Group BY
一,GROUP BY 执行理解
先来看下表1,表名为test:
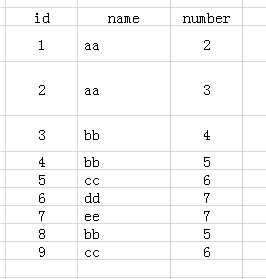
表1
执行如下SQL语句:
SELECT name from test GROUP BY name ;
你应该很容易知道运行的结果,没错,就是下表2:

表2
可是为了能够更好的理解“group by”多个列“和”聚合函数“的应用,我建议在思考的过程中,由表1到表2的过程中,增加一个虚构的中间表:虚拟表3。下面说说如何来思考上面SQL语句执行情况:
1.FROM test:该句执行后,应该结果和表1一样,就是原来的表。
2.FROM test Group BY name:该句执行后,我们想象生成了虚拟表3,如下所图所示,生成过程是这样的:group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>与<2 aa 3>两行合并成1行,所有的id值和number值写到一个单元格里面。
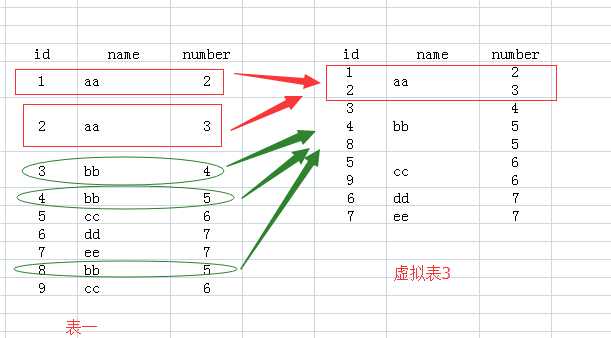
3.接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该是虚拟表3,可是id和number中有的单元格里面的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以你看,执行select * 语句就报错了。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有问题了。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)那么对于id和number里面的单元格有多个数据的情况怎么办呢?答案就是用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如cout(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
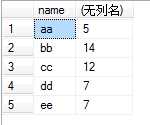
(4)例如我们执行select name,sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3,返回5,最后执行结果如下:
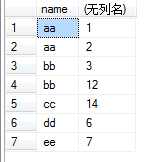
(5)group by 多个字段该怎么理解呢:如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。如下图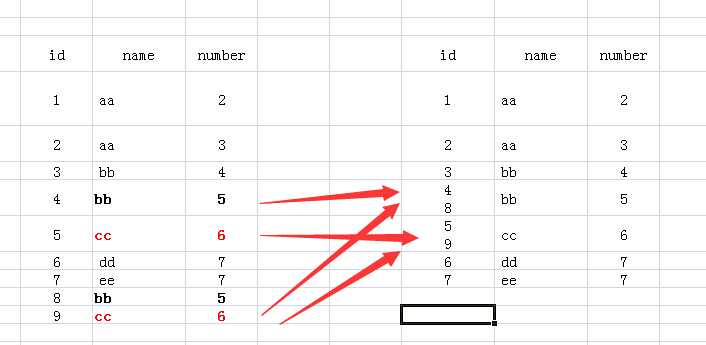
(6)接下来就可以配合select和聚合函数进行操作了。如执行select name,sum(id) from test group by name,number,结果如下图:
二 ,GROUP BY 与 DISTINCT 去重比较
GROUP BY 与 DISTINCT都有去重的功能,具体例子如下:
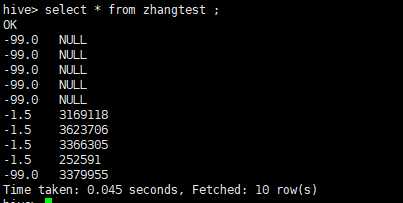
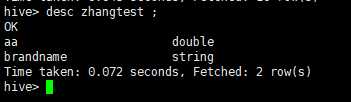
SELECT aa from zhangtest WHERE aa is not NULL GROUP BY aa ;
如果在select 中加入其它字段 ,而在GROUP BY中没有,则会报错,如下。

select col1,col2,count(1),sel_expr(聚合操作) from tableName where condition group by col1,col2 having...
注意:
(1):select后面的非聚合列必须出现在group by中(如上面的col1和col2)。
(2):除了普通列就是一些聚合操作。
group的特性:
(1):使用了reduce操作,受限于reduce数量,通过参数mapred.reduce.tasks设置reduce个数。
(2):输出文件个数与reduce数量相同,文件大小与reduce处理的数量有关。
问题:
(1):网络负载过重。
(2):出现数据倾斜(我们可以通过hive.groupby.skewindata参数来优化数据倾斜的问题)。
下面,看下hive group by distinct区别以及性能比较
有兴趣的可以看下这篇博文,讲解的比较清楚。
https://blog.csdn.net/xiaoshunzi111/article/details/68484426
结论:能用GROUP BY 的 不用 DISTINCT。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号