。而为什么选择redis数据库,是因为redis支持主从同步,而且数据都是缓存在内存中的,所以基于redis的分布式爬虫,对请求和数据的高频读取效率非常高。
有一篇文章是这么说的:scrapy-redis 与 Scrapy的关系就像电脑与固态硬盘一样,是电脑中的一个插件,能让电脑更快的运行。
Scrapy 是一个爬虫框架,scrapy-redis 则是这个框架上可以选择的插件,它可以让爬虫跑的更快。
说的一点都对,Scrapy 是一个通用的爬虫框架,scrapy-redis 则是这个框架上可以选择的插件,为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件),它可以让爬虫跑的更快。
然后介绍 scrapy 框架的运行流程及原理
scrapy作为一款优秀的爬虫框架,在爬虫方面有这众多的优点。能快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
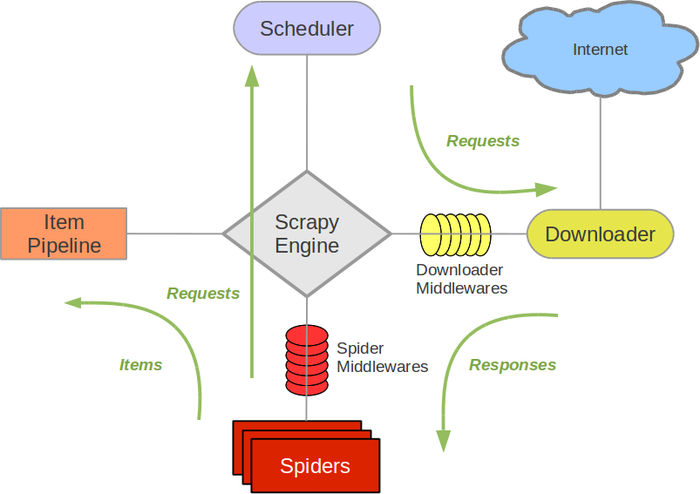
为了方便理解,我找到了一张这样的图片:
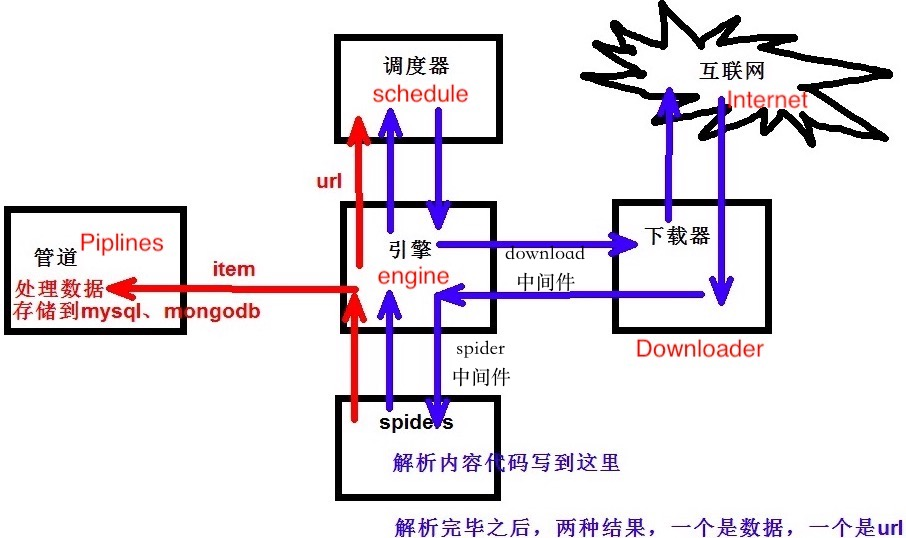
解释说明:
1、从优先级队列中获取request对象,交给engine
2、engine将request对象交给下载器下载,期间会通过downloadmiddleware的process_request方法
3、下载器完成下载,获得response对象,将该对象交给engine,期间会经过downloadmiddleware的process_response( )方法
4、engine将获得的response对象交给spider进行解析,期间会经过spidermiddleware的process_spider_input()的方法
5、spider解析下载器下下来的response,返回item或是links(url)
6、item或者link经过spidermiddleware的process_spider_out( )方法,交给engine
7、engine将item交给item pipeline ,将links交给调度器
8、在调度器中,先将requests对象利用scrapy内置的指纹函数生成一个指纹
9、如果requests对象中的don't filter参数设置为False,并且该requests对象的指纹不在信息指纹的队列中,那么就把该request对象放到优先级队列中
循环以上操作
中间件主要存在两个地方,从图片当中我们可以看到:
spider 与 engine 之间(爬虫中间件):
介于Scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出
download 与 engine 之间(下载器中间件) :
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应
借此机会,我们结合程序,解析一下框架中的 middleware.py :
1. Spider Middleware有以下几个函数被管理:
- process_spider_input 接收一个response对象并处理,
位置是Downloader-->process_spider_input-->Spiders(Downloader和Spiders是scrapy官方结构图中的组件)
- process_spider_exception spider出现的异常时被调用
- process_spider_output 当Spider处理response返回result时,该方法被调用
- process_start_requests 当spider发出请求时,被调用
2. Downloader Middleware有以下几个函数被管理
- process_request request通过下载中间件时,该方法被调用,这里可以设置代理,设置request.meta['proxy'] 就行
- process_response 下载结果经过中间件时被此方法处理
- process_exception 下载过程中出现异常时被调用
个人理解scrapy的优缺点:
优点:scrapy 是异步的,写middleware,方便写一些统一的过滤器
缺点:基于python的爬虫框架,扩展性比较差,基于twisted框架,运行中的exception是不会干掉reactor,并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉。
scrapy_redis分布式爬虫
最后回到我们这篇文章的重点(敲黑板...)
Scrapy-redis提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
Scheduler:
Scrapy改造了python本来的collection.deque(双向队列)形成了自己的Scrapy queue,但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),从同一个redis-server存放要爬取的request,便能让多个spider去同一个数据库里读取。
Scrapy中跟“待爬队列”直接相关的就是调度器Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。它把待爬队列按照优先级建立了一个字典结构,然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。为了管理这个比较高级的队列字典,Scheduler需要提供一系列的方法。但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。
Duplication Filter:
Scrapy中用集合实现这个request去重功能,Scrapy中把已经发送的request指纹放入到一个集合中,把下一个request的指纹拿到集合中比对,如果该指纹存在于集合中,说明这个request发送过了,如果没有则继续操作。
在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。
引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
Item Pipeline:
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现items processes集群。
Base Spider:
不在使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
Scrapy-redis架构:
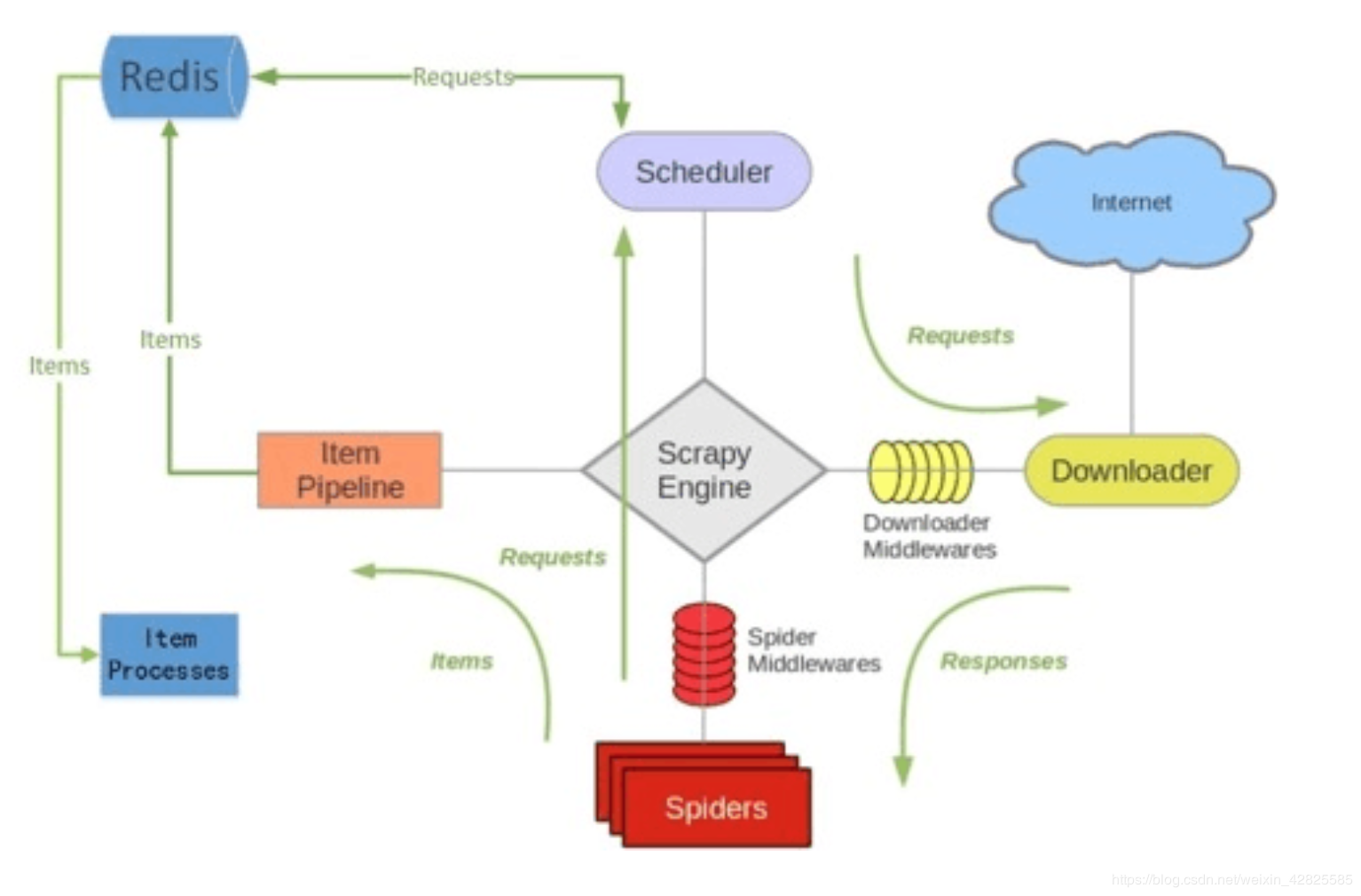
如上图所示,我们可以发现,scrapy-redis在scrapy的架构上增加了redis,与scrapy相差无几。本质的区别就是,将scrapy的内置的去重的队列和待抓取的request队列换成了redis的集合。就这一个小小的改动,就使得了scrapy-redis支持了分布式抓取。
Scrapy-Redis分布式策略:
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
--Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
--Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master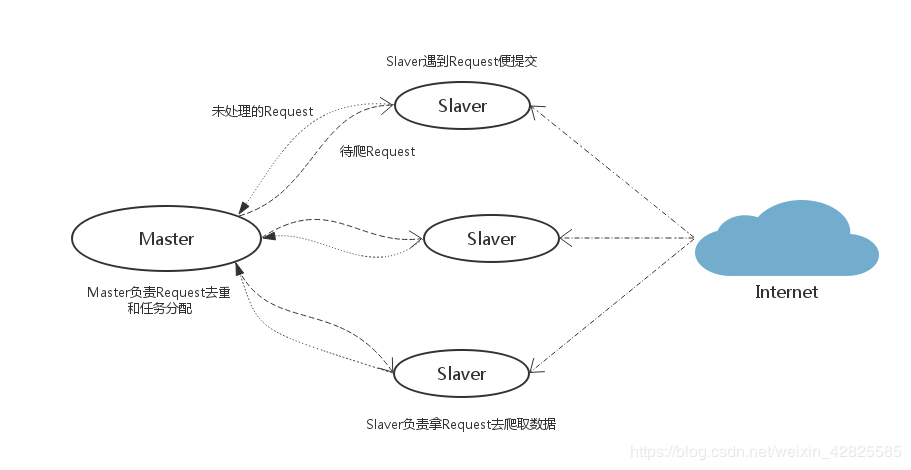
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
明白了原理之后我们就要入手程序了
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
将 scrapy 变成 scrapy-redis 的过程(前提是pip install scrapy-redis)
1、修改settings.py文件,最简单的方式是使用redis替换机器内存,你只需要在 settings.py 中加上三代码,就能让你的爬虫变为分布式。

2、配置redis

3、配置如下参数

4、自定义爬虫类继承RedisSpider

如果你现在运行你的爬虫,你可以在redis中看到出现了这两个key:

格式是set,即不会有重复数据。前者就是redis的去重队列,对应DUPEFILTER_CLASS,后者是redis的请求调度,把里面的请求分发给爬虫,对应SCHEDULER。(里面的数据不会自动删除,如果你第二次跑,需要提前清空里面的数据)
备注:
虽然scrapy_redis 可以极大的提高爬虫的运行的效率,但也是存在缺点的,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。最后提醒一下大家,并不是所有的网站都可以采用分布式爬虫进行采集,爬虫要追求灵活,所以scrapy-redis并不能代替传统的request爬虫。
部分文字来自:https://blog.csdn.net/weixin_42825585/article/details/88046328
